







目的:爬取照片用主播名进行重命名
url:http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=0
(一)基本步骤
步骤大致如下:
创建项目:scrapy startproject Douyu
创建爬虫文件:scrapy genspider douyu “douyucdn.cn”
编写items.py: 写主要爬取的数据名称,照片名,照片网址
编写管道pipelines.py:将items.py中的item处理,然后返给下载器下载
注意:piplines.py中有自带的images类
(二)编写代码:

-
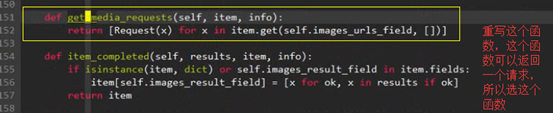
管道中有自带的images函数,images函数中有ImagesPipeline类
-
发送完请求后默认都去settings函数中IMAGES_STORE=路径存储照片

-
Windows下的目录要这样写,还添加了模拟手机的user-agent

-
取出图片名-----源码中有个item_completed函数

- 参数result中输出:[(True, {‘url’: ‘https://rpic.douyucdn.cn/live-cover/appCovers/2018/12/09/5983902_20181209014248_big.jpg’, ‘path’: ‘full/ff4068ab102cc3840975e21c27db4f40881bcf93.jpg’, ‘checksum’: ‘39696646529e3d1cf89beb908c99e958’})]
- 解析:其中result参数输出的是一个列表,列表中只含有一个元组,元祖中含有两个元素,一个是true,一个是字典类型,字典类型数据含有url和照片存储路径,checksum是md5值
- 因此只要提取出path值就可以将文件重命名。
-
重命名
(三)完整代码
项目包含文件如下:

import scrapy
class DouyuItem(scrapy.Item):
# define the fields for your item here like:
image_name = scrapy.Field()
image_link = scrapy.Field()
# -*- coding: utf-8 -*-
import scrapy
import json
from Douyu.items import DouyuItem
import scrapy
class DouyuSpider(scrapy.Spider):
name = 'douyu'
allowed_domains = ['douyucdn.cn']
# start_urls = ['http://douyucdn.cn/']
#每页翻20张照片
baseURL = "http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset="
offset = 0
start_urls = [baseURL + str(offset)]
#解析网页
def parse(self, response):
#将json文件转化成列表 取出键值为data的数据,data中存放的是列表,列表中又存放的字典
data_list = json.loads(response.body)['data']
if len(data_list) == 0:
return
for data in data_list:
item = DouyuItem()
item['image_name'] = data['nickname']
item['image_link'] = data['vertical_src']
yield item
# print(data['nickname'])
# print(data['vertical_src'])
# print('*'*40)
#回调其他网页
self.offset += 20
yield scrapy.Request(self.baseURL + str(self.offset), callback=self.parse)
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
import os
from scrapy.pipelines.images import ImagesPipeline
from Douyu.settings import IMAGES_STORE as images_store
class DouyuPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
image_link = item['image_link']
yield scrapy.Request(image_link)
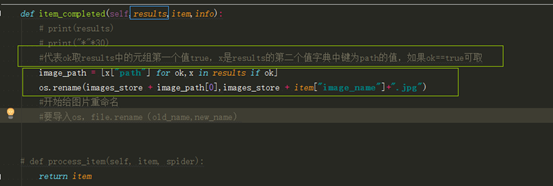
def item_completed(self,results,item,info):
# print(results)
# print("*"*30)
#代表ok取results中的元组第一个值true,x是results的第二个值字典中键为path的值,如果ok==true可取
image_path = [x["path"] for ok,x in results if ok]
os.rename(images_store + image_path[0],images_store + item["image_name"]+".jpg")
#开始给图片重命名
#要导入os,file.rename(old_name,new_name)
# def process_item(self, item, spider):
return item
IMAGES_STORE = "C:\\Users\\Administrator\\Desktop\\TensorFlowStudy\\爬虫\\Douyu\\Image\\"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (iPhone; U; CPU iPhone OS 2_0 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5A347 Safari/52',
ITEM_PIPELINES = {
'Douyu.pipelines.DouyuPipeline': 300,
}
结果:
致谢:
感谢传智播客彭亮老师的讲解
感谢菜鸟教程scrapy入门的教程
排版
排版不好请谅解,因为边听课边记有道笔记,所以大部分都是直接截图














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}