








[医学多模态融合系列 -3] Multimodal Classification: Current Landscape, Taxonomy and Future Directions
这个系列会解读一些列医学多模态融合的文章,了解近在医学领域这两年(2020之后)最新的多模态融合方法.
paper3: Multimodal Classification: Current Landscape, Taxonomy and Future Directions
国内打不开链接,需要原文的链接加v发:liyihao76
0. Abstract
多模态分类研究随着卫星图像、生物识别和医学等领域的新数据集越来越受欢迎。先前的研究表明,与传统的单模态(unimodal data)数据相比,结合来自多个来源的数据的好处导致许多新颖的多模态网络结构的发展。但是,由于缺乏一致的术语和架构描述,因此很难比较不同的解决方案。我们通过提出一种新的分类法来应对这些挑战,该分类法根据最近出版物中发现的趋势来描述多模态分类模型。介绍了如何将这种分类法应用于现有模型的示例以及有助于清晰和完整地介绍未来模型的清单。对于多模态数据集,单模态分类的许多最困难的方面尚未完全解决,包括大数据、类不平衡和实例级难度。我们还讨论了这些挑战和未来的研究方向。
1. INTRODUCTION
在过去十年中,人们越来越关注组合来自多种模式的数据以进一步改进基于机器学习的分类模型。数据对于商业和研究的每个部门都变得越来越重要,这导致创建了更大、更多样化的数据集。不断增加的数据收集率和报告的多模态数据对机器学习模态的好处激发了人们对该领域的兴趣。通过使用来自同一主题的多个表示的信息,可以构建手头问题的更完整的画面。多种数据模式自然存在于许多问题领域,例如医学 [ 27、35、40、49 ] 、超空间图像[ 7 ], 30 ], 情绪分析 [ 14 , 83 , 89 ] 等。
大多数现有的分类算法都是为单模态数据集设计的,单模态数据集代表每个特定问题的单一数据源。这些数据集通常只使用一种数据类型,例如表格、图像或文本,但许多现实世界的场景包括混合类型的数据。价格预测数据集可能包括新闻文章中的文本和财务报告中的表格数据,或者医疗记录可能同时包含基于信号的心脏监测数据和诊断成像。当每个单独的表示与图像-文本、音频-视频或时间不同步的多个传感器等组合显着不同时,组合数据模式可能具有挑战性。这些挑战导致了利用单模态算法来解决多模态问题的解决方案。
对多模态学习的兴趣日益浓厚,导致最近出现了一些涵盖整个领域的调查论文 [ 9、59、122、124 ] ,其中许多调查集中在深度学习 [ 32、77、115 ] 、特定领域的解决方案 [ 7、27、29 ]或非分类方法[ 35、49、78 ]。 虽然这些工作涵盖了多模态学习的广度,但还没有专门调查分类问题及其独特属性的调查。本文遵循以下动机:
(1)缺乏特定的多模态分类法
尽管之前已经提出了几种分类法,但它们都是针对整体多模态学习而不是分类。例如,Baltrušaitis 等人的工作。[ 9 ] 解决了许多类型的学习,例如图像字幕、视频描述、文本到图像的转换、协同训练、迁移学习和零样本学习。虽然该分类法几乎可以应用于任何多模态问题,但它不够具体,无法完全描述最近的多模态分类架构。
(2)识别模型架构的最新趋势
由于之前的调查都集中在多模态学习或特定领域问题的高级方面,因此没有对最近的分类模型及其架构进行审查。需要对架构进行比较,以确定当前趋势以及如何使用通用分类法来描述它们。
(3)提供一种描述多模态分类架构的方法
在审查多模态分类论文时,我们发现分解许多模型架构需要大量工作。每个模型都使用自己的一套术语和表达方法,因此审阅每篇论文都是一种新的体验,这让这个过程变得更加困难。与分类法相结合,需要一个通用的描述性框架来简化模型架构的描述和比较。
(4)讨论未来的挑战
与大数据、分布式计算和困难数据集相关的问题已经通过单模态问题得到了很好的研究,但对于多模态学习的研究却很有限。需要讨论这些挑战如何影响多模态分类。
