







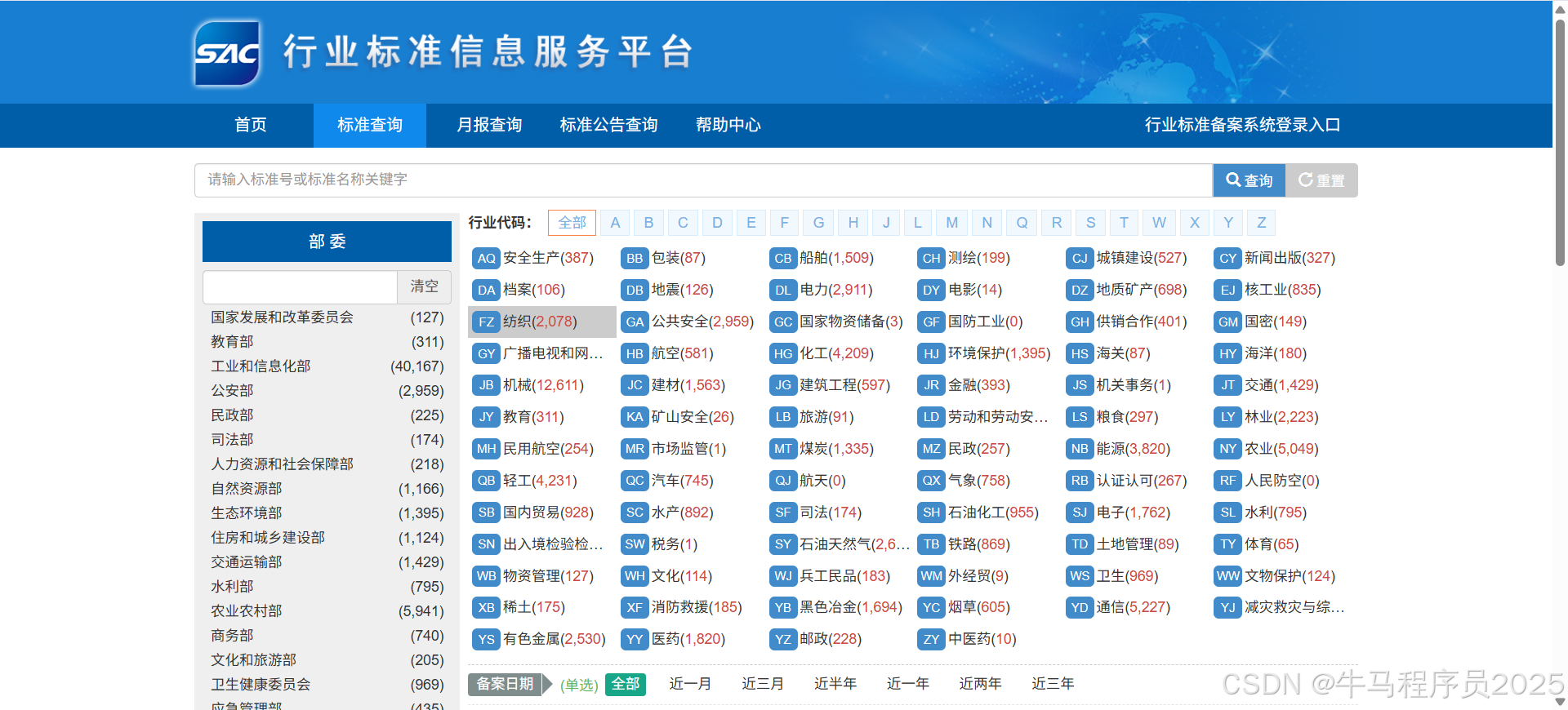
https://hbba.sacinfo.org.cn/stdList
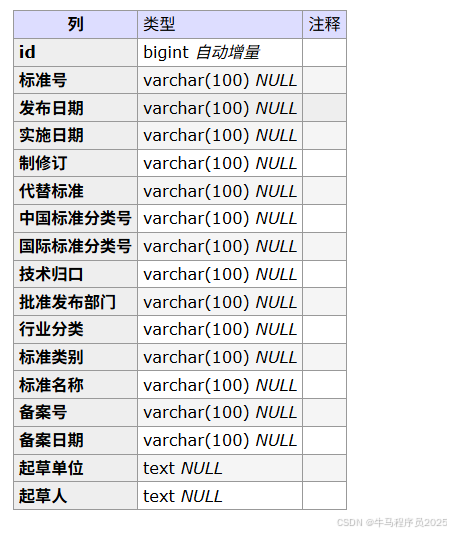
数据库结构:
数据集链接:https://download.csdn.net/download/weixin_55010563/90878886
采集代码部分示例:
import random import time import threading from loguru import logger as log import requests from DrissionPage import SessionPage from concurrent.futures import ThreadPoolExecutor import concurrent.futures from feapder.db.mysqldb import MysqlDB # 数据库配置 db = MysqlDB( ip='', user_name='', user_pass='', db='spider', port=, charset='utf8mb4' ) # 代理API配置 PROXY_API_URLS = [ "代理ip接口" ] class ProxyPool: """代理池管理类(修复frozenset错误版本)""" def __init__(self): self.proxy_pool = [] # 改为列表存储代理字典 self.lock = threading.Lock() self.blacklist = set() self.last_refresh_time = 0 def add_proxy(self, proxy): """添加代理到代理池""" if not proxy or not isinstance(proxy, dict): return False proxy_str = f"{proxy.get('http', '')}|{proxy.get('https', '')}" if proxy_str in self.blacklist: return False with self.lock: # 检查是否已存在相同代理 existing = [p for p in self.proxy_pool if p.get('http') == proxy.get('http') and p.get('https') == proxy.get('https')] if not existing and self._test_proxy(proxy): self.proxy_pool.append(proxy.copy()) # 存储代理字典的副本 return True return False def get_proxy(self): """从代理池获取一个可用代理""" with self.lock: if not self.proxy_pool: self._refresh_proxies() if not self.proxy_pool: raise Exception("代理池为空") # 随机选择一个代理字典 return random.choice(self.proxy_pool).copy() # 返回副本避免修改原字典 def remove_proxy(self, proxy): """从代理池移除失效代理""" if not proxy: return proxy_str = f"{proxy.get('http', '')}|{proxy.get('https', '')}" with self.lock: # 直接比较字典内容 self.proxy_pool = [p for p in self.proxy_pool if not (p.get('http') == proxy.get('http') and p.get('https') == proxy.get('https'))] self.blacklist.add(proxy_str) def _refresh_proxies(self): """从API获取新代理并添加到代理池""" if time.time() - self.last_refresh_time < 10: # 10秒内不重复刷新 return self.last_refresh_time = time.time() for api_url in PROXY_API_URLS: try: new_proxy = self._fetch_new_proxy(api_url) if new_proxy and self.add_proxy(new_proxy): log.info(f"成功添加新代理: {new_proxy}") except Exception as e: log.error(f"从API {api_url} 获取代理失败: {e}") def _fetch_new_proxy(self, api_url): """从指定API获取新代理""" response = requests.get(api_url, timeout=10) if response.status_code == 200: proxy_ip = response.text.strip() return { 'http': f'http://{proxy_ip}', 'https': f'http://{proxy_ip}', } return None def _test_proxy(self, proxy): """测试代理是否可用""" try: test_url = "http://httpbin.org/ip" response = requests.get(test_url, proxies=proxy, timeout=10) return response.status_code == 200 except: return False # 全局代理池实例 proxy_pool = ProxyPool() def spider_detail(pk, i, flag, number, max_retries=3): """采集详情页数据""" headers = { } url = f"https://hbba.sacinfo.org.cn/stdDetail/{pk}" retry_count = 0 while retry_count < max_retries: proxy = None try: proxy = proxy_pool.get_proxy() page = SessionPage() page.get(url, headers=headers, proxies=proxy, timeout=10) # 提取数据 标准名称 = page.s_ele('t:h4').text keys = page.s_ele('@class=basic-info cmn-clearfix').s_eles('@class=basicInfo-item name') values = page.s_ele('@class=basic-info cmn-clearfix').s_eles('@class=basicInfo-item value') data = {key.text.strip(): value.text.strip() for key, value in zip(keys, values)} data['标准名称'] = 标准名称 try: 备案号 = page.s_ele('@class=para-title', index=3).next('t:p').text.replace('备案号:', '') except: 备案号 = '' try: 备案日期 = page.s_ele('@class=para-title', index=3).next('t:p', index=2).text.replace('备案日期:', '') except: 备案日期 = '' try: 起草单位 = page.s_ele('@class=para-title', index=4).next('t:p', index=1).text except: 起草单位 = '' try: 起草人 = page.s_ele('@class=para-title', index=5).next('t:p', index=1).text except: 起草人 = '' data['备案号'] = 备案号 data['备案日期'] = 备案日期 data['起草单位'] = 起草单位 data['起草人'] = 起草人 if "代替标准" not in str(data): data["代替标准"] = "" # 保存数据 db.add_smart(table='绿色食品标准', data=data) log.success(f'第{i}页{flag}/{number}条:采集成功 - {标准名称}') return True except Exception as e: retry_count += 1 if proxy: proxy_pool.remove_proxy(proxy) log.warning(f'移除失效代理: {proxy}') log.error(f'第{i}页{flag}/{number}条:采集失败(尝试{retry_count}/{max_retries}) - {e}') if retry_count < max_retries: time.sleep(random.uniform(2, 4)) proxy_pool._refresh_proxies() else: log.error(f'第{i}页{flag}/{number}条:采集最终失败') return False def spdeir_infos(): """主采集函数""" page = SessionPage() headers = { "accept": "application/json, text/javascript, */*; q=0.01", "accept-language": "zh-CN,zh;q=0.9", "cache-control": "no-cache", "content-type": "application/x-www-form-urlencoded", "origin": "https://hbba.sacinfo.org.cn", "pragma": "no-cache", "priority": "u=1, i", "referer": "https://hbba.sacinfo.org.cn/stdList", "sec-ch-ua": "\"Chromium\";v=\"136\", \"Google Chrome\";v=\"136\", \"Not.A/Brand\";v=\"99\"", "sec-ch-ua-mobile": "?0", "sec-ch-ua-platform": "\"Windows\"", "sec-fetch-dest": "empty", "sec-fetch-mode": "cors", "sec-fetch-site": "same-origin", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36", "x-requested-with": "XMLHttpRequest" } url = "https://hbba.sacinfo.org.cn/stdQueryList" # 初始化代理池 proxy_pool._refresh_proxies() for