







文章目录
欢迎关注公众号【Python开发实战】,免费领取Python学习电子书!
工具-pandas
pandas库提供了高性能、易于使用的数据结构和数据分析工具。其主要数据结构是DataFrame,可以将DataFrame看做内存中的二维表格,如带有列名和行标签的电子表格。许多在Excel中可用的功能都可以通过编程实现,例如创建数据透视表、基于其他列计算新列的值、绘制图形等。还可以按照列的值对行进行分组,或者像SQL中那样连接表格。pandas也擅长处理时间序列。
但是介绍pandas之前,需要有numpy的基础,如果还不熟悉numpy,可以查看numpy快速入门教程。
导入pandas
import pandas as pd
Dataframe对象
一个DataFrame对象表示一个电子表格,带有单元格值、列名和行索引标签。可以定义表达式基于其他列计算列的值、创建数据透视表、按行分组、绘制图形等。可以将DataFrame视为Series的字典。
DataFrame运算
尽管DataFrame并没有试图模仿numpy的数组,但是也有一些相似之处。现在创建一个DataFrame来演示一下。
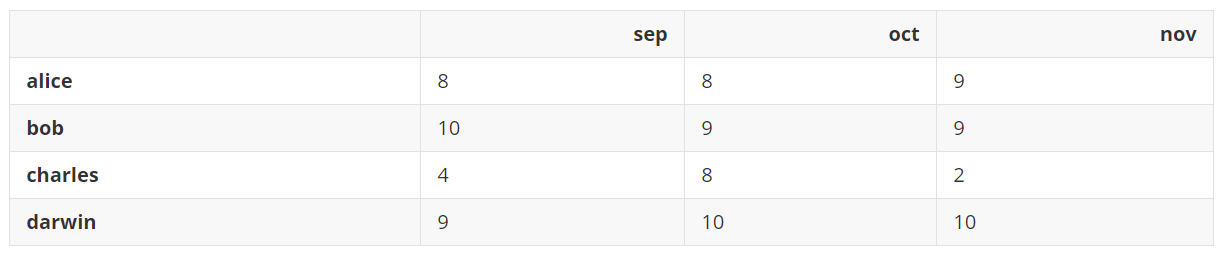
grades_array = np.array([[8, 8, 9], [10, 9, 9], [4, 8, 2], [9, 10, 10]])
grades = pd.DataFrame(grades_array, columns=['sep', 'oct', 'nov'], index=['alice', 'bob', 'charles', 'darwin'])