本文的其余部分组织如下:第2节简要概述了多模态学习和现有领域特定解决方案的示例。第3节描述了多模态分类体系结构和我们提出的分类法,第4节回顾了最近使用这些常用术语的多模态分类研究,这些研究解决了上述动机 1 和 2。第5节给出了如何将分类法应用于动机 3 的现有和未来模型的示例。第6节讨论了动机 4 中提到的多模态问题尚未解决的分类挑战。最后,第7节提供我们的结论性意见。在表1中,我们介绍了本文其余部分中经常使用的缩写列表。
2. PREVIOUS MULTIMODAL RESEARCH
利用来自多个数据源的信息的潜在好处导致许多最近的论文关注多模态学习。在本节中,我们回顾了多模态学习、分类法和特定领域研究的核心概念。
但是,我们必须首先讨论术语terms多模态(multimodal)和多视图(multi-view),因为这两个术语在整个文献中都很常用。这些术语通常可互换使用,作为包含来自多个来源的信息的学习系统,通常是为了与使用单一single(单模态unimodal)数据源的传统问题区分开来。尽管这些术语用于描述明确组合多个数据源的学习模型,但多视图似乎更常与不同类型的算法相关联,例如协同训练 [ 92、124 ]、基于典型相关分析 (CCA)的算法跨模态检索 [ 59 , 124]、半监督[ 124 ]、聚类[ 15、50 ] 、无监督特征选择[ 99、100 ]和子空间学习[ 110 ]。
为了保持一致性,我们选择使用术语多模态multimodal来描述包含来自多个数据源的信息以提高预测性能的学习算法。然后可以将其他用例(例如迁移学习或协同训练)描述为多视图,以提供这些学习方法之间的一些区别。虽然我们相信这些定义对研究界有用,但需要进一步讨论以形成共识。
2.1 Multimodal Concepts
多项调查已将协同训练 [ 92 , 110 , 124 ] 和协同正则化 [ 92 , 124 ] 确定为多模态学习的主要类别。联合训练用于半监督问题,其中存在标记和未标记数据的混合,其中来自一种模态的知识可用于支持在另一种模态上训练的模型。协同训练的潜在应用包括零样本学习、迁移学习和未标记示例的注释。协同正则化转换每个模态以确保它们兼容。这可以通过 CCA 或正则化模态特定分类器等技术来实现。
Baltrušaitis 等人后来提出了一项更全面的工作。[ 9 ] 确定了多模态学习的五个挑战:表示 [ 9 , 122 ]、翻译 [ 9 ]、对齐 [ 9 , 59 , 92 ]、融合 [ 9 , 59 , 92 , 122 ] 和共同学习 [ 9 , 124 ]。还研究了许多其他多模式学习任务,包括半监督学习 [ 92、110、124 ] 、编码[ 25 ]、聚类[92 , 124 ] 和多任务学习 [ 55 , 124 ]。尽管这些调查中有许多涉及分类问题的各个方面,例如对齐和融合,但它们往往涵盖范围更广的主题。
2.2 Taxonomies 分类标准
几篇评论文章提出了分类法,通常针对特定的问题领域。迪米特里等人[ 19 ] 研究了使用多模态数据通过传感器学习人类行为。称为多模式学习分析模型 (MLeAM)的反馈系统使用多模式传感器数据、手动注释和机器学习来指导行为改变。作者还提供了一个树结构分类法,描述了可以使用传感器获取的不同数据源。Garcia-Ceja 等人[ 27 ] 还审查了解决心理健康问题的基于传感器的系统。他们的分类涉及研究类型、研究持续时间和传感类型。
严等[ 115 ]回顾了深度学习背景下的多模态方法。他们的分类法将算法分开,具体取决于它们是原生于深度学习(即 CNN、GAN)还是适用于深度学习的传统机器学习技术(即 CCA、谱聚类)。本综述还讨论了不同的网络融合策略、双峰自动编码器和基于 GAN 的方法。
姜等[ 49 ] 提供了对多模态图像匹配和配准技术的全面回顾,这些技术在多个图像之间关联相同的概念。他们还确定了两大类解决方案:基于区域和基于特征的图像配准。使用整个图像的强度信息来寻找匹配区域,基于区域的方法产生可用于图像配准的变换。基于特征的配准方法包括特征检测(角点、斑点和可学习特征)、特征描述(浮点、二进制和可学习描述符)和特征匹配(图匹配、点集配准、间接方法)。
