






一、Exacty-Once一致性语义
Exacty-Once 作为分布式一致性语义中最常见的一个话题,当任意条数据流转化成某个分布式系统中,如果系统对整个过程中对任意条数据都可以精确处理一次,且处理结果准确,则会认为该系统满足 Exacty-Once 一致性;
由于分布式系统本来就具有跨网络,多节点,高并发,高可用等特性,难免会出现节点异常,线程死亡,网络传输失败等情况,从而导致数据丢失,重复发送,多次处理异常;
在分布式系统中如果要保证 Exacty-Once 一致性,不是依靠某一个环节的一致性,而是要要求系统全流程都要保留强一致性;
二、使用步骤
1.“检查点”(checkpoint)
为了保证 exactly-once 的特性,则使用了“检查点” 特性,如果出现故障时候将会重置会正确的状态,Flink 实现了流批处理一体化模式,实现按照事件处理和无需处理两种模式,基于内存计算,强大高效反压机制和内存管理,基于轻量级快照 checkpoint 机制;自动实现一致性语义;
数据源端:
支持可靠的消息数据源(如Kafka) 数据可重读;
Flink 自己管理 offset (手动提交offset)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.Flink 消费端
轻量级快照机制:一致性检查点
所谓一致性检查点:就是在某一个时间点上所有任务状态拷贝(快照),该时间点刚好是所有处理好一个相同数据的时间;
- 一致性检查点:
间隔时间自动执行分布式一致性检查点程序,异步插入barrir 检查点分界线;内存状态自动自动存储为CP进程文件,保证数据精确处理一次;
(1) 从source(Input)端开始,JobManager会向每个source(Input)发送检查点barrier消息,启动检查点。在保证所有的source(Input)数据都处理完成后,Flink开始保存具体的一致性检查点checkpoints,并在过程中启用barrier检查点分界线。
(2) 接收数据和barrier消息,两个过程异步进行。在所有的source(Input)数据都处理完成后,开始将自己的检查点(checkpoints)保存到状态后(StateBackend)中,并通知JobManager将Barrier分发到下游;
(3) barrier向下游传递时,会进行barrier对齐确认。待barrier都到齐后才进行checkpoints检查点保存。
2.Flink 输出端
轻量级快照机制:一致性检查点
Flink 内置的二阶段提交机制也变相实现了事务一致性,支持幂等写入,事务二阶段提交写入机制;
- 幂等写入
这一块主要和Spark写入差不多,相同的 Key/ID 更新写入,数据不变,借助主键支持唯一性约束的存储系统,实现幂等性写入数据;
-事务写入: 二阶段提交 + WAL预写日志:
Flink在处理完source端数据接收和operator算子计算过程,待过程中所有的checkpoint都完成后,准备发送数据到sink端,此时启动事务。其中存在两种方式:
(1) WAL预写日志: 将计算结果先写入到日志缓存(状态后端/WAL)中,等checkpoint确认完成后一次性写入到sink。
(2) 二阶段提交: 对于每个 checkpoint 创建事务,先预先将数据提交到sink中,然后等待所有的checkpoint 全部完成之后再真正的提交请求到sink中,并且将状态改为已经确认;
整体思想:为 checkpoint 创建事务,先预提交数据至sink中,然后等待所有的 checkpoint 全部完成之后,才把计算结果写入到sink中
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
2 Flink+Kafka 如何实现端到端的 exactly-once 语义
我们知道,端到端的状态一致性的实现,需要每一个组件都实现,对于 Flink + Kafka 的数据管道系统(Kafka 进、Kafka 出)而言,各组件怎样保证 exactly-once语义呢?
- 内部: 利用 checkpoint 机制 ,将状态存盘,发生故障的时候可以恢复,保证内部状态的一致性;
- source: kafka consumer 作为source ,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候连接器来重置偏移量,重新消费数据,保证数据一致性;
- sink —— kafka producer 作为 sink,采用两阶段提交sink,需要实现一个TwoPhaseCommitSinkFunction;
内部的 checkpoint 机制我们已经了解,那source 和 sink 是怎样运行 的呢?
Flink 由 JobManager 协调各个 TaskManager 进行 checkpoint 存储,checkpoint 保存在 StateBackend 中,默认StateBackend 是内存级别的,也可以改为文件进行持久化保存
当 checkpoint 启动时候,JobManager 将会检查分界线(barrier)注入数据流,barrier 会在算子之间传下去,

每个算子对当前的状态做一个快照,保存到状态后端,对于source 而言将会把当前 的偏移量作为状态保存起来,下次 checkpoint 恢复的时候,source 将会重新提交偏移量,从上次保存的位置重新消费数据;

每一个内部 transform 任务遇到 barrier 时候,都会将状态保存到 checkpoint 里面。
sink 任务将数据写入外部Kafka ,这些数据都是属预提交的事务(还无法被消费)当遇到 barrier 时,把状态保存到状态后端,并开启新的预提交事务。
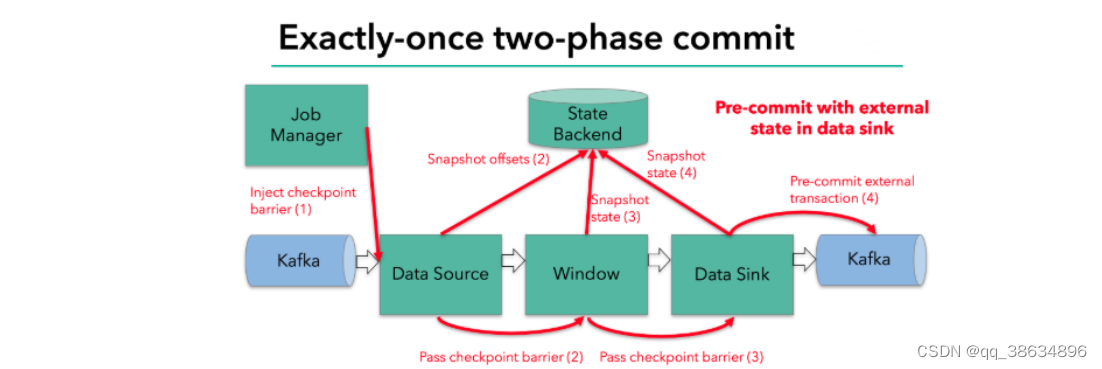
当所有算子任务的快照完成,就是这次的 checkpoint 完成的时候,JobManager 会向所有的任务发送通知,确认这次的 checkpoint 完成。
当sink 任务收到确认通知,就会正式提交之前的事务,kafka中未确认的数据将会改为已经确认,数据就可以真正被消费了。
逻辑数据流图:
在运行的时候,一般会将程序映射成为“逻辑数据流”,它包含三部分(每个dataflow 以一个或者多个 sources 开始 或者以一个或者多个sink结束);
-
执行图(ExecutionGraph)
由Flink 程序直接映射成为数据流图 是 StreamGraph ,称为逻辑数据流图,因为他们是表示计算逻辑的高级视图,为了执行一个流处理程序,Flink需要将逻辑流图转换为物理数据流图(执行图),Flink中的执行图可以分为四层:层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
StreamGraph: 是根据用户通过 Stream API 编写的代码生成的最初的图,用来表示程序的拓扑结构;
JobGraph:StreamGraph经过优化之后之后生成了 JobGraph,提交给了 JobManager 数据结构,主要优化为:将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间的流动所需要的序列化和反序列化、传输消耗;
ExecutionGraph: JobManager 根据 JobGraph 生成的 ExecutionGraph ,是 JobGraph 的并行版本,是最核心的的数据结构;














 716
716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