grades
输出:
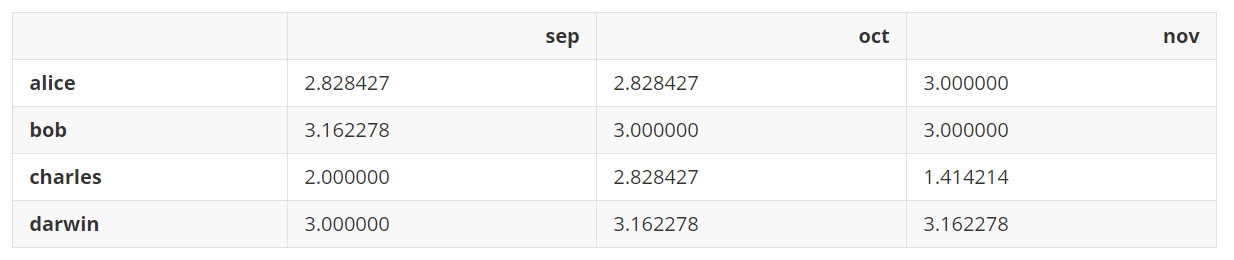
可以在DataFrame上应用numpy的数学函数,这个函数将会应用于所有的值。
np.sqrt(grades)
输出:
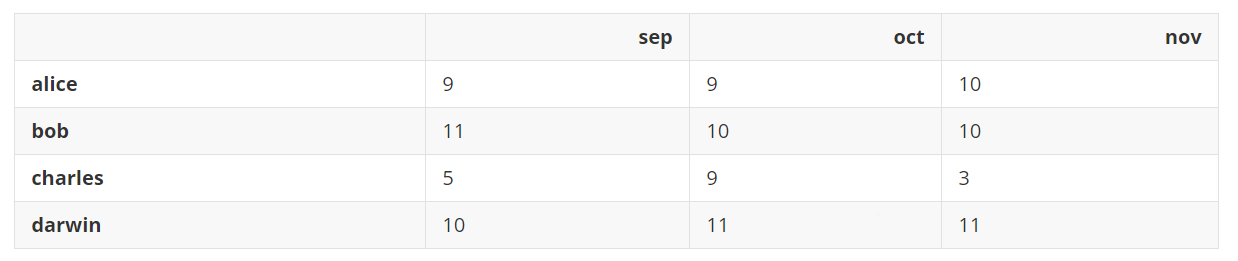
相似地,向DataFrame中加一个数字将会在所有的元素上加该值,这就是广播。
grades + 1
输出:
当然,所有其他的二进制运算,包括算术运算(*,/,**…)和条件运算(>,<,==…)也是如此。
grades > 5
输出:

聚合操作,例如计算最大值、求和、平均值等,是应用于每一列,返回一个Series对象。
grades.mean()
输出:
sep 7.75
oct 8.75
nov 7.50
dtype: float64
all()方法也是一个聚合操作,它检查所有的值是否为真。现在看看哪几个月里,所有学生的成绩都高于5分。
(grades > 5).all()
输出:
sep False
oct True
nov False
dtype: bool
大多数函数都有可选参数axis,该参数可以指定要沿着DataFrame的哪个轴执行操作。默认情况是axis=0,意味着操作是垂直进行的,即在每列上。可以设置为axis=1,在水平轴上执行操作,即在每行上。例如,现在找出哪些学生的所有成绩都大于5。
(grades > 5).all(axis=1)
输出:
alice True
bob True
charles False
