







大家好呀,我是胡广,感谢大家收看我的博客,今天给大家带来的是一个众所周知的推荐系统的小demo,废话不多说,上才艺!!!
首先简单的看一下项目结构,很简单。
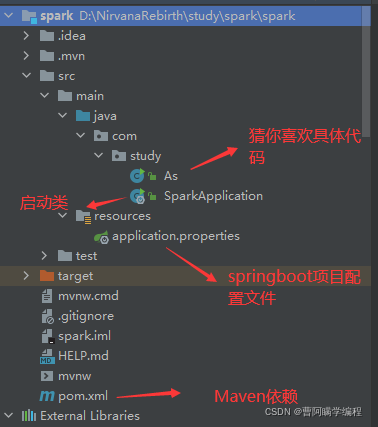
你得会创建SpringBoot项目
详细教程走这个链接,写得非常详细了
IDEA 如何快速创建 Springboot 项目 https://blog.csdn.net/sunnyzyq/article/details/108666480
https://blog.csdn.net/sunnyzyq/article/details/108666480
1.SparkApplication:SpringBoot的启动类
package com.study;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SparkApplication {
public static void main(String[] args) {
SpringApplication.run(SparkApplication.class, args);
}
}
2.As类:主要实现推荐逻辑代码,我这里写得是测试的数据,如果想运用到项目当中还得从数据库获取到数据再进行spark的推荐运算哦!
其中有一段这么个代码,这是获取的本地文件的电影或电视剧的数据,这个txt文件我也会给大家放在下边分享的文件链接里!
JavaRDD<String> lines = jsc.textFile("D:\\NirvanaRebirth\\study\\spark\\recommend.txt");给大家解释一下这个数据的格式,看到第一行是1,1,5
1(代表用户编号),1(代表电视剧或电影、商品编号),5(代表编号为1的用户给编号为1的电视剧的评分)

