







预测分析·民宿价格预测
赛题&数据
赛题
民宿这一名词,是日语中“Minshuku”的音译。我国第一部关于民宿的旅游行业标准《旅游民宿基本要求与评价》已从2017年10月1日起开始实施,该标准定义:民宿是利用当地闲置资源,民宿主人参与接待,为游客提供体验当地自然、文化与生产生活方式的小型住宿设施。
2019年4月,Trustdata公布了《2019年中国在线民宿预订行业发展研究报告》,报告中公布的数据显示,2016-2019年,受旅游消费人数的增加及需求的拉动,在线民宿房源数和房东数同比增加,其中至2018年我国在线民宿的房源数达到107.2万个,而房东数达到32.5万个,初步核算,平均一个房东拥有3.3个民宿房源,较2016年每人约2个民宿房源数实现了明显的增加。
近年来,用于房东或者户主将闲置房产变为私人住宿服务已变得流行。在私人住宿中,业主根据房间的大小和位置来决定住宿价格,但要设定合理的价格并不容易。因此,在本次练习赛旨在引导我们尝试建立一个模型,该模型使用某私人住宿在线服务平台上发布的房地产数据来预测住宿价格。

数据说明
本次练习赛所使用数据集基于民宿价格数据集,并且针对部分字段做出了一定的调整,所有的字段信息请以本练习赛提供的字段信息为准
字段信息内容参考如下:
| 字段名 | 数据类型 | 字段描述 |
|---|---|---|
| 数据ID | string | 数据的唯一ID,比如test_0,train_1024 |
| 容纳人数 | int | 房间可以允许住几个人 |
| 便利设施 | string | 房间提供的便利设施描述,如是否有电视空调 |
| 洗手间数量 | float | 洗手间的数量 |
| 床的数量 | int | 房间内床的个数 |
| 床的类型 | int | 床的类型编码 |
| 卧室数量 | int | 卧室的个数 |
| 取消条款 | int | 取消条款的类型编码 |
| 所在城市 | int | 民宿所在的城市编码 |
| 清洁费 | int | 是否需要清洁费的0/1编码 |
| 首次评论日期 | string | 民宿的首次评论日期 |
| 房主是否有个人资料图片 | string | 民宿介绍中是否有房主个人资料照片 |
| 房主身份是否验证 | int | 民宿房主身份是否验证过的0/1编码 |
| 房主回复率 | string | 民宿房主消息回复率 |
| 何时成为房主 | string | 房东何时成为该民宿的房主 |
| 是否支持随即预订 | string | 是否支持随即预定 |
| 最近评论日期 | string | 最近评论日期 |
| 维度 | float | 民宿所在的维度 |
| 经度 | float | 民宿所在的经度 |
| 民宿周边 | string | 民宿周边的景区 |
| 评论个数 | int | 民宿的历史评论个数 |
| 房产类型 | int | 民宿的房产类型编码,如个人住宅、公寓等 |
| 民宿评分 | float | 民宿的用户评分 |
| 房型 | int | 房子类型编码,比如单间还是整间等 |
| 邮编 | int | 民宿的邮编号码 |
| 价格 | float | 民宿价格 |
数据下载
报名 -> 进入组织 -> 首页可查看数据
提交&评审
提交方式
直接在赛事提交页面「上传」结果文件即可。
结果文件要求
提交文件必须为 csv 格式的文件,文件的字段信息如下:
| 字段名 | 数据类型 | 字段描述 |
|---|---|---|
| id | Int | 数据的id |
| price | Float | 民宿价格 |
客观评审
评测方法:
- 为了进行精度评估,使用了评估指标“ RMSE”。
- 评估指标大于等于0,预测精度越高,该值越小。
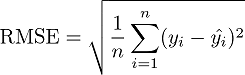
评审说明
每支队伍拥有每天 5 次提交与测评排名的机会,排行榜实时更新,从高到低排序,若队伍一天内多次提交结果,新结果版本将覆盖原版本。
免费算力
本次比赛提供免费版 2核 8G CPU 供参赛选手使用,报名后进入组织即可使用。
【参考代码】回归
import pandas as pd
from sklearn.model_selection import train_test_split
#from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LinearRegression #线性回归
import time
import numpy as np
from sklearn.preprocessing import MinMaxScaler
t_start = time.time()
#1.加载样本数据
data = pd.read_csv('训练集.csv')
data1 = pd.read_csv('测试集.csv')
#data.info() #可以用 .info()查看各列数据的缺失情况
data['民宿评分'] = data['民宿评分'].fillna(data['民宿评分'].mean())
data['床的数量'] = data['床的数量'].fillna(data['床的数量'].mean())#卧室数量
data['卧室数量'] = data['卧室数量'].fillna(data['卧室数量'].mean())
data1['民宿评分'] = data1['民宿评分'].fillna(data1['民宿评分'].mean())
data1['床的数量'] = data1['床的数量'].fillna(data1['床的数量'].mean())#卧室数量
data1['卧室数量'] = data1['卧室数量'].fillna(data1['卧室数量'].mean())