darwin True
dtype: bool
如果只有有一个值为真,则any()方法会返回True。现在看看谁至少考了一个10分。
(grades == 10).any(axis=1)
输出:
alice False
bob True
charles False
darwin True
dtype: bool
如果向DataFrame添加一个Series对象或执行任何其他的二进制操作,pandas会尝试将该操作广播到DataFrame的所有行。但是只有在Series对象和DataFrame行的大小相同时,才会有效。现在从DataFrame中减去DataFrame中每一列的平均值。
grades - grades.mean() # 相当于 grades - [7.75, 8.75, 7.50]
输出:
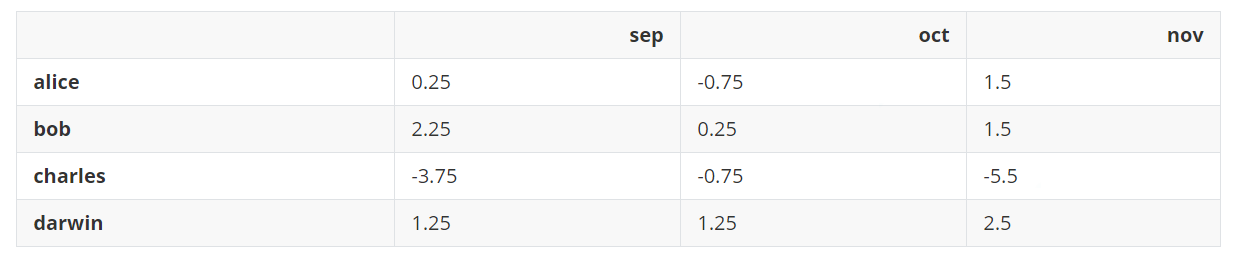
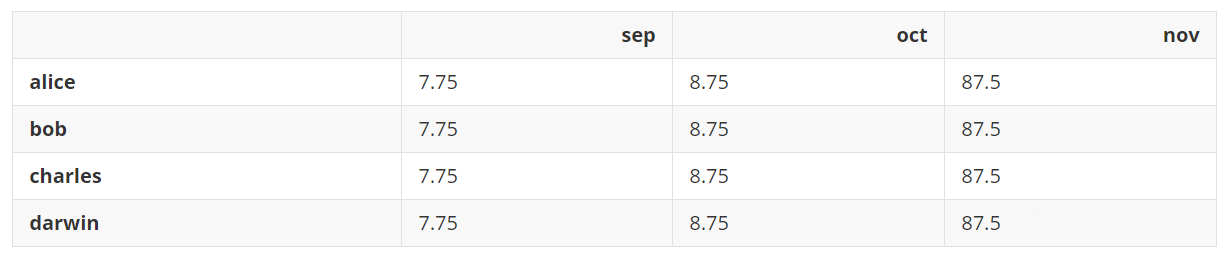
从所有9月份的成绩中减去7.75,从10月份的成绩中减去8.75,从11月份的成绩中减去7.5,这相当于减去下面的DataFrame。
pd.DataFrame([[7.75, 8.75, 87.5]]*4, index=grades.index, columns=grades.columns)
输出:
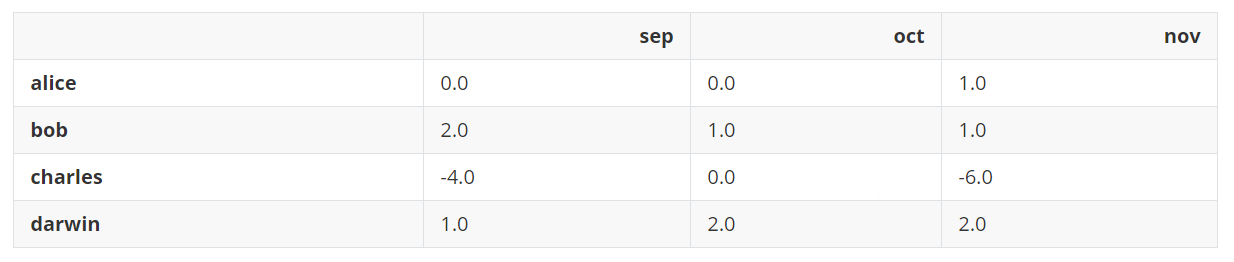
如果想从每个成绩中减去整体的平均值,使用下面的方法。
grades - grades.values.mean() # 从所有的成绩中减去整体平均值(8.00)
