




第二章:爬虫的实现原理和技术
1.爬虫实现原理
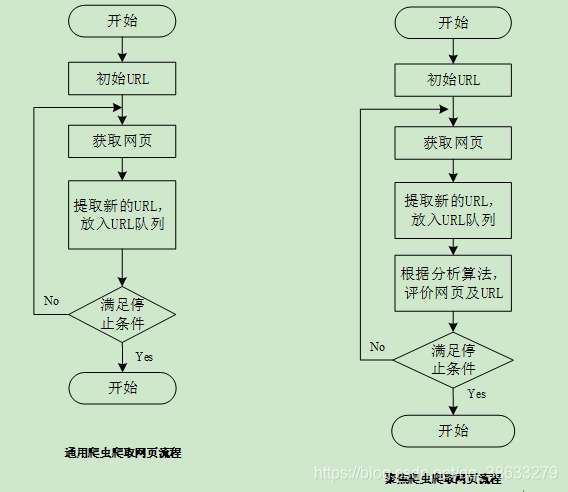
聚焦爬虫还需解决:
1.对爬取目标的描述或定义
2.对网页或数据的分析或过滤
3.对URL的搜索策略
2.爬虫爬取网页的详细流程
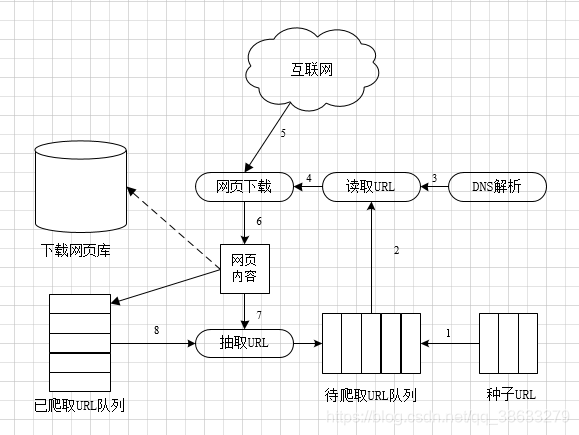
3.通用爬虫中网页的分类
1.已下载网页
2.已过期网页
3.待下载网页
4.可知网页
5.不可知网页(爬虫无法爬取获得的网页,但这部分网页占比较高)
4.通用爬虫相关网站文件
爬取网站前,需要对目标网站的规模和结构进行一定程度的了解,分别通过robots.txt和Sitemao.xml文件获得对网站的规模和结构的了解。
4.1 通用爬虫的robots.txt文件
robots.txt文件又称为君子协议,主要是告诉搜索引擎哪些网页可以爬取,哪些网页不能爬取,该协议又称为爬虫协议或者机器人协议,全称为**“网络爬虫排除标准(Robots Exclusion Protocol)”**,是互联网界通用的道德规范。其中robots.txt文件是搜索引擎访问网站要查看的第一个文件。
robots.txt文件的语法规则
1.User-agent:用于描述搜索引擎robot的名字。
---至少要有一条
---“ * ” 表示该协议对任何搜索引擎均有效,且这样的记录只能有一条
2.Disallow:用于描述不允许被搜索引擎访问到的一个URL。
---至少要有一条
3.Allow:用于描述希望被访问的一组URL。
可以主观的遵从robots.txt协议,也可以不遵从,但需要承担相应的法律协议。因此,该协议是一个防君子,不防小人的协议。
案例:
淘宝:https://www.taobao.com/robots.txt
** 淘宝:https://www.taobao.com/robots.txt**
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
Disallow: /
表示:禁止百度索引该网站
(1)允许所有的搜索引擎访问网站的所有部分或者建立一个空白的文本文档,命名为robots.txt。
User-agent:*
Disallow:或者
User-agent:*
Allow:/
(2)禁止所有搜索引擎访问网站的所有部分。
User-agent:*
Disallow:/
(3)禁止百度索引你的网站。
User-agent:Baiduspider
Disallow:/
(4)禁止Google索引你的网站。
User-agent:Googlebot
Disallow:/
(5)禁止除百度以外的一切搜索引擎索引你的网站。
User-agent:Baiduspider
Disallow:
User-agent:*
Disallow:/
(6),禁止除Google以外的一切搜索引擎索引你的网站。
User-agent:Googlebot
Disallow:
User-agent:*
Disallow:/
(7)禁止和允许搜索引擎访问某个目录,如:禁止访问admin目录;允许访问images目录。
Useragent:*
Disallow:/admin/
Allow:/images/
(8)禁止和允许搜索引擎访问某个后缀,如:禁止访问admin目录下所有php文件;允许访问asp文件。
Useragent:*
Disallow:/admin/*.php$
Allow:/admin/*.asp$
(9)禁止索引网站中所有的动态页面(这里限制的是有“?”的域名,如:index.php?id=8)。
User-agent:*
Disallow:/*?*
4.2 通用爬虫的Sitemap.xml文件
Sitemap.xml又称网站地图,主要列出网站中的网址及每个网址的其他元数据,如上次更新的时间、更改的频率及相对于网站上其他网址的重要程度等。
备注:虽然Sitemap.xml文件提供了爬取网站的有效方式,但该文件经常出现缺失或过期的问题,因此仅供参考。
5.http协议
http协议:指服务器和客户端进行数据交互的一种形式。(进行相互沟通的一种方式)
1.常见请求头信息:
1) User-agent:
查看:首先打开任意网站-->右击(检查)-->点击(网络/Network)-->重新点击网址出(按回车)【抓取数据包】-->打开任意的数据包-->点击(标题/Headers)-->查看(请求标头/Request Headers)-->user-agent
**user-agent:请求载体的身份标识**。请求方式包括通过浏览器的方式和代码的方式,通过浏览器的方式指直接在输入的方式【可以理解为界面交互的方式】;如:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36 Edg/91.0.864.71
代码的方式指通过代码完成请求。
2) Connection:请求完毕后,是断开连接还是保持连接
2.常见响应头信息:
1) Content-type:服务器响应客户端的数据类型
6.https协议
https协议:安全的超文本传输协议
7.加密方式
1.对称秘钥加密
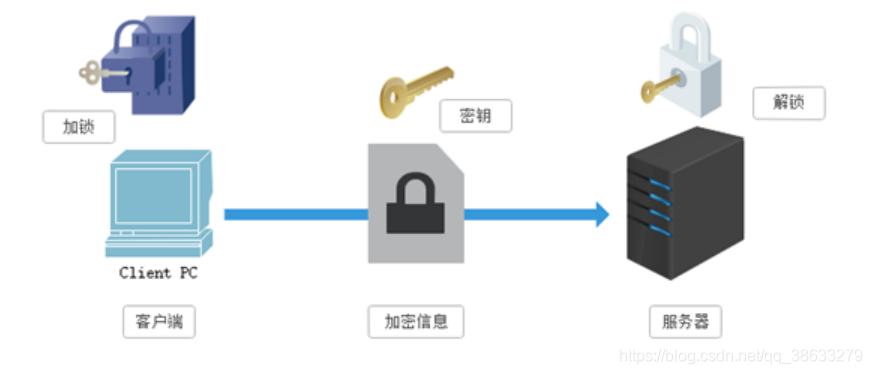
共享秘钥加密:加密和解密使用的共同的加密解密方式【使用的是一把锁】
2.非对称秘钥加密