Ramachandram 和 Taylor [ 77 ] 提供了一个分类法,其中回顾了深度学习多模态研究。在他们的分类法中,模型由它们的输入模态、问题空间、融合方法、模型类型和架构来描述。输入方式包括音频、视频、图像、文本和其他特定于医学领域的方式。问题空间涵盖动作识别、医学诊断和机器人抓取等领域。融合方法描述了来自每种模式的数据是如何组合的,并使用了早期、中期和晚期等术语。模型类型为生成式或判别式,架构定义为实际使用的模型,例如 CNN、RNN 或 LSTM。
接下来,我们将简要概述 Baltrušaitis 等人提出的多模态分类法[ 9 ],其中包括表示、翻译、对齐、融合和共同学习的学习概念。
-
Representation
表示被描述为如何将来自每个模态的数据呈现为特征向量。由于数据可以是文本、图像或视频,潜在的异质性可能会给学习模型带来额外的复杂性。代表挑战被分组为联合或协调 (Joint or Coordinated) 。
联合表示(Joint representations)组合来自多种模态的数据以创建单一表示。这可以通过神经网络通过连接特定于模态的层来创建一个新的隐藏层来实现。概率图形模型(如深度玻尔兹曼机)可用于从潜在空间创建表示,还允许从其中一种模态生成缺失数据。顺序表示用于处理可变长度数据,例如句子或音频剪辑,通常使用 RNN。
使用模态和强制约束之间的相似性来学习协调(Coordinated representations)表示。相似性模型可以强制每个模态的表示彼此接近,例如“汽车”这个词应该更接近于汽车而不是船的图片。结构化坐标空间使用基于散列的压缩,这限制了嵌入式模态数据的放置。 -
Translation
翻译用于将一种模式映射到另一种模式,例如从图像或视频数据生成文本字幕。这些任务被归类为基于示例的或生成的(Example-based or Generative)。
基于示例(Example-based translations)的翻译使用字典查找来查找另一种模态中的匹配值。除了字典之外,k最近邻搜索已被用于执行基于共识的检索。这两种方法都受到它们在训练时拥有的特定模态数据的限制。
生成翻译(Generative translations)可以从源模态创建新的翻译值,而不是简单的检索。基于语法的解决方案可以使用源模态中的高级概念为目标模态创建文本,但只能在预定义的语法规则范围内。编码器-解码器网络对源模态数据进行编码,然后可以将其解码为目标模态中的示例。语音转文本等任务可以通过对两种模态共有的潜在空间进行采样来利用连续生成模态。 -
Alignment
对齐在每个模态之间找到相应的子组件。这通常用于多媒体检索,例如将音频与视频帧同步或标记包含特定个人的图像。对齐技术被标识为Explicit或Implicit。
当目标是基于相关组件对齐多个模态时,使用显式对齐(Explicit alignment)。无监督比对不使用标签,而是依赖于相似性度量,例如匹配基因序列。如果标记了模态对齐,也可以使用监督学习方法。
隐式对齐(Implicit alignment)在特定对齐未知时使用,并已用于语音识别和翻译等任务。一种方法是使用图形模型,其中语言关系的结构被映射到音频数据。使用编码器-解码器和基于注意力的模型的神经网络已被用于使用潜在空间对齐音频-视频数据。 -
Fusion
融合是在应用学习算法之前组合来自多种模式的数据的方法。数据融合是所有多模式方法的核心概念,并分为与模型无关(Model-agnostic)和基于模型(Model-based)的解决方案。
与模型无关的方法使用具有早期、晚期和混合融合技术的单模态分类器,Di Mitri 等人也对此进行了讨论[ 19 ] 和 Simonetta 等人[ 86 ]。早期融合在分类之前结合模态数据,后期融合在结果组合之前执行模态特定学习,混合融合使用两者的组合。
基于模型(Model-based)的方法旨在比与模型无关的方法更直接地解决模态融合问题。在考虑所有模态的同时,多核学习、深度信念网络和神经网络模型都已用于多模态融合。 -
Co-learning