输出:
DataFrame合并
merge合并(类似SQL中的join)
pandas一个强大的功能是它能够在DataFrame上执行类似SQL的连接,并且支持各种类型的连接:内连接、左/右外连接和完全连接。
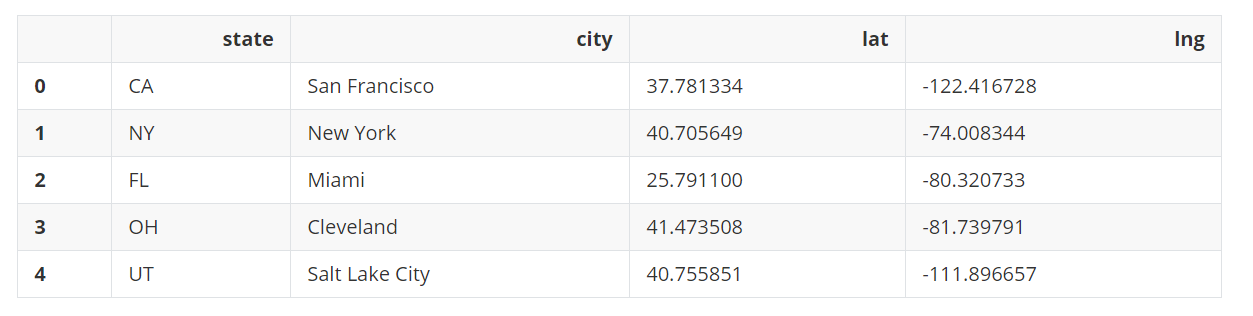
现在创建几个DataFrame。
city_loc = pd.DataFrame(
[
["CA", "San Francisco", 37.781334, -122.416728],
["NY", "New York", 40.705649, -74.008344],
["FL", "Miami", 25.791100, -80.320733],
["OH", "Cleveland", 41.473508, -81.739791],
["UT", "Salt Lake City", 40.755851, -111.896657]
], columns=["state", "city", "lat", "lng"])
city_loc
输出:
city_pop = pd.DataFrame(
[
[808976, "San Francisco", "California"],
[8363710, "New York", "New-York"],
[413201, "Miami", "Florida"],
[2242193, "Houston", "Texas"]
], index=[3,4,5,6], columns=["population", "city", "state"])
city_pop
输出:
