







网站内容爬取与回答问题
Apify概述
Apify是一个网络抓取和数据提取的云平台,它提供了一个由一千多个现成的应用程序组成的生态系统,这些应用程序被称为Actors,用于各种网络抓取、爬行和数据提取用例。
数据集通常用于保存actor的结果:Actor应用程序对目标网站进行深度抓取,然后将网页的文本内容存储到数据集中
使用网站内容爬虫Actor,它可以深度爬取文档、知识库、帮助中心或博客等网站,并从网页中提取文本内容。然后将文档输入向量索引并回答其中的问题。
官网:https://apify.com/
文档:https://docs.apify.com/platform
爬取网站内容
爬取网站内容有2种方式,这里直接在Apify控制台执行爬取
点击Store菜单栏,然后搜索Actor名称,如:website-content-crawler

配置Start URLs,即配置爬取网站地址,这里配置https://www.runoob.com/
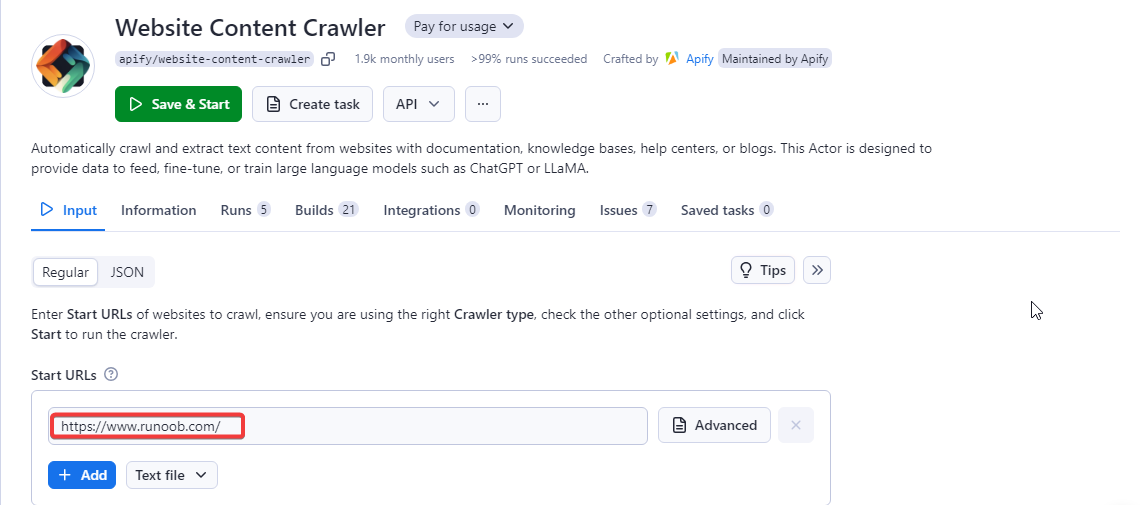
还可以对爬取、处理、输出、运行等参数配置
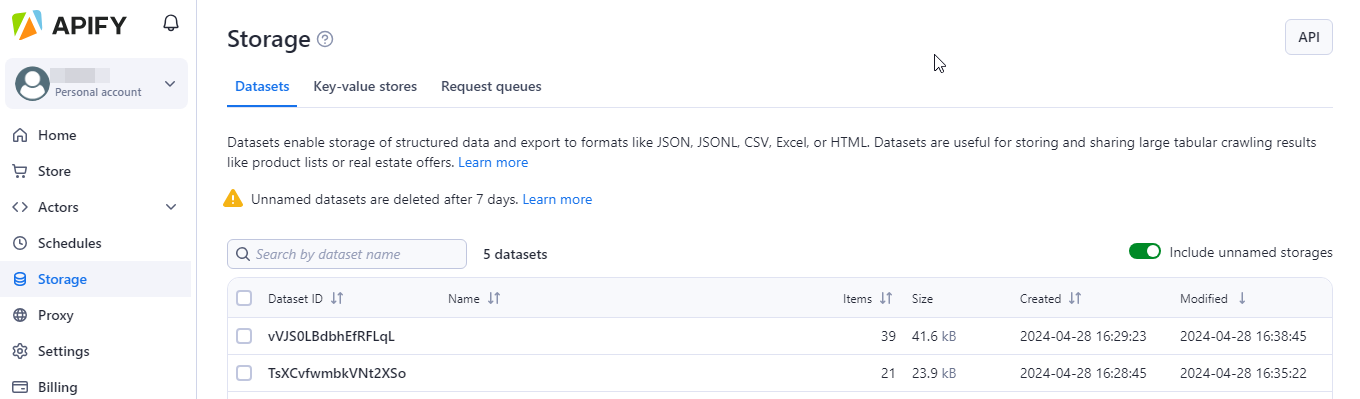
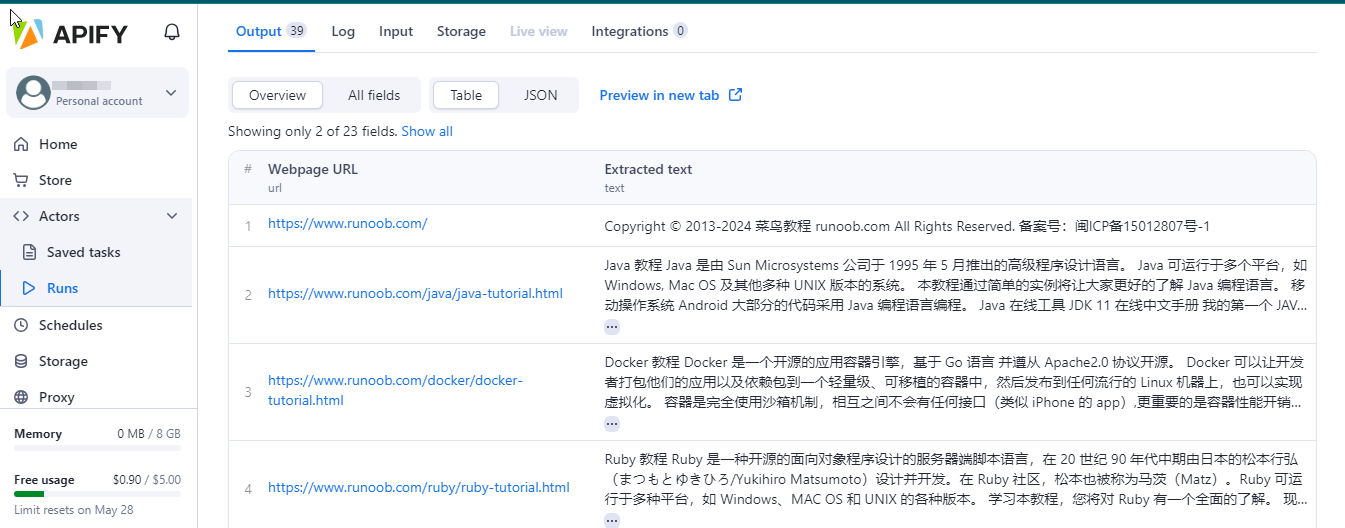
点击Save & Start,等待执行完毕,可以点击Storage菜单栏查看爬取结果
环境准备
安装Apify库
pip install apify-client
查看Apify API令牌并设置到环境变量中
os.environ["APIFY_API_TOKEN"] = 'apify_api_1xxxxxx5LB9'
设置OpenAI的BASE_URL、API_Key
os.environ["OPENAI_BASE_URL"] = "https://xxx.com/v1"
os.environ["OPENAI_API_KEY"] = "sk-BGFnOL9Q4c99B378B66xxxxxx39b4813bc437B82c2"
Apify与LangChain集成
爬取网站内容有2种方式,这里通过Apify与LangChain集成,然后执行爬取
运行Actor,等待其完成,然后将其结果从Apify数据集提取到LangChain文档加载器中。
注意:Actor调用函数从爬取网站加载数据需要一些时间
# 向量存储:使用 Chroma 客户端进行初始化
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.docstore.document import Document
from langchain_community.utilities import ApifyWrapper
apify = ApifyWrapper()
# 调用 Actor 以从已爬网的网页中获取文本
# 在 Apify 平台上运行 Actor 并等待结果准备就绪
loader = apify.call_actor(
actor_id="apify/website-content-crawler",
run_input={"startUrls": [{"url": "https://www.runoob.com/"}]},
dataset_mapping_function=lambda item: Document(
page_content=item["text"] or "", metadata={"source": item["url"]}
),
)
# 从爬取的文档初始化向量索引
index = VectorstoreIndexCreator().from_loaders([loader])
# 查询向量索引
query = "菜鸟教程有那些分类?"