#2.样本数据特征提取
feature = data[['容纳人数','床的数量','卧室数量','所在城市',"是否支持随即预订","维度","经度","民宿评分"]]#feature.shape = (59288, 8)
target = data['价格']#target.shape = (59288,)
feature1 = data1[['容纳人数','床的数量','卧室数量','所在城市',"是否支持随即预订","维度","经度","民宿评分"]]#feature.shape = (59288, 8)
#3.样本数据集拆分 训练数据集train_data 测试数据集test_data
x_train = feature
y_train = target
x_test = feature1
#4.观察特征数据看是否需要进行特征工程 #feature数据全为数值型;不需要one_hot
#训练集的特征数据进行归一化操作
#Mm = MinMaxScaler()
#m_x_train = Mm.fit_transform(x_train)
#5.实例化模型对象
#knn = KNeighborsClassifier(n_neighbors=3).fit(m_x_train,y_train)
linreg = LinearRegression().fit(x_train, y_train)
#6.测试模型:使用测试数据
print('开始对测试集评分...')
score = linreg.score(x_train,y_train)
t_end = time.time()
print("共计耗时:",(t_end-t_start),'秒')
y_test = linreg.predict(x_test)
#print('linreg测试集评分:',score)
df = pd.read_csv( '.\\提交样例.csv')
df["价格"] =y_test
df.to_csv("提交样例1.csv",index=0)
【knn参考代码】 误差太大
#KNN
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier#KNN
import time
import numpy as np
from sklearn.preprocessing import MinMaxScaler
t_start = time.time()
#1.加载样本数据
data = pd.read_csv('训练集.csv')
data1 = pd.read_csv('测试集.csv')
#data.info() #可以用 .info()查看各列数据的缺失情况
data['民宿评分'] = data['民宿评分'].fillna(data['民宿评分'].mean())
data['床的数量'] = data['床的数量'].fillna(data['床的数量'].mean())#卧室数量
data['卧室数量'] = data['卧室数量'].fillna(data['卧室数量'].mean())
data1['民宿评分'] = data1['民宿评分'].fillna(data1['民宿评分'].mean())
data1['床的数量'] = data1['床的数量'].fillna(data1['床的数量'].mean())#卧室数量
data1['卧室数量'] = data1['卧室数量'].fillna(data1['卧室数量'].mean())
#2.样本数据特征提取
feature = data[['容纳人数','床的数量','卧室数量','所在城市',"是否支持随即预订","维度","经度","民宿评分"]]#feature.shape = (59288, 8)
target = data['价格']#target.shape = (59288,)
feature1 = data1[['容纳人数','床的数量','卧室数量','所在城市',"是否支持随即预订","维度","经度","民宿评分"]]#feature.shape = (59288, 8)
#3.样本数据集拆分 训练数据集train_data 测试数据集test_data
x_train = feature
y_train = target
x_test = feature1
#4.观察特征数据看是否需要进行特征工程 #feature数据全为数值型;不需要one_hot
#训练集的特征数据进行归一化操作
Mm = MinMaxScaler()
m_x_train = Mm.fit_transform(x_train)
m_x_test = Mm.transform(x_test)
#5.实例化模型对象
knn = KNeighborsClassifier(n_neighbors=3).fit(m_x_train,(1000*y_train).astype('int'))
#6.测试模型:使用测试数据
print('开始对测试集评分...')
score = knn.score(m_x_test,y_test*1000)
t_end = time.time()
print('knn测试集评分:',score)
print("共计耗时:",(t_end-t_start),'秒')
y_test = knn.predict(x_test).astype('float')/1000
df = pd.read_csv( '.\\提交样例.csv')
df["价格"] =y_test
df.to_csv("提交样例knn.csv",index=0)


















 761
761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