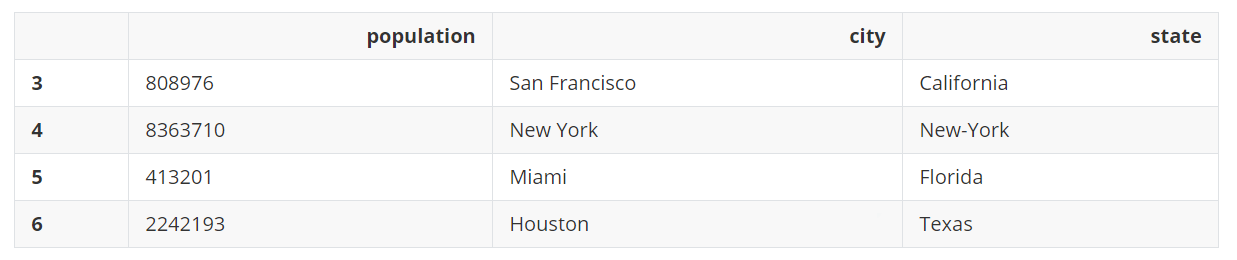
现在使用merge()函数,连接上面的DataFrame。
pd.merge(left=city_loc, right=city_pop, on='city')
输出:

请注意,两个DataFrame都有一个名为state的列,因此结果将它们重命名为state_x和state_y。
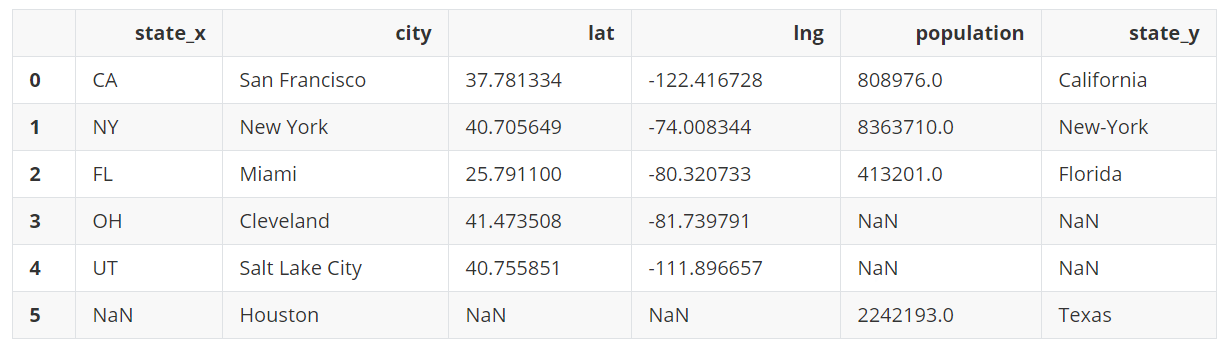
另外,需要注意,Cleveland、Salt Lake City、Houston被删除,因为它们不存在两个DataFrame中,这相当于内连接。如果想要一个完整的外部连接,不删除任何城市,也不添加NaN值,需要设置how=outer。
all_cities = pd.merge(left=city_loc, right=city_pop, on='city', how='outer')
all_cities
输出:
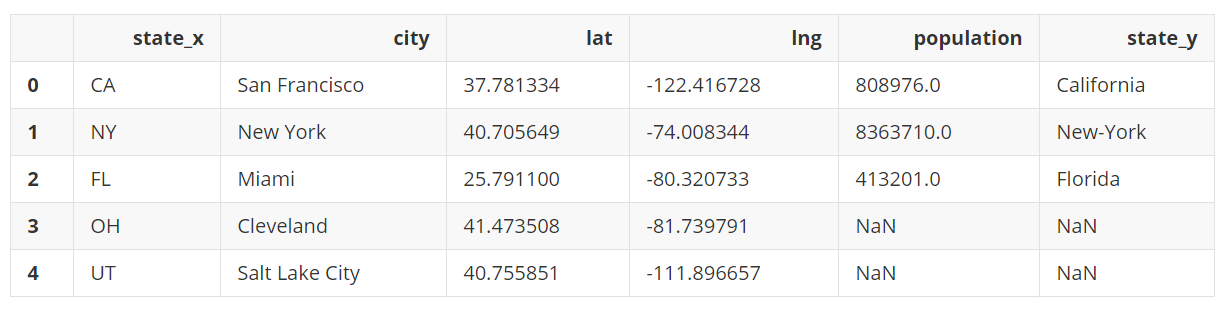
设置how=left,为左外连接,只有左侧DataFrame中存在的城市最终会出现在结果中。类似地,hoe=right,右侧DataFrame中存在的城市会出现在最终结果中。
pd.merge(left=city_loc, right=city_pop, on='city', how='left')
输出:
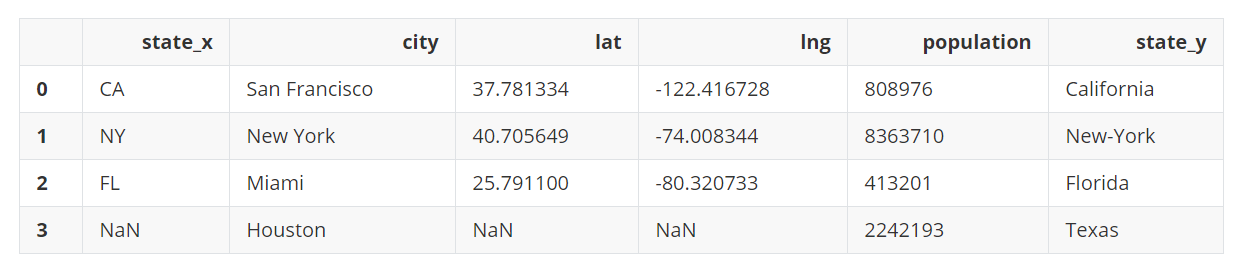
pd.merge(left=city_loc, right=city_pop, on='city', how='right')