result = index.query_with_sources(query)
print(result["answer"])
print(result["sources"])
执行时间过长,这里终止了,但从运行日志可以看见爬取的网站内容数据
使用Apify数据集
可以从Storage菜单栏处,找到运行Actor的Apify数据集,根据需要找到对应数据集ID。
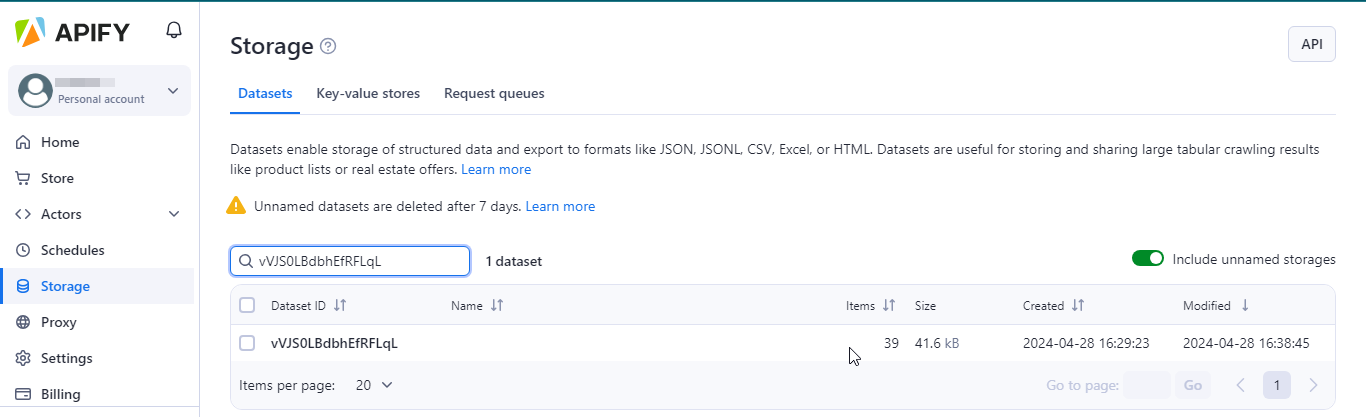
如果在Apify数据集中已有一些结果,则可以使用直接加载它们
# 向量存储:使用 Chroma 客户端进行初始化
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.docstore.document import Document
from langchain_community.utilities import ApifyWrapper
from langchain_community.document_loaders.apify_dataset import ApifyDatasetLoader
apify = ApifyWrapper()
# 调用 Actor 以从已爬网的网页中获取文本
loader = ApifyDatasetLoader(
dataset_id="vVJS0LBdbhEfRFLqL",
dataset_mapping_function=lambda dataset_item: Document(
page_content=dataset_item["text"], metadata={"source": dataset_item["url"]}
),
)
# 基于已爬网数据创建矢量存储
index = VectorstoreIndexCreator().from_loaders([loader])
# 查询向量索引
query = "菜鸟教程有那些分类?"
result = index.query_with_sources(query)
print(result["answer"])
print(result["sources"])
执行结果如下:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











