







scrapy -engine
1.engine.py
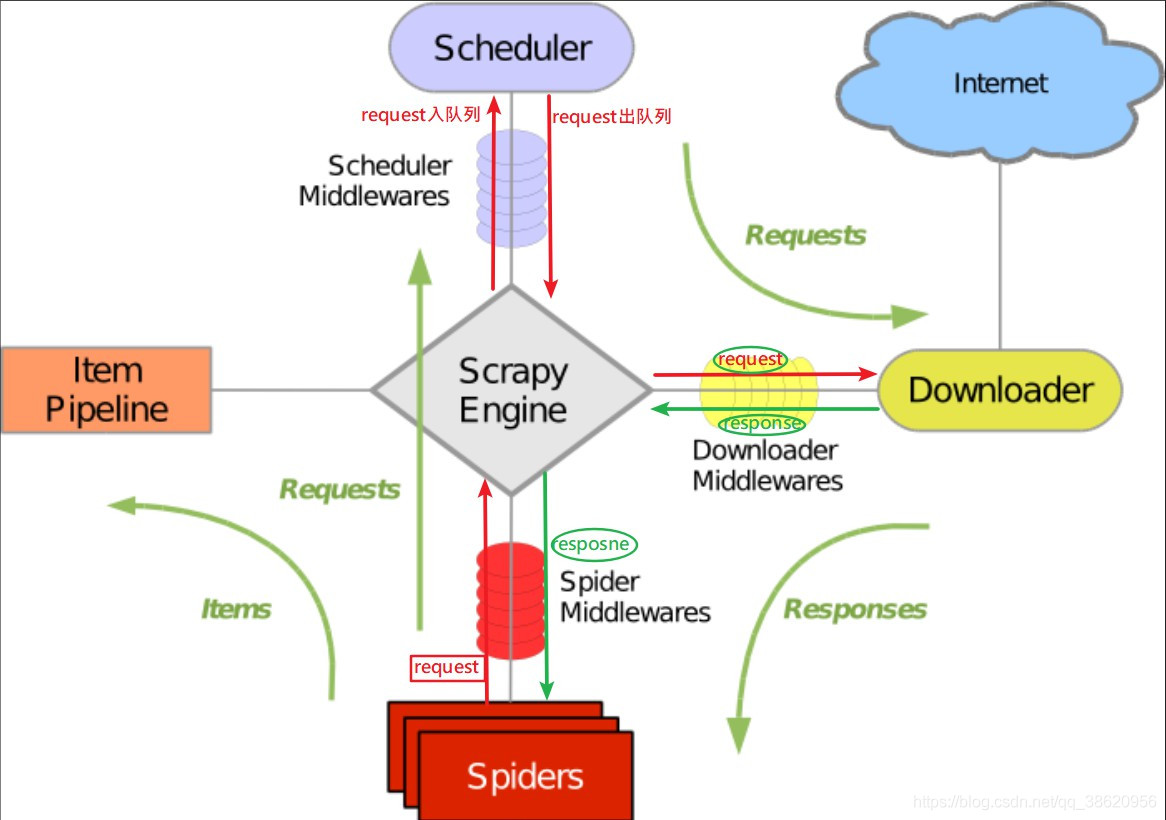
# 调度四个模块
def _start(self):
request = self.spider.start_request() spider把起始url得到的request 交给 engine
request = self.spider_mid.process_request(request) 爬虫中间件:在spider交给 engine之前 做事情 *******
self.scheduler.add_request(request) engine把request 交给 调度器 入队列
request = self.scheduler.get_request() 调度器出队列 又交给 engine
request = self.down_mid.process_request(request) 下载中间件:engine 把request交给下载器之前做事情 *******
response = self.downloader.get_response(request) engine 把 request 交给下载器之后得到的响应对象
response = self.down_mid.process_response(response) 下载中间件:下载器把response交给engine 之前替换新的 *******
response = self.spider_mid.process_response(response) 爬虫中间件:engine把response交给spider之前做事情 *******
result = self.spider.parse(response) spider拿到的响应对象处理解析
if isinstance(result, Request): engine 把解析结果中的url request判断出来分别给 调度器 和 管道
self.scheduler.add_request(result) 类型是request 交给调度器
else:
self.pipeline.process_item(result) 类型是数据 交给管道 2.调度器的出入队列 queue及去重原理
from six.moves.queue import Queue
class Scheduler(object):
def __init__(self):
self.queue=Queue()
self.filter_container=set()
# 入队列
def add_request(self,request):
if not self.fillter_request(request): #重复
self.queue.put(request)
self.filter_container.add(request.url)
# 出队列
def get_request(self):
try:
return self.queue.get(False)
except Exception as e:
return None
#过滤
def fillter_request(self,request):
if request.url in self.filter_container:
return True
else:
return False2.指纹结合去重
def _creat_fp(self,request):
# 1.排序
url=w3lib.url.canonicalize_url(request.url)
# 2.method大小写
method=request.method.upper()
# 3.params
params=sorted(request.params.items())
data=sorted(request.data.items())
fp_str=url+method+str(params)+str(data)
# 4.生成指纹
fp=hashlib.sha1()
fp.updte(fp_str.encode())
return fp_str.hexdigest()
3.scrapy中构造requests的几个方法
1.yield response.follow(
) 当next_url不全时,自动补全net_url
next_url = response.xpath('//a[@class="pn-next"]/@href').extract_first()
yield response.follow(
next_url,
callback=self.parse_book,
meta={'book': item}
)2.scrapy.Request()
3.中间件中的process_exception
当中间件中的process_exception 捕获到 超时异常 或其他 代理原因时 可使用 process_exception捕获异常
def process_exception(self, request, exception, spider):
# pass
self.logger.debug('捕获到超时异常!!!!!')
self.logger.debug('重试')
request.meta['proxy'] = 'https:60.235.28.165:8088' #更换代理或其他
return request
#在爬虫文件中重写父类 处理捕获到的 异常重新构造一个请求
def make_requests_from_url(self, url):
return scrapy.Request(url=url, meta={'download_timeout': 5}, callback=self.parse)
4.start_requests()和make_requests_from_url()的区别
有start_requests时不会执行另一个 作用: 构造url 为请求对象 url 可以自己指定
make_requests_from_url 构造 start_urls列表中的url 为请求对象
2.from copy import deepcopy
scrapy 中循环嵌套循环时 使用 deepcopy(item)开启一个新的内存空间 使得item中的数据不会被覆盖,
from copy import deepcopy
class JingdSpider(scrapy.Spider):
name = 'jingd'
start_urls = ['https://book.jd.com/booksort.html']
def parse(self, response):
dt_list = response.xpath('//*[@id="booksort"]/div[2]/dl/dt[1]') #
for dt in dt_list:
item = JdongItem()
item['big_name'] = dt.xpath('./a/text()').extract_first()
for em in em_list:
item['small_name'] = em.xpath('./a/text()').extract_first()
yield scrapy.Request(url=small_link, callback=self.parse_book, meta={'book': deepcopy(item)})
#for循环下的item
def parse_book(self, response):
item = response.meta['book']
book_list = response.xpath('//*[@id="plist"]/ul/li[1]') #
for book in book_list:
item['img_url'] = 'https:' + book.xpath
yield scrapy.Request(url=price_url, callback=self.parse_price, meta={'book': deepcopy(item)})
#for 循环下的item
def parse_price(self, response):
item = response.meta['book']
item['book_price'] = loads(response.body.decode())[0]['p']
#没有在循环下
yield item在for 循环下有多个item['***']数据时使用















 9657
9657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









