







创建工程
- scrapy startproject ProName
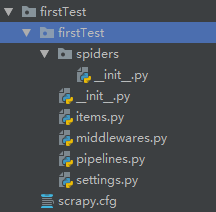
scrapy.cfg 基本不用修改
items.py 存储相关
pipelines 储存相关
Scrapy Engine
Scheduler
Downloader
创建完的项目里面没有包含这三项,
代表项目以及给我们封装好了功能,
我们要做的事情就是在去写spiders,items piplines就可以了 - cd ProName
- 创建爬虫文件 scrapy genspider spiderName www.xxx.com

. - 修改文件
# -*- coding: utf-8 -*-
import scrapy
class FirstSpider(scrapy.Spider):
#爬虫源文件的唯一标识,类似于html页面中的id
name = 'first'
#被允许访问的域名,和下面的start_urls属性里的内容联合使用
#start_urls里的域名哪些可以访问,但是一般不怎么用
# allowed_domains = ['www.xxx.com']
#列表里的域名都会被scrapy自动去请求
start_urls = ['https://www.baidu.com/','https://cn.bing.com/']
#解析数据
def parse(self, response):
print(response)
- settings:
- 不遵从robots协议 ROBOTSTXT_OBEY = False
- UA伪装 去浏览器开发者模式里的network中去复制一个
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
- LOG_LEVEL = ‘ERROR’ 日志文件的打印级别(不知道的翻出sam老师分享的django日志打印)
- 执行 scrapy crawl spiderName
scrapy的数据解析
解析时也支持xpath,但是这个xpath基本一样用,只是一些小细节不一样。
- extract():列表是有多个列表元素
- extract_first():列表元素只有单个
content = div.xpath('./a/text()')[0].extract()
content = li.xpath('./a/text()').extract_first()
scrapy的持久化存储
- 基于终端指令:
只可以将parse方法的返回值存储到磁盘文件中,用改命令生成的文件的后缀是有限制的,如果写text他会提示如下错误:
crawl: error: Unrecognized output format ‘text’, set one using the ‘-t’ switch or as a file extension from the supported list (
‘json’, ‘jsonlines’, ‘jl’, ‘csv’, ‘xml’, ‘marshal’, ‘pickle’)
从上面错误可以看出,基于终端指令数据的存储只支持:
‘json’, ‘jsonlines’, ‘jl’, ‘csv’, ‘xml’, ‘marshal’, ‘pickle’