共同学习使用来自一种模式的知识来支持不同模式的学习。这种方法可以通过使用来自另一种模式的高质量数据来解决一种模式中丢失或低质量的数据。共同学习方法被确定为并行、非并行和混合(Parallel, Non-parallel, and Hybrid)。
并行(Parallel )方法使用来自同时跨多个模式共享的示例的数据。协同训练使用来自标记良好的模态的信息来为另一种模态生成缺失的标签。迁移学习可以使用来自一个并行模型的数据来执行新的但相似的任务。
非并行方法(Non-parallel )不需要共享模态示例,而只需要共享概念。与并行模型一样,可以利用迁移学习以及可以识别未见类的零样本学习。概念基础是另一种从公共潜在空间内的多种模态中学习语义的技术。
混合方法(Hybrid)使用两种非平行模态,这些模态使用通用模态或数据集桥接。这已用于多语言图像字幕,其中图像数据在不同的基于语言的模型之间共享。
2.3 Domain-specific Solutions 特定领域的解决方案
多模式学习的常见应用之一是使用高光谱卫星图像进行遥感。该方法使用多种光波长(例如标准 RGB、红外线或 LiDAR 等成像技术)从目标区域收集图像数据。在一篇评论论文 [ 30 ] 中,研究了用于图像分类的多核学习方法。这些内核方法将输入数据映射到一个新的特征空间,然后可以由基于 SVM 的分类器使用,从而产生类似于后期融合架构的东西,如稍后在第3.3节中讨论的那样。Audebert 等人专注于深度学习方法。[ 7] 涵盖了为高光谱分类设计的不同网络。作者观察到,2-D 方法适用于具有空间关系的数据,而 3-D 方法适用于高光谱数据,其中三维表示图像模态。还有人建议,高斯混合模型和 GAN 可用于通过近似嵌入空间来增强训练数据。2017 年 IEEE 地球科学与遥感学会数据融合竞赛的结果表明,顶尖团队都利用了来自多个来源的数据并使用了集成方法 [ 118 ]。
以类似的方式,多模态学习也被应用于医学成像。今天,将计算机断层扫描 (CT)、磁共振成像 (MRI)或正电子发射断层扫描 (PET)等多种图像模式融合在一起以提供用于确定诊断或最佳治疗程序的附加信息是很常见的。Huang 等人审查了许多图像融合架构[ 40 ],他们观察到目前的局限性,即很少有现有的融合方法同时使用两种以上的图像模态。哈斯金斯等人的一项调查[ 35] 还介绍了医学图像融合,同时比较了刚性和可变形配准技术。为了解决用于非线性图像配准的不切实际的图像变形,提出了 GAN,因为它们通常可以学习生成似是而非的合成图像。两篇论文都提到,缺乏标准的评估指标使得图像融合方法的准确评估变得困难。神经影像学领域还利用多模态图像来提高科学理解和诊断性能 [ 18 ],包括两项针对阿尔茨海默病的调查[ 68、80 ]。
另一个非常适合多模式学习的问题空间是人类活动跟踪。随着成本和尺寸的降低,包括麦克风、加速度计和 GPS 在内的可穿戴传感器现在可以实际使用。在一项工作中 [ 76 ],研究了用于活动和上下文识别的深度学习技术。评估了几种具有传统早期和晚期融合方法的神经网络架构,以及不同的特征提取和数据模态组合方法。作者还提到了特征提取的挑战,因为不清楚信号数据是否应该被视为时域点或使用快速傅里叶变换 (FFT)等方法进一步处理。在另一项调查中 [ 27],可穿戴传感器被用于通过传统的机器学习算法监测心理健康状况。基于先前驾驶员压力检测系统中使用的模式,Rastgoo 等人。[ 79 ]提出了一种使用各种类型传感器的多模式框架。
其他特定领域的调查还包括生物识别、3-D 图像分类和音乐信息处理。生物识别领域使用人的特征(例如面部、耳朵或指纹的图像)来识别个人。Oloyede 和 Hancke [ 70 ] 回顾了该领域的不同多模式架构和融合方法。Griffiths 和 Boehm [ 29 ] 还回顾了使用多模式输入进行 3-D 对象分类的工作。通过使用对象的不同表示,例如从多个角度拍摄的二维图像或RGB 加深度 (RGB-D)图像,多模态模型用于识别。除了许多不同网络架构的呈现外,还观察到多模式 2-D 模型可以在 3-D 任务上表现良好,特别是因为预训练的 2-D 网络比 3-D 网络更成熟。张等[ 123 ] 还对使用多模态图像数据(例如 RGB-D)进行图像分割的研究进行了回顾。在音乐处理的背景下,Simonetta 等人[ 86 ]探索了预处理步骤,例如模态同步、特征提取方法以及将多种模态转换为公共特征空间。