输出:
如果要连接的键位于其中一个或两个DataFrame的行索引中,需要使用left_index=True或right_index=True。如果键列名不同,则需要会用left_on和right_on。
city_pop2 = city_pop.copy()
city_pop2.columns = ['population', 'name', 'state']
pd.merge(left=city_loc, right=city_pop2, left_on='city', right_on='name')
输出:

concat合并
concat()函数能够合并DataFrame。
result_concat = pd.concat([city_loc, city_pop])
result_concat
输出:
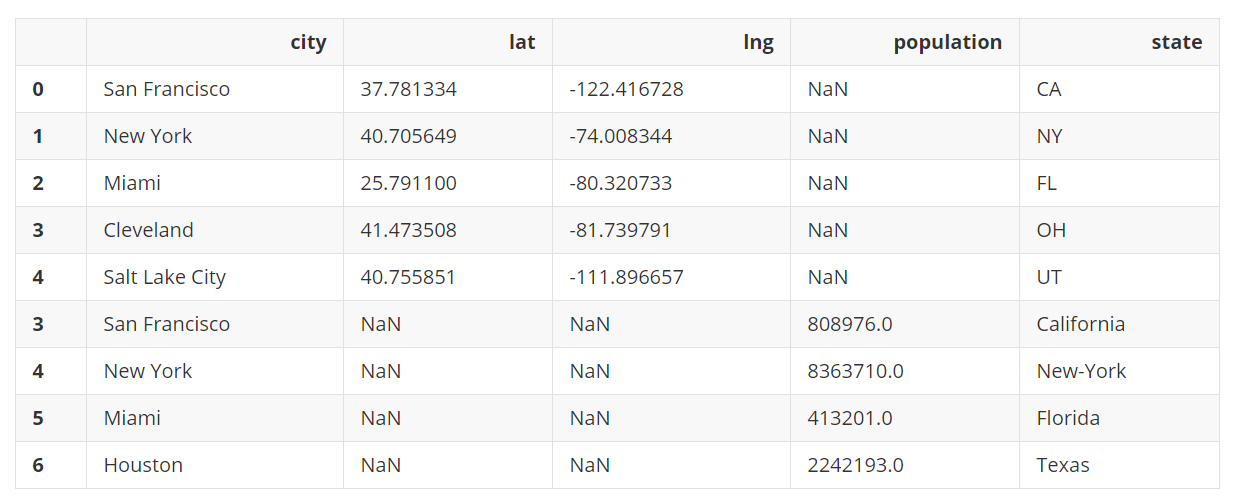
需要注意,上面的结果是水平对齐,也就是按列对齐,不是垂直对齐(按行对齐)。而且结果中出现了多个相同的行索引。
result_concat.loc[3]
输出:

可以告诉pandas忽略行索引。
pd.concat([city_loc, city_pop], ignore_index=True)
输出:
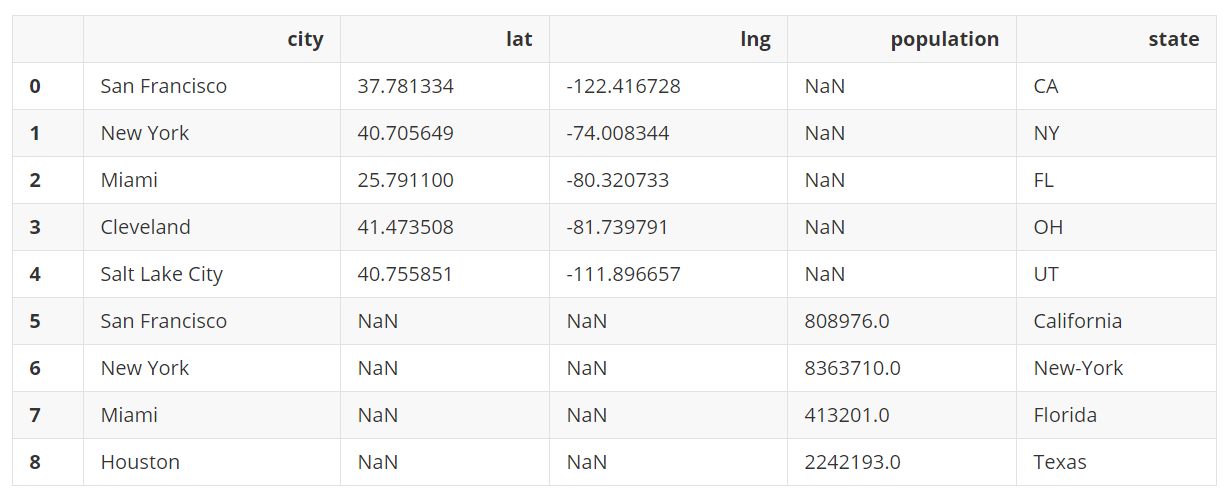
需要注意,当DataFrame中不存在某一列时,上面的结果就是用NaN值来填充的。如果设置join=inner,则只返回两个DataFrame中存在的列。
