






文章目录
一、 Kafka简介
1.1 kafka定义
Kafka是由Apache软件基金会开发的一个开源流平台,由Scala和Java编写。
Apache Kafka是一个分布式流平台,一个分布式的流平台会包括3个关键能力点:
1.发布和订阅数据流,类似于消息队列或者是企业级别消息传递系统;
2.以容错的持久化方式来存储数据流;
3.处理数据流;
1.2 KafKa的应用场景
通常我们将kafka用在两类程序中:
1.建立实时的数据管道,以可靠的在系统或应用程序中获取数据;
2.构建实时流应用程序,用来转换或响应数据流;
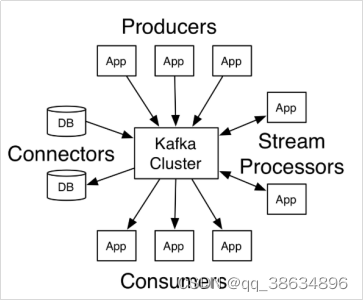
由上图可知:
1.Produces: 可以有很多的应用程序,将消息数据放入kafka集群中;
2.Consumer:可以有很多的应用程序,将消息从kafka集群中将数据拉取出来;
3.Connectors:kafka连接器可以将数据库中的数据导入kafka集群中,也可以将kafka中的数据导入到数据库中;
4.Stream Processors: 流处理器可以从kafka中拉取数据,也可以将数据写入到kafka中;
1.3 KafKa产生的背景
1.主要是为了解决 linkedin 中的数据管道问题,之前 linkedin 使用的是 ActiveMQ来进行数据交换,后来ActiveMQ 却还是无法满足 linkedin 对数据传递系统的要求,为了能够解决这个问题,linkedin决定研发自己的消息传递系统。
2.1 搭建KafKa 集群
2.1.1 将kafka安装包上传到虚拟机上,并且解压
cd /export/software/
tar -xvzf kafka_2.12-2.4.1.tgz -C ../server/
cd /export/server/kafka_2.12-2.4.1/
2.1.2 修改server.properties
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
# 指定broker的id
broker.id=0
# 指定Kafka数据的位置
log.dirs=/export/server/kafka_2.12-2.4.1/data
# 配置zk的三个节点
zookeeper.connect=node1.itcast.cn:2181,node2.itcast.cn:2181,node3.itcast.cn:2181
2.1.3 将安装好的kafka 复制到其他两台机器
cd /export/server
scp -r kafka_2.12-2.4.1/ node2.itcast.cn:$PWD
scp -r kafka_2.12-2.4.1/ node3.itcast.cn:$PWD
修改另外两个节点的broker.id分别为1和2
---------node2.itcast.cn--------------
cd /export/server/kafka_2.12-2.4.1/config
vim erver.properties
broker.id=1
--------node3.itcast.cn--------------
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
broker.id=2
2.1.4 配置Kafka配置环境变量
vim /etc/profile
export KAFKA_HOME=/export/server/kafka_2.12-2.4.1
export PATH=:$PATH:${KAFKA_HOME}
分发到各个节点
scp /etc/profile node2.itcast.cn:$PWD
scp /etc/profile node3.itcast.cn:$PWD
每个节点加载环境变量
source /etc/profile
2.1.5 启动服务器
# 启动ZooKeeper
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
# 启动Kafka
cd /export/server/kafka_2.12-2.4.1
nohup bin/kafka-server-start.sh config/server.properties &
# 测试Kafka集群是否启动成功
bin/kafka-topics.sh --bootstrap-server node1.itcast.cn:9092 --list
2.2 目录结构
bin: kafaka所有的执行脚本都在这里,例如:启动kafka服务器,创建Topic,生产者,消费者进程;
config: kafka所有的配置文件;
libs: 运行kafka所需要的所有jar包;
logs:kafka所有的日志文件,如果kafka出现了一些问题,可以到该目录中查看异常信息;
site-docs: kafka网站帮助文件;
2.3 Kafka 一键启动 / 关闭 脚本
为了方便将来一键启动、关闭kafka,我们可以编写一个脚本进行操作;
1.在节点中创建 /export/onekey 目录:
cd /export/onekey
2. 准备slave配置文件,用于保存要启动哪几个节点上面的kafka
node1.itcast.cn
node2.itcast.cn
node3.itcast.cn
3. 编写start-kafka.sh脚本
vim start-kafka.sh