3. MULTIMODAL CLASSIFICATION TAXONOMY
多模式学习研究当前面临的挑战是描述学习过程不同方面的术语的广泛组合。之前讨论的许多论文都使用早期、晚期、中间或混合等术语来描述此类架构,但它们的定义并不总是相同的。今天,深度学习方法的从业者立即熟悉用 CNN、GAN 或完全连接的神经网络描述的网络,但多模态分类架构不存在这些类型的描述。对于所有多模态学习系统,先前的分类法往往是特定领域的或通用的,因此它们对任意多模态分类问题的适用性有限。
Ramachandram 和 Taylor [ 77 ] 提出的分类法与分类最接近,但是,它只关注深度学习、早期研究(2011-2016 年),可能不够具体,无法完全描述当前的多模式管道。为了应对其中的一些挑战,我们提出了一种新的多模式分类法,它提供了一组描述性的高级术语,可用于更完整地描述现有或未来的模型架构。表2提供了该分类法使用的五个主要阶段的列表,表3包括在描述多模式架构时需要考虑的其他重要主题。
| Stage | Description | |
|---|---|---|
| 1 | Preprocessing | 这是数据修改的初始步骤,可能包括去除噪声、类平衡或增强。 |
| 2 | Feature Extraction | 在用于直接模型训练之前,从原始输入数据中提取更高级别的特征。此阶段可以包括手动特征工程、文本编码或 CNN 生成的过滤器等方法 |
| 3 | Data Fusion | 此阶段将来自多种模态的原始特征、提取的特征或类别预测向量结合起来,以创建单个数据向量。 多模态模型可以通过它们的架构和数据融合技术进一步定义。 |
| – Fusion Architecture | 描述如何以及何时组合多模态体系结构的模态特定部分。 这些风格可以包括:早期融合、晚期融合和跨模态融合。 | |
| – Data Fusion Technique | 描述如何融合来自每个模态的数据的描述符,包括concatenation和merge。这些融合方法可以应用于传统特征或神经网络节点激活。 | |
| 4 | Primary Learner | 整个学习过程的大部分是在这个阶段进行的,可以为每一种模式独立完成,也可以与特征提取或最终分类器阶段共享。 |
| 5 | Final Classifier | 这个阶段产生最终结果,如预测的标签或类的可能性分数。分类 阶段可以包括从浅层神经网络或决策树到复杂的集合模型的任何东西。 |
| 描述多模态模态时的其他注意事项 | |
|---|---|
| 描述 | |
| Shared Stages | 在某些情况下,同一模型或算法的实例在多个阶段之间共享,如特征提取-初级学习者或初级学习者-最终分类器。这些共享资源在表4和表5中用*标记表示。 |
| Cross-modality Architectures | 这些类型的多模态模型可能相当复杂,可能不适合任何特定的 模式。表2中描述的任务仍然适用,但必须详细描述这些架构的具体内容。架构的细节必须详细描述。 |
根据表4和表5中的审查工作以及自 2017 年以来的调查,我们提出了一个分类法,其中包含用于构建多模态分类模型的五个主要阶段:预处理、特征提取、数据融合、初级学习器和最终分类器。在第4节中,我们介绍了最近使用这些术语的研究,讨论了在单个多模式架构中采用多个架构概念的一些场景,以及确切的架构描述更加主观的场景。
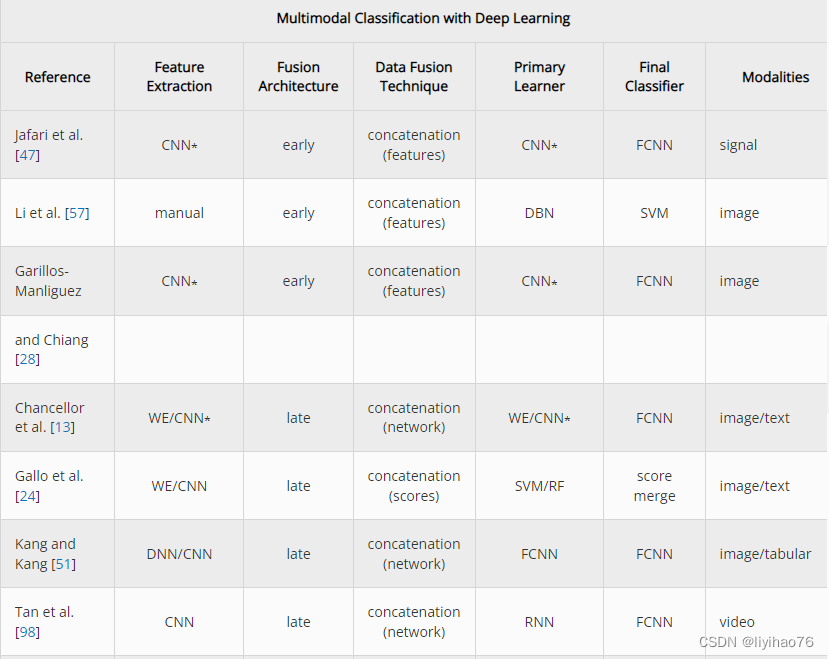
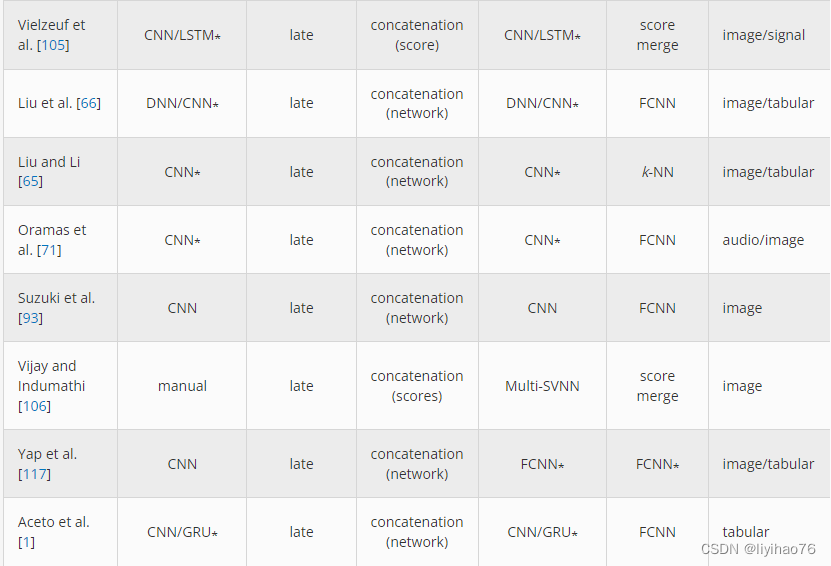
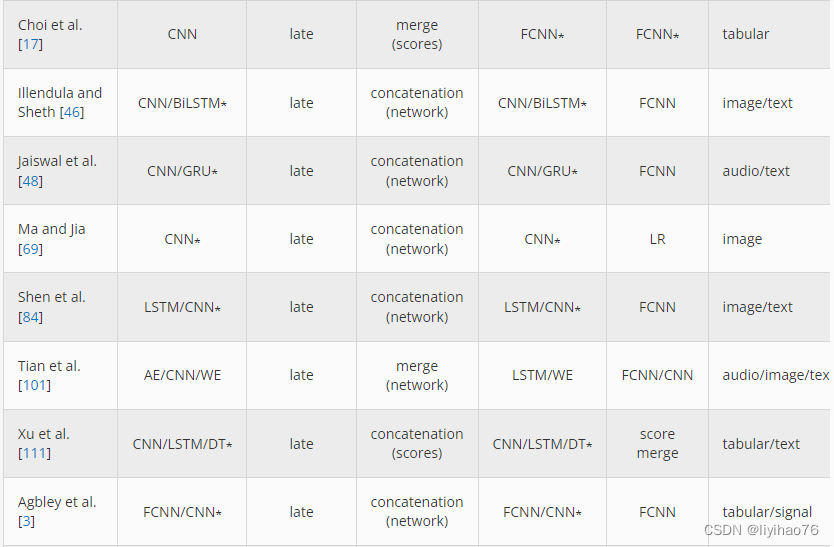
