






赛事任务
目前神经机器翻译技术已经取得了很大的突破,但在特定领域或行业中,由于机器翻译难以保证术语的一致性,导致翻译效果还不够理想。对于术语名词、人名地名等机器翻译不准确的结果,可以通过术语词典进行纠正,避免了混淆或歧义,最大限度提高翻译质量。
数据集
参赛队伍需要基于提供的训练数据样本从多语言机器翻译模型的构建与训练,并基于测试集以及术语词典,提供最终的翻译结果,数据包括:
·训练集:双语数据:中英14万余双语句对
·开发集:英中1000双语句对
·测试集:英中1000双语句对
·术语词典:英中2226条
评价指标
是指针对相同的数据,输入不同算法模型,或者输入不同参数的同一种算法模型,而给出这个算法或者参数好坏的评价指标;在模型评估过程中,往往需要使用多种不同指标进行评估,大部分指标只能片面的反应模型的一部分性能。
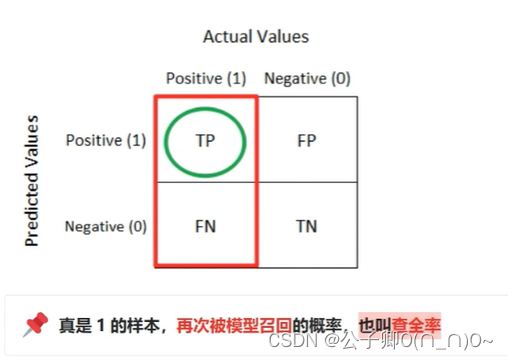
| 真实值(True) | 真实值(False) | |
|---|---|---|
| 预测值(Positive) | 真正例(TP) | 假正例(FP) |
| 预测值(Negative) | 假负例(FN) | 真负例(TN) |
准确率:预测正确的结果占总样本的百分比
问题:样本不平衡时,准确率失效
处理样本不平衡:重采样、欠采样、过采样等等
Precision = TP/TP+FP

召回率:真是1的样本,再次被模型召回的概率,也叫查全率
Recall=TP/(TP+FN)
F1_Score:准确率和召回率的调和平均,因为准确率和召回率是有一定冲突的,衡量二者的综合情况
F1_Score=2*(P*R)/(P+R)

学习方法!!!
跟着项目学,跑4遍代码
1.快速浏览一遍baseline代码,跑通baseline并提交分数;
2.根据注释精读代码,遇到不会的就自己百度相关知识,不用学完所有前置知识,边看边查;
3.灵活运用info()、head()方法调试代码,在每一步数据处理后看看数据是怎么变化的;
4.自己完整敲一遍代码,加深理解;
任务一:跑通baseline
baseline:基线,其概念作为算法提升的一个参照物而存在的,相当于基础模型,可以以此为基准来比较对模型的优化是否有提升
运行环境
在魔搭平台上运行,平台集成了算力、相关环境及jupyter,操作非常友好
使用Python语言,pandas库等
代码
# 主函数
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载术语词典
terminology = load_terminology_dictionary('../dataset/en-zh.dic')
# 加载数据集和模型
dataset = TranslationDataset('../dataset/train.txt',terminology = terminology)
# 定义模型参数
INPUT_DIM = len(dataset.en_vocab)
OUTPUT_DIM = len(dataset.zh_vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
N_LAYERS = 2
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
# 初始化模型
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = Seq2Seq(enc, dec, device).to(device)
# 加载训练好的模型
model.load_state_dict(torch.load('./translation_model_GRU.pth'))
save_dir = '../dataset/submit.txt'
inference(model, dataset, src_file="../dataset/test_en.txt", save_dir = save_dir, terminology = terminology, device = device)
print(f"翻译完成!文件已保存到{save_dir}")
运行结果
思考
第一次跑baseline 0.78分钟,啪的一下!就跑完了
,但是bleu分数为0,很懵,不知道为什么。
第二次修改N=2000,epoch=50试一试结果有什么变化。

jupyter的代码还是显示BLEU=0,但是提交到平台有结果了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









