








回答两个节点是否连接?是否存在路径?及路径是什么?同样通过求解路径问题可以解决是否连接问题,但是复杂 度更高

堆维护了最大值 或最小值 ,因此相对于顺序表更加有效
并叉集基本操作,union(p,q)合并两个元素到同一个集合,isConnected(p,q)判断两个元素是否属于同一个集合

并查集的基本数据表示

索引为0和index 为2的id为0,表示属于同一个集合,这里的id(第二行) 表示不同的类别。
则判断两个元数是否属于同一个集合,即间复判断其对应的集合id 是否值相同即可,如下图,这种方法的时间复杂度为O(1)


原本和1属于同一个集合的元素及原本与4 属于同一个元素的元素被 union 到了同一个集合,即它们的id可以设置为1或-1;

这里设置为1,即将所有与4 相同的集合id变为与1 所属集合的id 号,即将0变为1,由于需要遍历数组,则quick Find 下的UNion 的时间复杂度为O(n)

java 实现Quick Find
构建接口(关于接口定义可参考)
public interface UF {
int getSize();
boolean isConnected(int p,int q);
//不一定指int 的两个值 ,具体指id分别为p,q的两个元素是否相连,
//可以是指数组中两个元素的索引
void unionElements(int p, int q);
}
具体实现类
public class UnionFind1 implements UF {
private int [] id; //集合id
public UnionFind1(int size){
id =new int[size];
for(int i=0;i<id.length;i++)
id[i]=i;
//表示每一个元素属于一个集合
}
@Override
public int getSize(){
return id.length;
}
//接口中没有find 函数,故设计为private
//查找元素p对应的集合id
private int find(int p){
if(p<0&&p>=id.length)
throw new IllegalArgumentException("out of bounder");
return id[p];
}
//查找元素p,q 是否属于同一个集合
@Override
public boolean isConnected(int p,int q){
return find(p)==find(q);
}
@Override
public void unionElements(int p,int q){
int pID=find(p);
int qID=find(q);
if(pID==qID)
return;
for(int i=0;i<id.length;i++){
if(id[i]==pID)
id[i]=qID:
}
}
}
Quick Union
每一个元素可以看作一个节点,节点之间连接形成了的一种树结构,其与普通的树结构不同之处是由孩子指向父亲的。
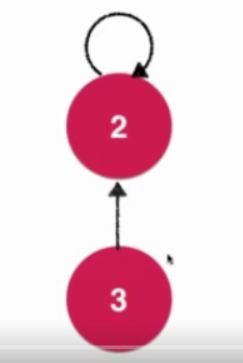
如上图根结点为2,其指向自己,其孩子节点同样的指向自己。现有一个节点1 要与上面union ,合并为同一集合,则由1节点指向根节点2,作为2 节点的孩子


如果想让节点7 和节点3 合并,则将节点7根节点指向3节点所在的根节点,如图下;

那么我们同样可以用数组的方式存储节点指针parent[i]表示第i 个元素指向的元素的索引。
初始时每一个节点指向了自己,每一个节点都是根节点,实际上是森林结构

如果Union 4,3 节点,即4指向3。在数组中表示为让parent[4]=3


当Union (9,4) 即由9指向4 的根节点,存在一个对数组无素4的根节点进行查寻的操作


通过观察,并叉集的union 操作,要分别寻找两个节点的根节点的,因此时间复杂度取决于两个节点的深度,一般远小于节点数量。但牺牲的代价是查询是否连接,的复杂度也是树的高度。
java 具体实现(版本2 )
// quick union
public class UnionFind2 implements UF {
private int [] parent;//表示每一个元素的指向
public UnionFind2(int size){
parent=new int[size];
for(int i=0;i<size;i++)
parent[i]=i;
//初始时每一个元素是一个指向自己的独立的树
}
@Override
public int getSize(){
return parent.length;
}
//查找过程,寻找根节点时间复杂度O(h)
private int find(int p){
while(p!=parent[p])
p=parent[p];
return p;
}
@Override
public boolean isConnected(int p,int q){
return find(p)==find(q);
}
@Override
public void unionElements(int p,int q){
int pRoot=find(p);
int qRoot=find(q);
if(pRoot==qRoot)
return ;
parent[pRoot]=qRoot;
}
}
quick union与quick find 对比
import java.util.Random;
public class Main {
private static double testUF(UF uf,int m){
int size=uf.getSize();
Random random=new Random();
long startTime=System.nanoTime();
for(int i=0;i<m;i++){
int a=random.nextInt(size);
int b=random.nextInt(size);
uf.unionElements(a,b);
}
for(int i=0;i<m;i++){
int a=random.nextInt(size);
int b=random.nextInt(size);
uf.isConnected(a,b);
}
long endTime=System.nanoTime();
return (endTime-startTime)/1000000000.0;
}
public static void main(String[] args) {
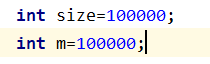
int size=100000;
int m=10000;
UnionFind1 uf1=new UnionFind1(size);
System.out.println("UnionFind1:"+testUF(uf1,m)+"s");
UnionFind2 uf2=new UnionFind2(size);
System.out.println("UnionFind2:"+testUF(uf2,m)+"s");
}
}
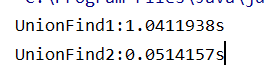
增大m的值 如下所示:UnionFind2增大,对于UnionFind 1 低层使用的是数组,合并操作是对连续空间进行操作,低层 jvm有很好的操作,而Union 低层是由索引实现的,不断地址空间跳转,其二UNIonfind 2中 m很大,树的深度可能很大