package com.study;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.mllib.recommendation.ALS;
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel;
import org.apache.spark.mllib.recommendation.Rating;
import org.apache.spark.rdd.RDD;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.List;
public class As {
public static void main(String[] args) {
List<String> list=new ArrayList<String>();
list.add("1,6,0");
list.add("2,1,4.5");
list.add("2,2,9.9");
list.add("3,3,5.0");
list.add("3,4,2.0");
list.add("3,5,5.0");
list.add("3,6,9.9");
list.add("4,2,9.9");
list.add("4,5,0");
list.add("4,6,0");
list.add("5,2,9.9");
list.add("5,3,9.9");
list.add("5,4,9.9");
list.add("3,10,5.0");
list.add("3,11,2.0");
list.add("3,12,5.0");
list.add("3,12,9.9");
list.add("4,14,9.9");
list.add("4,15,0");
list.add("4,16,7.0");
list.add("5,17,9.9");
list.add("5,18,9.9");
list.add("5,19,6.9");
// JavaRDD<String> temp=sc.parallelize(list);
//上述方式等价于
// JavaRDD<String> temp2=sc.parallelize(Arrays.asList("a","b","c"));
System.out.println("牛逼牛逼");
SparkConf conf = new SparkConf().setAppName("als").setMaster("local[5]");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("D:\\NirvanaRebirth\\study\\spark\\recommend.txt");
// JavaRDD<String> lines = jsc.parallelize(list);
// 映射
RDD<Rating> ratingRDD = lines.map(new Function<String, Rating>() {
public Rating call(String line) throws Exception {
String[] arr = line.split(",");
return new Rating(new Integer(arr[0]), new Integer(arr[1]), Double.parseDouble(arr[2]));
}
}).rdd();
MatrixFactorizationModel model = ALS.train(ratingRDD, 10, 10);
// 通过原始数据进行测试
JavaPairRDD<Integer, Integer> testJPRDD = ratingRDD.toJavaRDD().mapToPair(new PairFunction<Rating, Integer, Integer>() {
public Tuple2<Integer, Integer> call(Rating rating) throws Exception {
return new Tuple2<Integer, Integer>(rating.user(), rating.product());
}
});
// 对原始数据进行推荐值预测
JavaRDD<Rating> predict = model.predict(testJPRDD);
System.out.println("原始数据测试结果为:");
predict.foreach(new VoidFunction<Rating>() {
public void call(Rating rating) throws Exception {
System.out.println("UID:" + rating.user() + ",PID:" + rating.product() + ",SCORE:" + rating.rating());
}
});
// 向指定id的用户推荐n件商品
Rating[] predictProducts = model.recommendProducts(2, 8);
System.out.println("\r\n向指定id的用户推荐n件商品");
for(Rating r1:predictProducts){
System.out.println("UID:" + r1.user() + ",PID:" + r1.product() + ",SCORE:" + r1.rating());
}
// 向指定id的商品推荐给n给用户
Rating[] predictUsers = model.recommendUsers(2, 4);
System.out.println("\r\n向指定id的商品推荐给n给用户");
for(Rating r1:predictProducts){
System.out.println("UID:" + r1.user() + ",PID:" + r1.product() + ",SCORE:" + r1.rating());
}
// 向所有用户推荐N个商品
RDD<Tuple2<Object, Rating[]>> predictProductsForUsers = model.recommendProductsForUsers(3);
System.out.println("\r\n******向所有用户推荐N个商品******");
predictProductsForUsers.toJavaRDD().foreach(new VoidFunction<Tuple2<Object, Rating[]>>() {
public void call(Tuple2<Object, Rating[]> tuple2) throws Exception {
System.out.println("以下为向id为:" + tuple2._1 + "的用户推荐的商品:");
for(Rating r1:tuple2._2){
System.out.println("UID:" + r1.user() + ",PID:" + r1.product() + ",SCORE:" + r1.rating());
}
}
});
// 将所有商品推荐给n个用户
RDD<Tuple2<Object, Rating[]>> predictUsersForProducts = model.recommendUsersForProducts(2);
System.out.println("\r\n******将所有商品推荐给n个用户******");
predictUsersForProducts.toJavaRDD().foreach(new VoidFunction<Tuple2<Object, Rating[]>>() {
public void call(Tuple2<Object, Rating[]> tuple2) throws Exception {
System.out.println("以下为向id为:" + tuple2._1 + "的商品推荐的用户:");
for(Rating r1:tuple2._2){
System.out.println("UID:" + r1.user() + ",PID:" + r1.product() + ",SCORE:" + r1.rating());
}
}
});
}
}
3.pom.xml:maven的依赖项目
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.2</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.study</groupId>
<artifactId>spark</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spark</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--Spark 依赖-->
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core_2.11 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql_2.11 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.1.0</version>
<scope>compile</scope>
</dependency>
<!--Guava 依赖-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>14.0.1</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>janino</artifactId>
<version>3.0.8</version>
</dependency>
<!-- fix java.lang.ClassNotFoundException: org.codehaus.commons.compiler.UncheckedCompileException -->
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>2.7.8</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.17.Final</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/log4j-over-slf4j -->
<!--Hadoop 依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
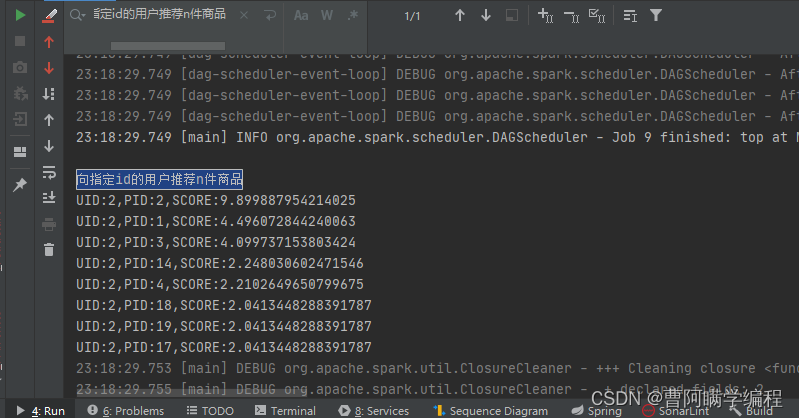
简单的运行效果
向指定id的用户推荐n件商品
有需要到这个百度云盘连接下载就行
链接:https://pan.baidu.com/s/1dhsHqzxdfZngJLaCqxrAGg 提取码:oaadhttps://pan.baidu.com/s/1dhsHqzxdfZngJLaCqxrAGg
好了,到这里就结束咯,是不是很简单呢?有啥不懂的或者有啥可改进的可以看下边添加我微信一起交流哦!微信:BitPlanet 需要毕业设计的小伙伴也可以联系,帝王般的服务你值得拥有




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