“私有秘钥”:服务器解密的秘钥
“公开秘钥”:服务器告诉客户端按照自己给定的公开秘钥进行加密处理。
步骤1.服务器端设置加密方式,并将该加密方式发送给客户端【公开秘钥】
步骤2.客户端根据该加密方式对即将要发送给服务器端的数据进行加密
步骤3.客户端将加密的密文发送给服务器端
步骤4.服务器端接受密文后,使用私钥对密文进行解密。
备注:客户端到服务器端传输的过程中,仅仅传输的密文,没有传输秘钥。
优点:客户端和服务器端之间不需要传输,避免了被挟持的风险
缺点:1.通信效率低,处理复杂,
2.服务器端发送公钥,公钥存在被挟持的情况,如果被中间机构挟持且对其进行恶意篡改,再次发送给客户端。因此,非对称秘钥加密方式无法保证客户端获得的公钥是服务器端发送的公钥【存在被挟持的风险】
3.证书秘钥加密
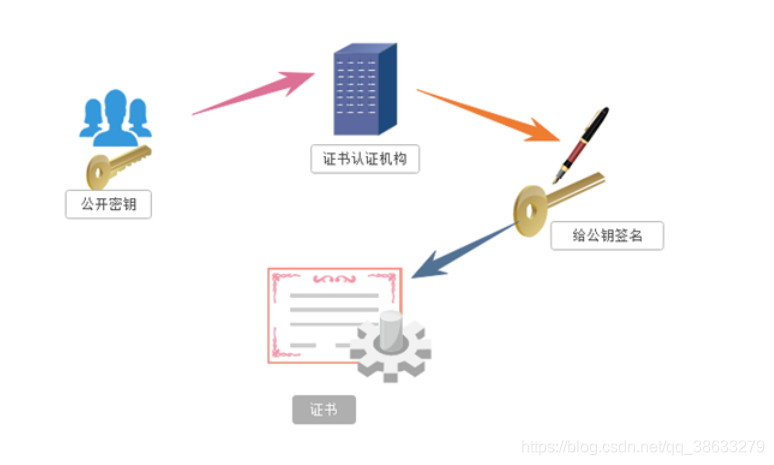
步骤1.服务端首先将公钥提交给“证书认证机构”。步骤2.证书认证机构对服务器端发送的公钥进行审核,审核通过后,对该公钥进行数字签名【防伪】;携带数字签名的公钥封装到证书当中;并将其发送给客户端。
步骤3.客户端接受证书【获得签名的公钥】,并使用该证书对即将发送的数据进行加密,并将密文发送给服务器端。
步骤4.服务器端使用私有秘钥对密文进行解密
非对称秘钥加密与证书秘钥加密的区别:
使用证书认证机构,保证了公钥是服务器端发送的公钥。
备注:学习文档:https://book.apeland.cn/details/66/

















 310
310





 到【灌水乐园】发言
到【灌水乐园】发言