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;export JMX_PORT=9988;nohup ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties >/dev/nul* 2>&1 & "
}&
wait
done
4.编写stop-kafka脚本
vim stop-kafka.sh
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;jps |grep Kafka |cut -d' ' -f1 |xargs kill -s 9"
}&
wait
done
5.给start-kafka.sh 、 stop-kafka配置执行权限
chmod u+x start-kafka.sh
chmod u+x stop-kafka.sh
6.执行一键启动、一件关闭
./start-kafka.sh
./stop-kafka.sh
3.基础操作
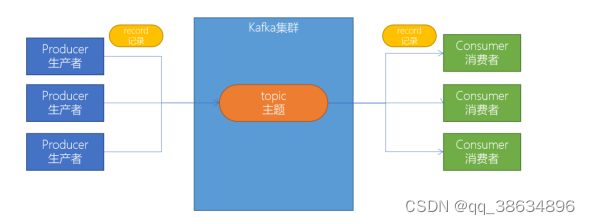
3.1 创建topic
创建topic(主题) kafka中所有的消息都是保存在主题中,要生产消息到kafka,首先得要有一个确定的主题;
#创建一个test(主题)
bin/kafka-topics.sh --create --bootstrap-server node1.itcast.cn:9092 --topic test
# 查看目前Kafka中的主题
bin/kafka-topics.sh --list --bootstrap-server node1.itcast.cn:9092
3.2 生产消息到kafka
使用kafka的内置测试程序,生产一些消息到kafka的test的主题中。
# 脚本命令:bin/kafka-console-producer.sh(从控制窗口读取消息)
bin/kafka-console-producer.sh --broker-list node1.itcast.cn:9092 --topic test
3.3 从KafKa中消费消息
使用下面的命令来消费 test 主题中的消息。
from-beginning:从头拉取消息
bin/kafka-console-consumer.sh --bootstrap-server node1.itcast.cn:9092 --topic test --from-beginning
4. 基准测试
4.1 含义
基准测试:是一种测量和评估软件性能指标的活动。通过基准测试,我们可以了解到软件、性能的水平;主要测试负载的执行时间、传输速度、吞吐量、资源占用等情况;
4.2 基于一个1个分区和一个副本的基准测试
测试步骤:
启动kafka集群;
创建1个分区1个副本的topic:benchmark;
同时运行生产者、消费者基准测试程序;
观察结果;
4.2.1 创建Topic
bin/kafka-topics.sh --zookeeper node1.itcast.cn:2181 --create --topic benchmark --partitions 1 --replication-factor 1
4.2.2 生产消息基准测试
在生产环境中,推荐使用生产5000万条消息,这样性能数据才会准确,
bin/kafka-producer-perf-test.sh --topic benchmark --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=node1.itcast.cn:9092,node2.itcast.cn:9092,node3.itcast.cn:9092 acks=1
bin/kafka-producer-perf-test.sh
topic benchmark 主题名称
num-records 5000000 总共指定生产的数据量(默认500万)
throughput -1 指定吞吐量–限流(-1 为不指定)
-record-size 1000 指定数据的大小
-producer-props bootstrap.servers=node1.itcast.cn:9092,node2.itcast.cn:9092,node3.itcast.cn:9092 acks=1 指定kafka集群的地址 ACK模式
4.2.2 消费消息基准测试
在生产环境中,推荐使用生产5000万条消息,这样性能数据才会准确,
bin/kafka-consumer-perf-test.sh --broker-list node1.itcast.cn:9092,node2.itcast.cn:9092,node3.itcast.cn:9092 --topic benchmark --fetch-size 1048576 --messages 5000000
bin/kafka-consumer-perf-test.sh
broker-list 指定kafka集群的地址
num-records 5000000 总共指定生产的数据量(默认500万)
topic benchmark 指定topic 的名称
fetch-size 1048576 指定每次要拉取数据的大小
messages 5000000 总共要消费的消息条数















 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