基于size的优化方法:
quick union 没有考虑两颗树的大小,有可能不平衡,对树的形态不作判断,有可能得到类似于链表的结构,深度很大



让8指向9时的深度较大,可以让9指向8即为优化,即让深度小的指向深度大的节点,因此在具体实现中新增以sz[i]来 记录以i为根节点的集合的大小
优化实现
// quick union
public class UnionFind3 implements UF {
private int [] parent;//表示每一个元素的指向
private int [] sz ;//sz[i]表示以i为根的集合中的元素个数
public UnionFind3(int size){
parent=new int[size];
sz=new int [size];
for(int i=0;i<size;i++) {
parent[i] = i;
//初始时每一个元素是一个指向自己的独立的树
sz[i]=1;
}
}
@Override
public int getSize(){
return parent.length;
}
//查找过程,寻找根节点时间复杂度O(h)
private int find(int p){
while(p!=parent[p])
p=parent[p];
return p;
}
@Override
public boolean isConnected(int p,int q){
return find(p)==find(q);
}
@Override
public void unionElements(int p,int q){
int pRoot=find(p);
int qRoot=find(q);
if(pRoot==qRoot)
return ;
if(sz[pRoot]<sz[qRoot])
{parent[pRoot]=qRoot;
sz[qRoot]+=sz[pRoot];
}
else {
parent[qRoot]=pRoot;
sz[pRoot]+=sz[qRoot];
}
}
}

基于rank的优化方法:
基于size的目的是合并后,尽量使两颗树的高度不要太高

如果按照size 的优化方法,节点数少的指向节点数多的则,不合理(深度增加)



实现
// quick union
public class UnionFind4 implements UF {
private int [] parent;//表示每一个元素的指向
private int [] rank ;//sz[i]表示以i为根的集合中的元素的高度
public UnionFind4(int size){
parent=new int[size];
rank=new int [size];
for(int i=0;i<size;i++) {
parent[i] = i;
//初始时每一个元素是一个指向自己的独立的树
rank[i]=1;
}
}
@Override
public int getSize(){
return parent.length;
}
//查找过程,寻找根节点时间复杂度O(h)
private int find(int p){
while(p!=parent[p])
p=parent[p];
return p;
}
@Override
public boolean isConnected(int p,int q){
return find(p)==find(q);
}
@Override
public void unionElements(int p,int q){
int pRoot=find(p);
int qRoot=find(q);
if(pRoot==qRoot)
return ;
if(rank[pRoot]<rank[qRoot])
{parent[pRoot]=qRoot;
// sz[qRoot]+=sz[pRoot];不用维护qroot,proot 高度小,因此
}
else if(rank[pRoot]>rank[qRoot]){
parent[qRoot]=pRoot;
}
else {
parent[qRoot]=pRoot;
rank[pRoot]+=1;//注意加上本身节点
}
}
}
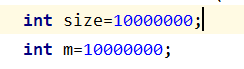
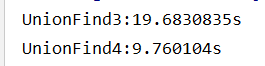
原因,千万级的数据上,两种方法差不多
基于路径压缩的优化方法

路径压缩的方法就是让高的树变矮的,最理想的是上图中的第三个图



上图过程表示了在查询4节点的同时,改变树的结构 主要更改的代码如下所示。
private int find(int p){
while(p!=parent[p]){
parent[p]=parent[parent[p]];
p=parent[p];
}
return p;
}
注意到当使用了路径压缩后,在合并操作中并没有维护rank的变化,因此rank 并不表示高度,但是并不影响。大的rank 值 在上边,小的rank 值在下边,只有同一层可能出现rank不同的情况。即整体大小是一致的
###递 规路径压缩

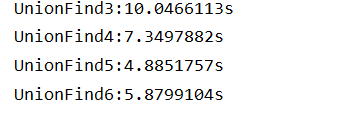
如何实现上图的路径压缩?可以采用递规
查询p结点,p结点及其之上的节点都指向根节点。find函数的作用是查找p节点的根节点,当p节点=其父亲节点时,p节点。

如果p节点非根节点,则让其指向父亲节点的根节点,由于递规的使用,因此多于UnionFind5
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