i in range(1, 856): data = { "current": i, "size": "100", "key": "", "ministry": "", "industry": "", "pubdate": "", "date": "", "status": "现行" } # 获取列表页数据 list_retry_count = 0 max_list_retries = 3 items = [] while list_retry_count < max_list_retries: proxy = None try: proxy = proxy_pool.get_proxy() log.info(f'开始采集第{i}页列表数据...') page.post(url, headers=headers, data=data, proxies=proxy, timeout=10) json_data = page.json items = json_data['records'] log.success(f'第{i}页列表数据获取成功,共{len(items)}条数据') time.sleep(random.uniform(1, 2)) break except Exception as e: list_retry_count += 1 if proxy: proxy_pool.remove_proxy(proxy) log.error(f'第{i}页列表数据获取失败(尝试{list_retry_count}/{max_list_retries}) - {e}') if list_retry_count < max_list_retries: time.sleep(random.uniform(1, 2)) proxy_pool._refresh_proxies() else: log.error(f'第{i}页列表数据最终获取失败,跳过该页') items = [] break if not items: continue # 使用线程池采集详情页 with ThreadPoolExecutor(max_workers=5) as executor: futures = [] for idx, item in enumerate(items, 1): future = executor.submit( spider_detail, pk=item['pk'], i=i, flag=idx, number=len(items) ) futures.append(future) # 等待所有任务完成 for future in concurrent.futures.as_completed(futures): try: future.result() except Exception as e: log.error(f'任务执行异常: {e}') # 页面采集完成后休息 sleep_time = random.uniform(2, 3) log.info(f'第{i}页采集完成,休息{sleep_time:.1f}秒...') time.sleep(sleep_time) if __name__ == '__main__': log.info('爬虫开始运行') try: spdeir_infos() except KeyboardInterrupt: log.info('用户中断爬虫运行') except Exception as e: log.error(f'爬虫运行异常: {e}') finally: log.info('爬虫运行结束')
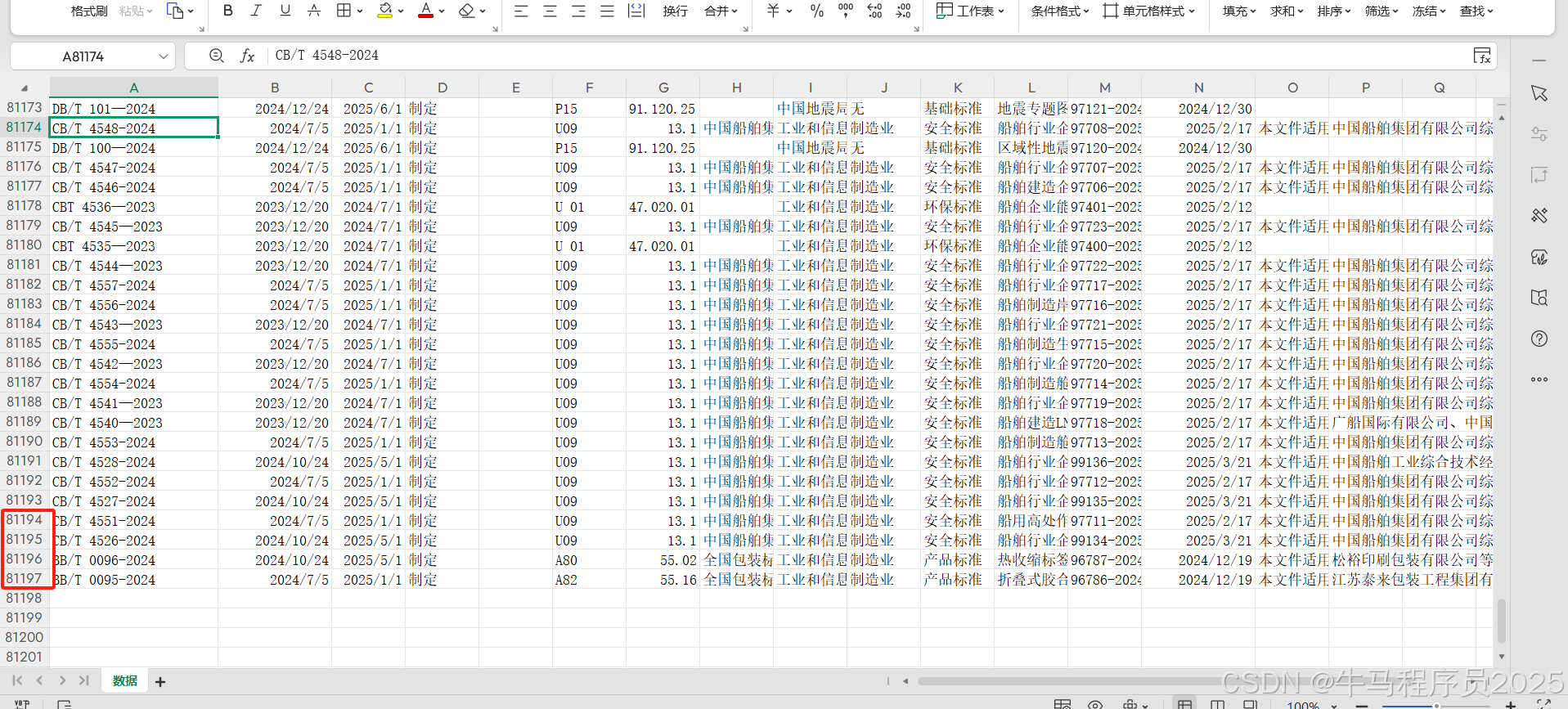
数据预览:


















 2174
2174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