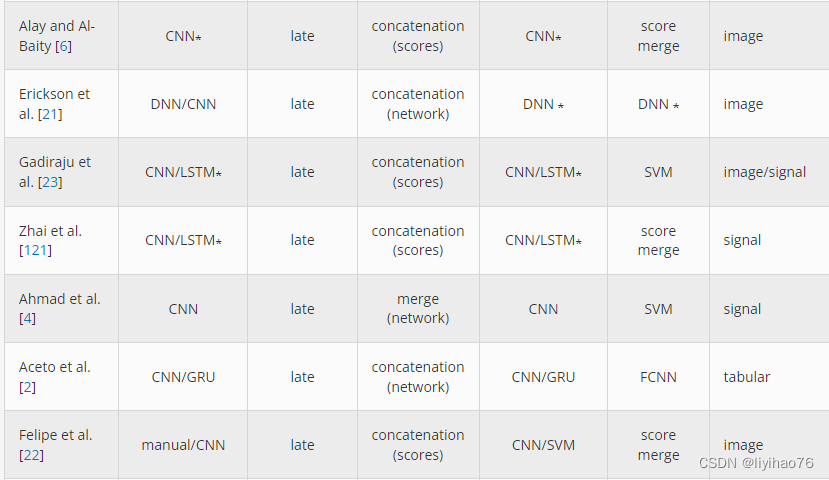
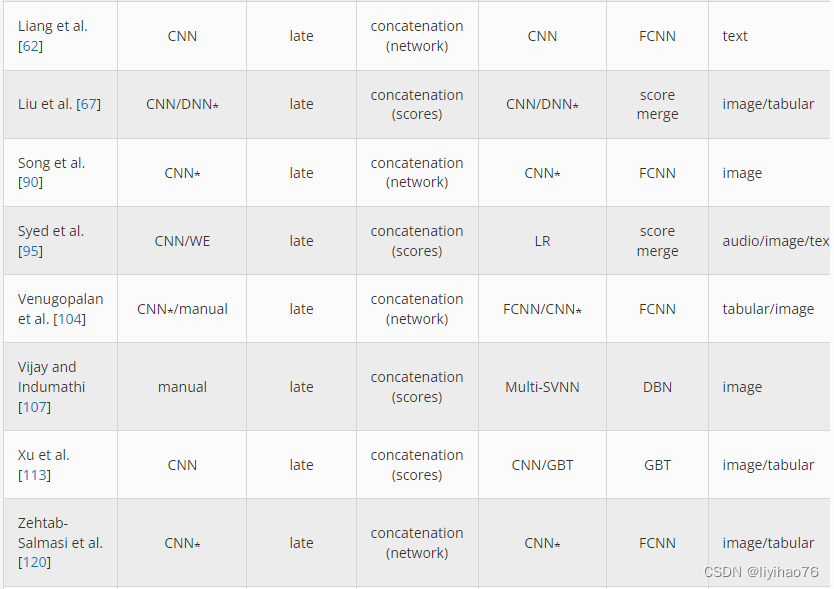
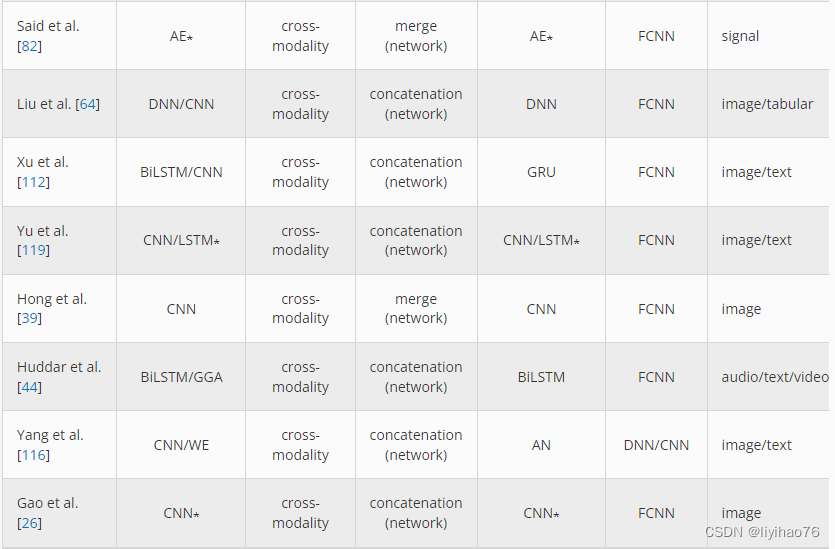
3.1 Preprocessing
尽管并不总是使用,但许多分类模型需要进行一些预处理,无论是处理缺失数据值、裁剪图像、过滤噪声还是类平衡。在这里,我们将预处理描述为一个数据清理步骤,通过一定程度的领域专业知识完成,这些专业知识可能难以在此提议的分类法中概括。虽然有很多方法可以清理单峰数据,但如果每个模态都被独立处理,则多峰数据集可以有更多的选择。例如,如果使用 CT 和 MRI 数据,则可能需要不同的裁剪、缩放和降噪策略。这些图像可能还需要使用刚性或可变形变换进行配准或对齐。但是,可以跳过一种或两种模式的所有预处理,而是使用原始数据。
3.2 Feature Selection
每个多模态分类模型都在某种程度上使用特征选择,这可能包括手动特征工程、深度学习方法,或者是分类器算法的固有部分。特征选择过程可以针对每个模态独立执行,也可以作为整个模型架构中多个步骤的一部分。像 CNN 这样的深度学习方法通常用于特征提取,但同一个网络也可以执行主要的学习步骤,因此可以同时执行两项任务。尽管像随机森林这样的分类器可以通过在决策树创建过程中识别最有用的切点来执行特征选择过程,但该操作可以在一个明确的步骤中执行,例如使用 CNN 进行图像特征提取,然后使用 FCNN 分类器。降维使用主成分分析 (PCA)或线性判别分析 (LDA)可用作特征选择过程的一部分,最常用于传统的机器学习模型,这些模型可能难以处理非常高维的数据。
3.3 Data Fusion
数据融合是多模态学习的一个独特方面,在构建联合模型时需要组合来自不同数据源的信息。这个过程可能发生在输入数据呈现之后,最终分类之前,或者中间多次。这些架构的常用术语包括早期融合或晚期融合,但这些术语可能不足以完全描述多模态模型。由于以前的工作以不同的方式介绍了这些融合方法,我们提出了一系列将在本文中使用的定义。
3.3.1 Fusion Architecture
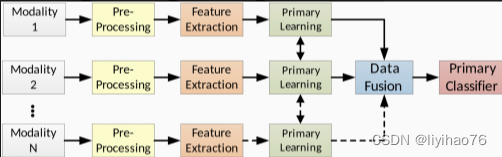
当所有多模态数据在执行主要学习模型之前合并时,就会发生早期融合。如图1所示,来自两个或多个模态的数据被连接起来,然后传递给学习算法。实现这种融合的最常见方法之一是简单地连接传入的模态数据,其中可以包括传统的特征向量或来自预训练神经网络的输出节点。每种模态也可以代表 CNN 模型中的不同通道,当每个数据源之间存在很强的关联时,这种早期融合方法可能是最合适的。例如,具有成像 (CT) 和计划剂量体积的放射治疗数据集可以堆叠为 CNN 通道,因为每种模式通常具有一对一的体素(3-D 像素)关系。如果每种模式代表相同的地面区域,则也可以以类似的方式融合使用不同光波长的卫星图像。 后期融合在最终分类之前对每个模态独立进行特征提取,如图2所示。融合阶段的输出可以包括具有深度网络的低级学习特征或来自完整分类器算法的类别概率。在这两种情况下,学习的结果都会结合起来进行最终分类。这种架构受益于使用特定算法训练每种模态的能力,并且可能使将来添加或交换不同模态变得更加容易。一个缺点是缺乏跨模态数据共享,这可能会阻碍学习模态之间的关系。 跨模态融合允许在初级学习阶段之前或期间共享特定于模式的数据。与早期或晚期融合不同,这种方法提供了一种方法,使每种模式都可以使用彼此的上下文来提高整体模型的预测能力。这种数据共享可以通过多种方式表示,包括在学习过程的不同部分、共享数据的类型或数量,或者哪些模式参与共享。图3显示了在融合之前在每个模态之间共享一次数据的架构,图4显示训练期间多次发生的数据共享。许多发表的论文表明,这种数据共享可以优于传统的早期或晚期融合方法,为解决多模态问题提出了一个有前途的方向。在一项对卫星图像进行分类的工作中 [ 39 ],每种模态都使用 CNN 进行了部分训练,并将结果与来自其他模态的原始数据合并。另一组 CNN 用于继续学习这些组合特征,并在执行最终分类之前再次合并结果。类似于图4中所示的共享样式,Gao 等人提出的模型。[ 26] 多次在并行 CNN 网络之间共享部分学习特征,用于阿尔茨海默病分类。在进行预测之前,将每个特定模式网络的最后阶段的结果连接起来。这种跨模态融合架构通常也用于深度信念网络 (DBN)或自动编码器式网络[ 25、32、59 ]。