pd.concat([city_loc, city_pop], join='inner')
输出:
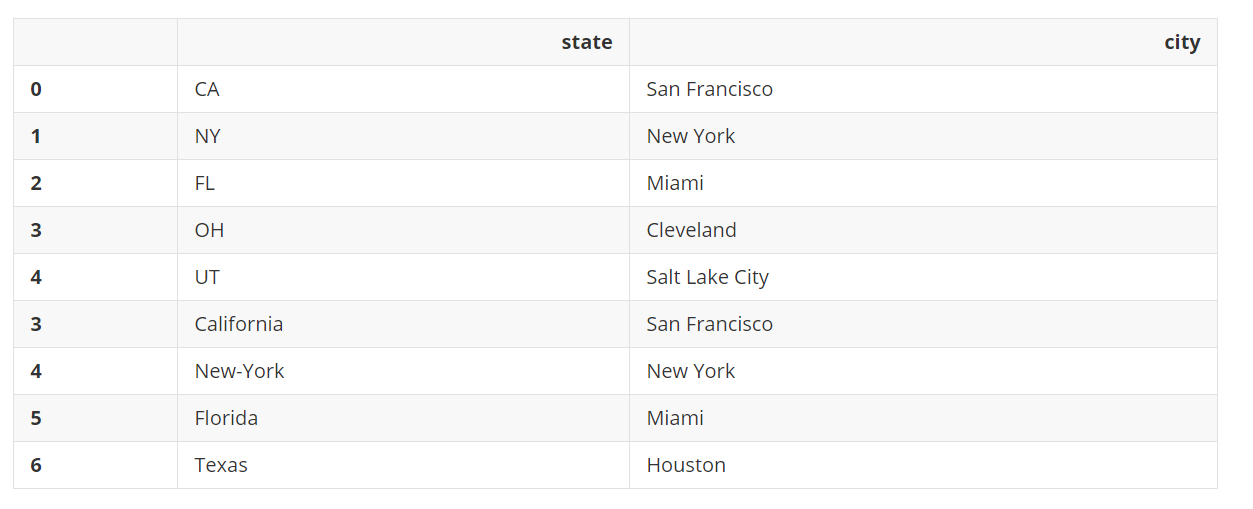
可以设置axis=1,水平合并(垂直对齐),而不是垂直合并。
pd.concat([city_loc, city_pop], axis=1)
输出:
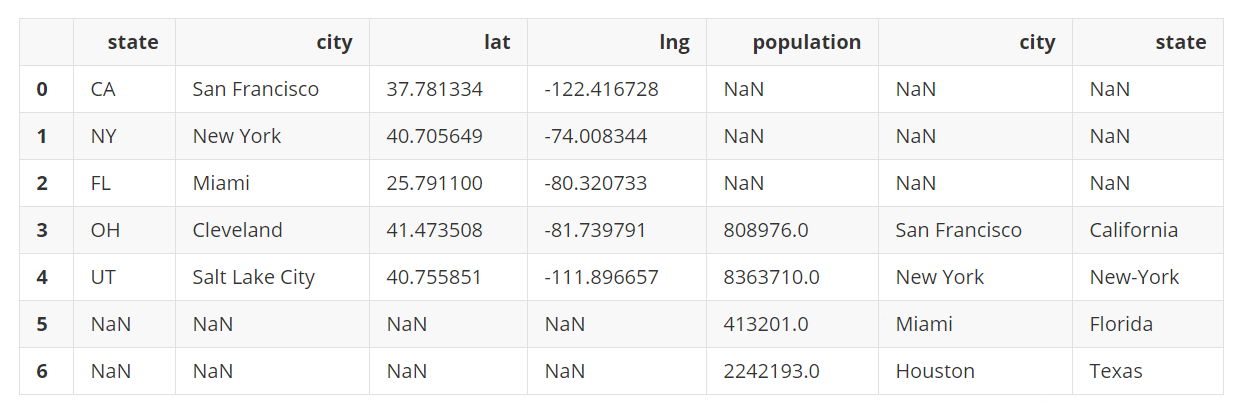
上面的结果没有多大意义,因为行索引没有很好的对齐,例如Cleveland和San Francisco在同一行上,因为他们共享了索引标签。因此,在合并之前,重新按城市名称设置行索引。
pd.concat([city_loc.set_index('city'), city_pop.set_index('city')], axis=1)
输出:
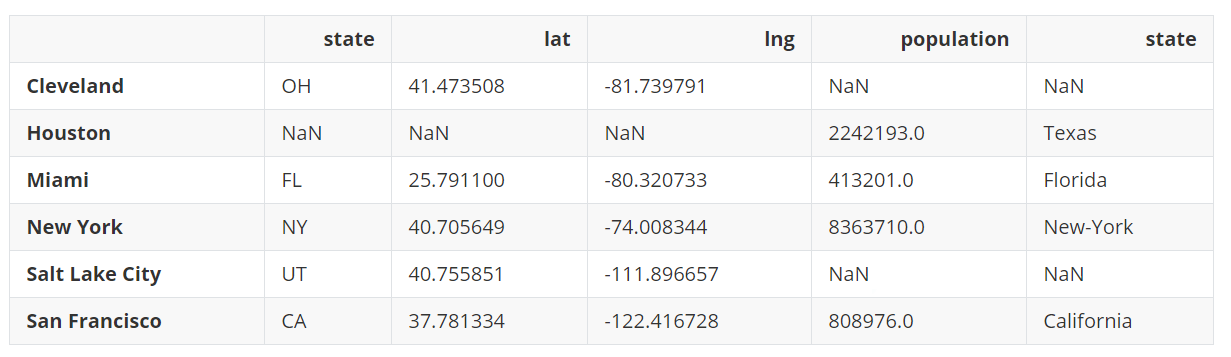
上面的链接看起来很像完整的外连接,不同的是两个state没有被重命名,且city列现在做为了行索引。
append合并
append()方法是垂直合并DataFrame的一个简答表达。
city_loc.append(city_pop)
输出:
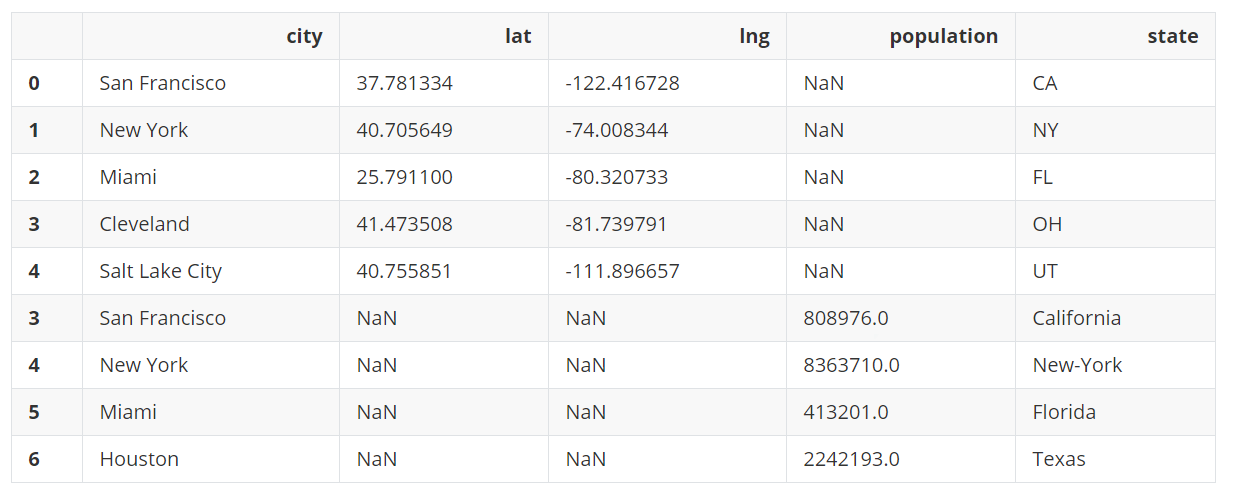
append()方法实际上并没有修改city_loc,而且返回修改后的副本。
代表类别的值
通常会有代表类别的值,例如1代表女性,2代表男性;或者A代表好,B代表平均值,C代表坏。这些分类值可能会不易于阅读,也不容易处理。但是pandas能够让它们变得容易。
