










文章目录
一、拆分与合并的目的
1.拆分
- 当一个Region大到一定程度,或导致读取效率太低,所以会进行分裂
- HBase可以通过Region Split达到负载均衡
- Region的拆分分为自动拆分与手动拆分
2.合并
- 当删除了大量的数据后,每一个Region都变小了,这时候再分多个Region就太浪费空间,可以将这些Region合并起来
- 合并的主要目的不是为了性能考虑,而是出于维护的目的
二、Region拆分
1.自动拆分
- 在0.94版本之前,使用的拆分策略是.ConstantSizeRegionSplitPolicy,按照固定大小来拆分Region,即当Region的大小超过默认值(通常默认值是10G),Region就会被HBase拆分成两个Region,且是平均分配。
- 0.94版本之后,用到的拆分策略是 IncreasingToUpperBoundRegionSplitPolicy,即这种拆分方法是会随着Region个数变化而变化,比较灵活,具体的计算方法如下:
Math.min(tableRegionCounts ^3 * initalSize,defaultRegionMaxFileSize)
- tableRegionCounts:表在RegionServer上所有Region的总和
- initalSize:如果没有重新定义hbase.increasing.policy.initial.size,它的大小就是Memstore的2倍,也就是128*2M
- defaultRegionMaxFileSize:Region的最大大小,默认是10G
通过计算可以得出,当Region的个数分别为1,2,3时,文件大小的上限分别为256M,2G,6912M。当Region个数大于等于4个,文件大小已经超出10G,所以上限只能是10G
2.手动拆分
(1).Linux命令行创建
hbase org.apache.hadoop.hbase.util.RegionSplitter my_split_table2 HexStringSplit -c 5 -f mycf
org.apache.hadoop.hbase.util.RegionSplitter——调用的一个切分Region类
my_split_table2——表名
HexStringSplit——拆分点算法,这里采用16进制
-c ——Region的个数
-f ——列族名
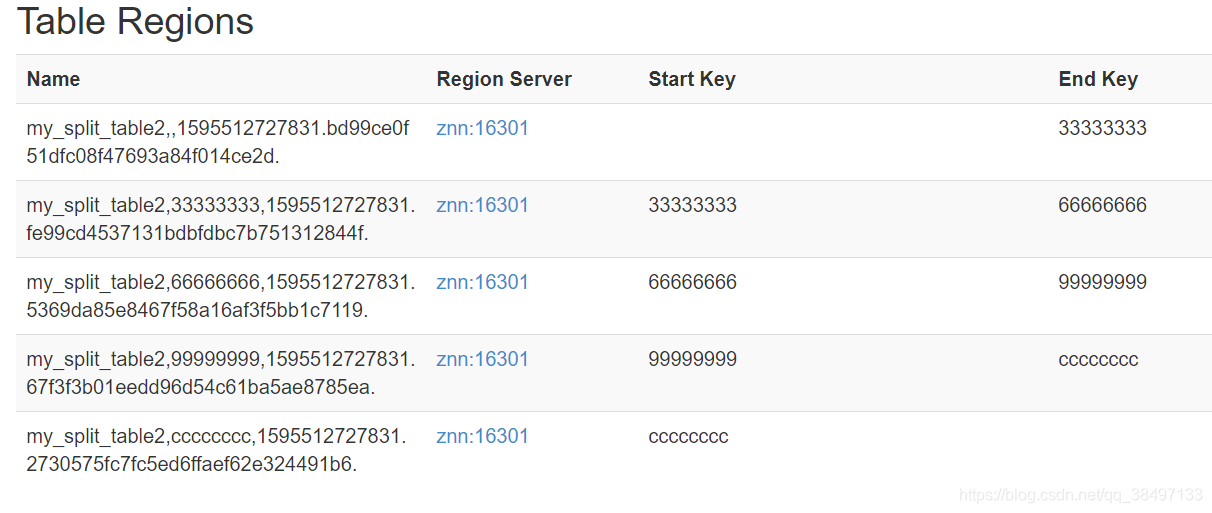
执行完成后可以进入HBase中查看是否创建成功
然后登陆网页能够更直观的看到自己切分的Region:localhost:60010——localhost要用自己的ip地址
(2).在HBase命令行里创建
hbase(main):009:0> create 'split2','mycf2',SPLITS=>['aa','bb','cc','dd','ee','ff','zz']
0 row(s) in 2.2930 seconds
=> Hbase::Table - split2
同样也可以登陆网页查看切分是否成功。
(3).指定拆分文件
首先编辑一个拆分文件student.txt,如下图,每一行不能有重复
aa
bb
ff
ag
sd
dd
gg
~
在HBase命令行开始创建表:
hbase(main):012:0> create 'stu','info',SPLITS_FILE=>'/root/datas/student/student.txt'
0 row(s) in 2.2610 seconds
=> Hbase::Table - stu
hbase(main):013:0>
只需要指定拆分文件即可。
(4).强制拆分
以上三种拆分方式也叫做Region的预拆分。下面这种属于对Region的强制拆分。

上图是之前做的一个Region通过HBase命令行进行拆分
split2,bb,1595513677802.c798b2717d6d7006bd67ad4e6197ed43.
split2——表名
bb——起始key
1595513677802——终止key
c798b2717d6d7006bd67ad4e6197ed43——终止key的id
现在可以根据这个id在bb和cc之间在强制拆分一个Region
HBase命令行输入命令:
hbase(main):014:0> split 'c798b2717d6d7006bd67ad4e6197ed43','c'
0 row(s) in 0.0450 seconds
就可以发现bb和ccRegion之间又强制被拆分一个Region
PS:因为Region的排序是按照字典顺序排序的,所以在强制拆分的时候,要注意Region名的大小

三、Region合并
1.Minor Compaction
- 将一部分小文件合并成更少的大型文件,通过事件触发,合并速度较快;合并的时候不会真正的删除,只是打个标记
- hbase.hregion.memstore.flush.size 缓存阈值大小 在hbase-site.xml文件中可以设置,默认是128M
- hbase.hstore.compaction.max :每次compact的HFile的最大数目,默认是10
- hbase.hstore.compaction.kv.max:compact时批量读取和写入KeyValue数据的数量,默认是10
2.Major Compaction
- 将一个HStore中的所有文件合并成一个文件,通过时间触发,合并速度慢,同时还会删除合并之前的小文件,因此十分消耗性能,一般会将自动合并关掉。
- hbase.hregion.majorcompaction 时间间隔,默认是7天
3.三种触发合并检查的情况
- MemStore被刷写到磁盘
- 执行shell命令compact,major_compaction或者调用相应API
- HBase后台线程周期性触发检查
4.合并操作
#compact一个表的所有regions
compact 't1'
#compact某个空闲的region
compact 'r1'
#compact一个region中的某个列族
compact 'r1', 'c1'
#compact一个表中的某个列族
compact 't1', 'c1'














 2329
2329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