当所有多模态数据在执行主要学习模型之前合并时,就会发生早期融合。如图1所示,来自两个或多个模态的数据被连接起来,然后传递给学习算法。实现这种融合的最常见方法之一是简单地连接传入的模态数据,其中可以包括传统的特征向量或来自预训练神经网络的输出节点。每种模态也可以代表 CNN 模型中的不同通道,当每个数据源之间存在很强的关联时,这种早期融合方法可能是最合适的。例如,具有成像 (CT) 和计划剂量体积的放射治疗数据集可以堆叠为 CNN 通道,因为每种模式通常具有一对一的体素(3-D 像素)关系。如果每种模式代表相同的地面区域,则也可以以类似的方式融合使用不同光波长的卫星图像。 后期融合在最终分类之前对每个模态独立进行特征提取,如图2所示。融合阶段的输出可以包括具有深度网络的低级学习特征或来自完整分类器算法的类别概率。在这两种情况下,学习的结果都会结合起来进行最终分类。这种架构受益于使用特定算法训练每种模态的能力,并且可能使将来添加或交换不同模态变得更加容易。一个缺点是缺乏跨模态数据共享,这可能会阻碍学习模态之间的关系。 跨模态融合允许在初级学习阶段之前或期间共享特定于模式的数据。与早期或晚期融合不同,这种方法提供了一种方法,使每种模式都可以使用彼此的上下文来提高整体模型的预测能力。这种数据共享可以通过多种方式表示,包括在学习过程的不同部分、共享数据的类型或数量,或者哪些模式参与共享。图3显示了在融合之前在每个模态之间共享一次数据的架构,图4显示训练期间多次发生的数据共享。许多发表的论文表明,这种数据共享可以优于传统的早期或晚期融合方法,为解决多模态问题提出了一个有前途的方向。在一项对卫星图像进行分类的工作中 [ 39 ],每种模态都使用 CNN 进行了部分训练,并将结果与来自其他模态的原始数据合并。另一组 CNN 用于继续学习这些组合特征,并在执行最终分类之前再次合并结果。类似于图4中所示的共享样式,Gao 等人提出的模型。[ 26] 多次在并行 CNN 网络之间共享部分学习特征,用于阿尔茨海默病分类。在进行预测之前,将每个特定模式网络的最后阶段的结果连接起来。这种跨模态融合架构通常也用于深度信念网络 (DBN)或自动编码器式网络[ 25、32、59 ]。
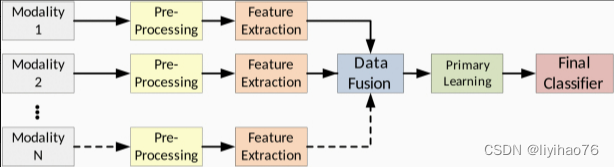
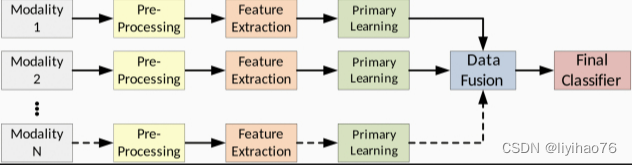

3.3.2 Data Fusion Technique
基于我们对以前工作的回顾,我们将数据融合技术分为级联(concatenation)和合并(merge)融合技术。图5显示了这些常用样式的可视化表示。
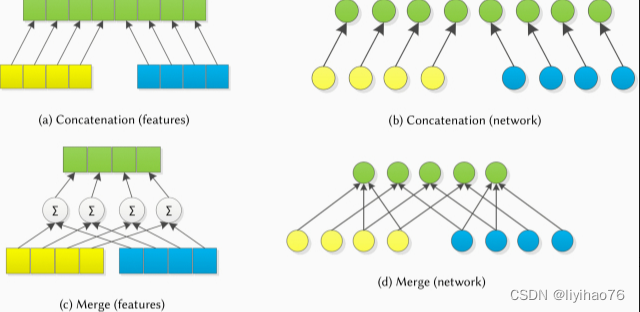
Concatenation: 这种数据融合方法只是将模态数据串联起来形成一个单一的特征向量。使用此技术时,输入数据可以是原始特征、类别似然向量或神经网络节点。图5 (a) 显示了传统机器学习特征的连接示例,图5 (b) 显示了神经网络节点。
Merge: 这种方法将模态数据与业务逻辑相结合,比简单的连接更复杂。合并过程通常使用算术运算符对传统特征执行(表示为 Σ \Sigma Σ) 将输入值转换为新的特征向量,如图5( c )所示。神经网络合并将特定模式的节点连接到输出合并层,该层利用网络权重和偏差来组合特征,如图5 (d) 所示。尽管合并技术通常会像编码器一样产生较少的输出特征或节点,但它也可以用作解码操作的一部分。
3.4 Primary Learner