现在在city_pop中添加一个表示类别的列。
city_eco = city_pop.copy()
city_eco['eco_code'] = [17, 17, 34, 20]
city_eco
输出:
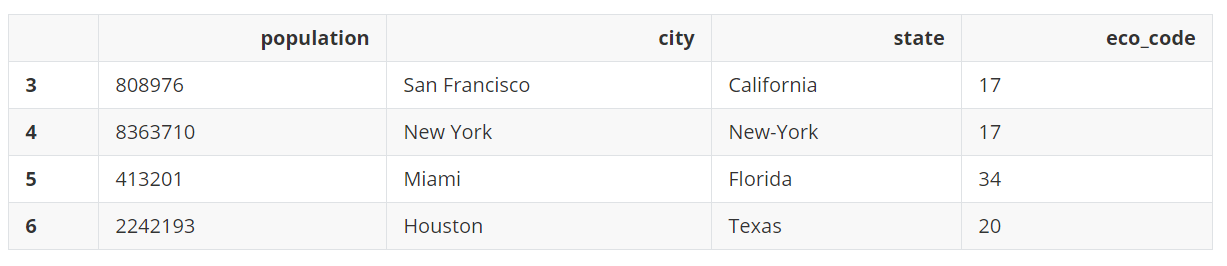
eco_code一列现在看起来毫无意义,现在来解决这个问题。首先根据eco_code创建一个新的类别列。
city_eco['economy'] = city_eco['eco_code'].astype('category')
city_eco['economy'].cat.categories
输出:
Int64Index([17, 20, 34], dtype='int64')
现在可以给每个类别起一个有意义的名字。
city_eco['economy'].cat.categories = ['Finance', 'Energy', 'Tourism']
city_eco
输出:
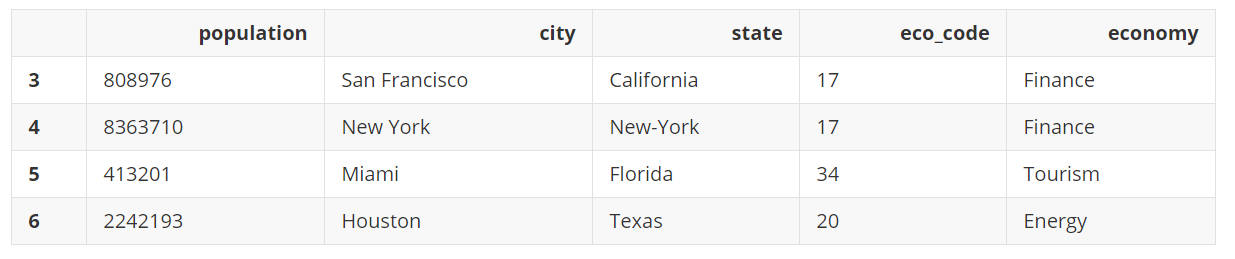
需要注意,当对类别一列的值进行排序时,是根据类别顺序排序的,而不是类名名字字母顺序排序的。
city_eco.sort_values(by='economy', ascending=False)
输出:
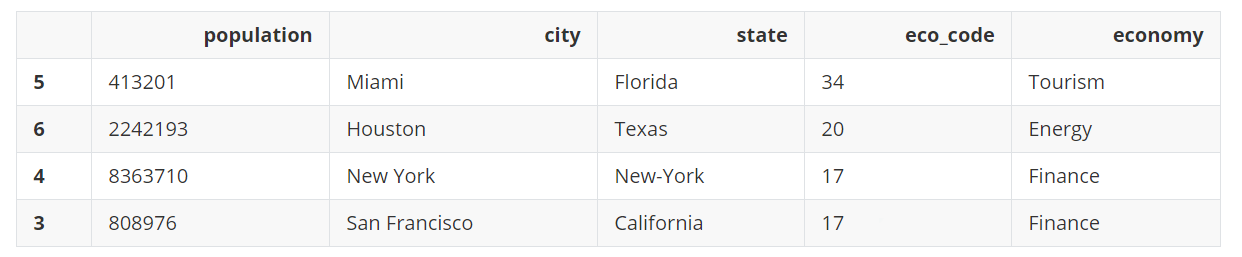















 1196
1196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