scrapy crawl first -o file.csv
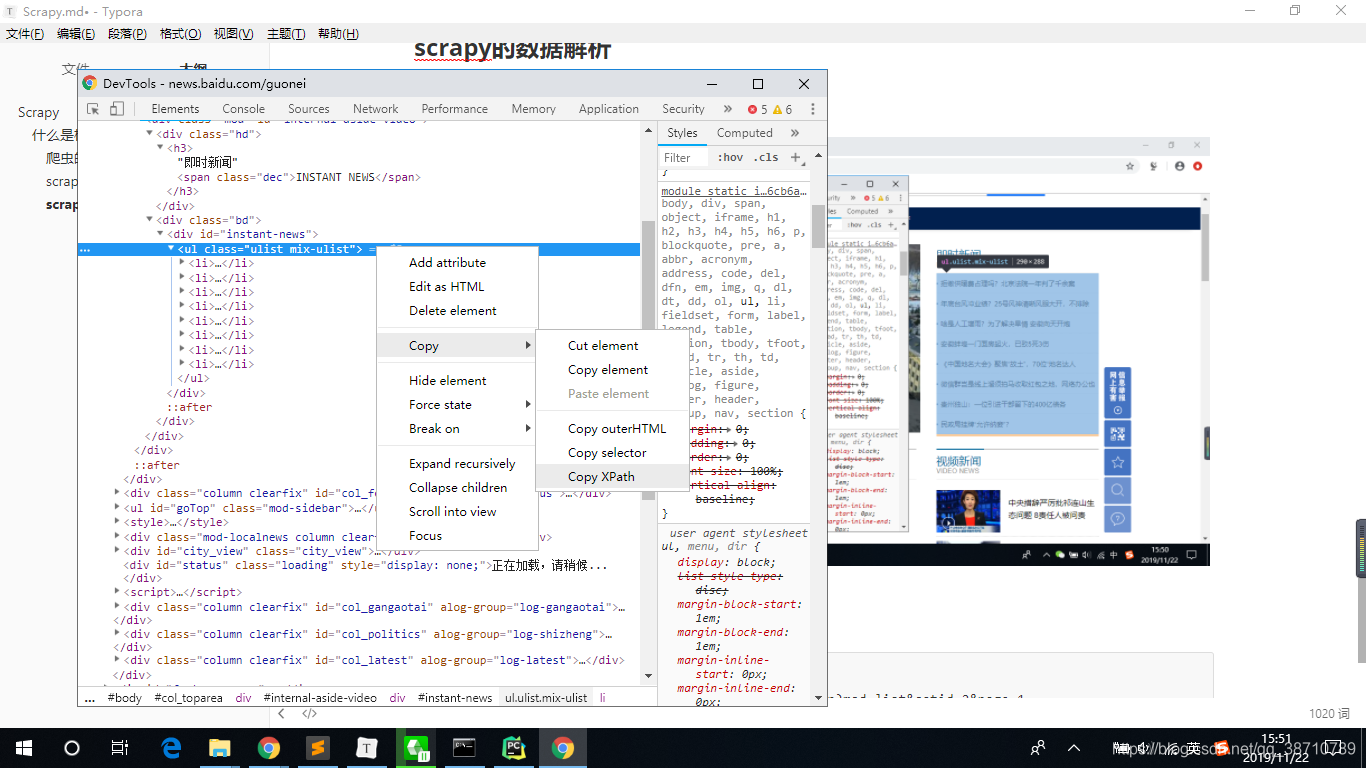
# -*- coding: utf-8 -*-
import scrapy
class FirstSpider(scrapy.Spider):
#爬虫源文件的唯一标识,类似于html页面中的id
name = 'first'
#被允许访问的域名,和下面的start_urls属性里的内容联合使用
#start_urls里的域名哪些可以访问,但是一般不怎么用
# allowed_domains = ['www.xxx.com']
#列表里的域名都会被scrapy自动去请求
start_urls = ['https://news.baidu.com/guonei']
#解析数据
def parse(self, response):
result = []
li_list = response.xpath('//*[@id="instant-news"]/ul/li')
for li in li_list:
#注意:xpath返回的列表中的列表元素是Selector对象,我们要解析获取的字符串的数据是存储在该对象中
#必须经过一个extract()的操作才可以将改对象中存储的字符串的数据获取
# content = div.xpath('./a/text()')[0].extract()
content = li.xpath('./a/text()').extract_first()
#xpath返回的列表中的列表元素有多个(Selector对象),想要将每一个列表元素对应的Selector中的字符串取出改如何操作?response.xpath('/div//text()').extract()
print(content) #<Selector xxx='qwer' data="拒缴供暖费占理吗?北京法院一年判了千余案">
dic = {
'title': content
}
result.append(dic)
return result
注意:
parse返回的结果要中要含有字典、Request或者Item,不然会报错,无法写入本地文件中
上面的程序如果 不把content内容让如到dict找那个而是直接 result.append(content),
会报如下错误:
ERROR: Spider must return Request, BaseItem, dict or None, got ‘str’ in <GET https://
news.baidu.com/guonei>

一. 基于管道:pipelines.py
编码流程:
1. 数据解析
2. 在item的类中定义相关的属性
import scrapy
class FirsttestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# Field用于声明项目的对象不会被分配为类属性。
content = scrapy.Field 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4251
4251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