每个传统的机器学习或深度学习系统都旨在从训练数据中提取知识,通常作为网络权重、决策边界或分裂标准。多模式管道可以通过多种方式执行此学习过程,这需要明确的解释以支持未来的进步和实验的复制。例如,早期融合模型会生成一个单一的连接数据源,因此所有模态的学习过程都可以同时发生。然而,后期融合对每个模态进行独立学习,而跨模态模型可以多次执行学习过程。初级学习阶段执行的工作也可以与特征提取或最终分类器共享阶段,这将在第3.6节中进一步讨论。
3.5 Final Classifier
与Primary Learner阶段不同,Final Classifier用于生成多模态流水线的最终结果,通常是预测标签或类似然向量。用于此阶段的算法可以与用于Primary Learner的算法相同,完全不同的算法,或者可以在两个阶段之间共享工作。此阶段使用的算法范围从单个 softmax 层到整个集成模型。我们认为,明确定义此阶段可以更轻松地描述未来研究人员可以实施的新模型的整体多模式架构。
3.6 Stage Sharing
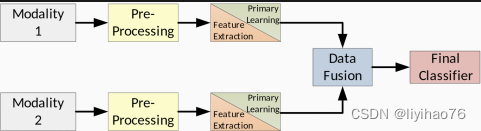
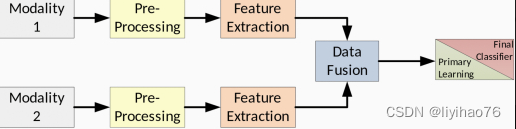
在许多真实场景中,我们的分类法中的各个阶段使用相同的模型。图6显示了后期融合架构的示例,其中每个模态使用相同的模型执行特征提取和学习。这通常是通过 CNN 完成的,如后面的表5所示。图7显示了早期融合架构,其中学习和分类是使用单个模型执行的。这是在大多数传统机器学习模型中完成的,因为提取的特征被连接起来并传递给单个分类器。
4. REVIEW OF RECENT MULTIMODAL CLASSIFICATION RESEARCH
在本节中,我们回顾了最近关于多模态分类的工作。表4和表5使用先前定义的分类法提供了一系列模型及其架构设计。该审查过程用于发现不同多模式分类方法之间的模式和共性,以便创建分类法。我们将传统的机器学习和深度学习作品分开,因为它们倾向于使用不同类型的架构。第4.3节更详细地讨论了这些差异和其他观察结果。
只有自 2017 年以来发表的论文才被认为使这个提议的分类法专注于最先进的作品,尤其是与快速发展的深度学习领域相关。我们在文献检索过程中考虑了 400 多篇论文,最终选择了 121 篇论文,其中包括调查、多模态分类模型以及与未来挑战相关的主题。缺少分解所需细节的已发布模型被排除在外。在一篇论文提出多个模型的情况下,我们选择给出最佳整体结果的模型,并且为了清楚起见,一些模型类型(如 CNN)被赋予了它们的通用名称,而不是它们的具体实现或使用的预训练模型。确定这些模型的确切模型配置可能会有不同的解释,但我们选择了最符合我们提出的定义的描述。在这些表中(表4和5),* 标记用于标识同一模型共享两个阶段的情况。
4.1 Traditional Machine Learning
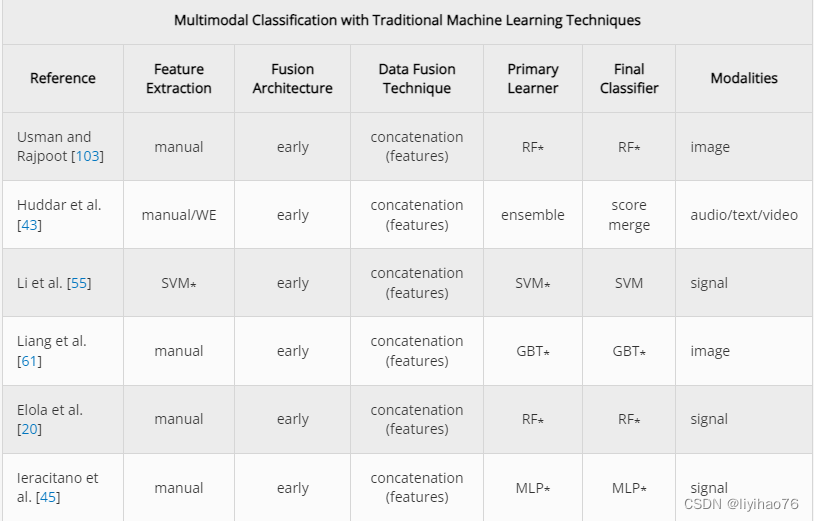
4.1.1 Early Fusion
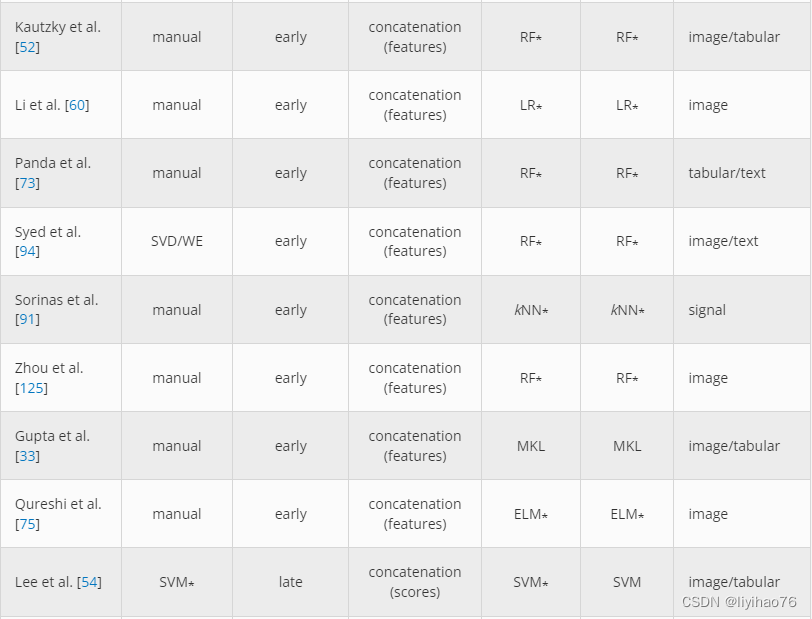
由于许多传统的机器学习分类器容易受到维数灾难 [ 10 ] 的影响,因此通常对高维数据执行显式特征提取。这种方法允许使用最近提出的多模态模型中经常出现的 2-D 和 3-D 成像数据。例如,Usman 和 Rajpoot [ 103 ] 使用随机森林分类器从四种 MRI 模式中提取成像特征来预测脑肿瘤状态,Zhou 等人[ 125 ] 使用基于 MRI 的特征对脑肿瘤进行基因分型。考茨基等人[ 52 ]通过使用 49个感兴趣区域 (ROI)开发了注意力缺陷多动障碍 (ADHD)诊断工具具有正电子发射断层扫描 (PET)图像和 30个基于单核苷酸多态性 (SNP)的特征的特征。赛义德等人。[ 94 ] 为放射肿瘤学领域中使用的医学数字成像和通信 (DICOM)结构集的自动标准化建立了预测模型。使用奇异值分解 (SVD)并将每个描绘结构的 3-D 表示减少到 50 个特征,并结合来自相关文本注释的词嵌入特征。在使用随机森林分类器之前,将两组特征向量连接起来。随机森林还与来自自动体外除颤器的数据一起使用,这些数据提供心电图 (ECG)、胸阻抗 (TI)和二氧化碳图信息 [ 20 ]。所提出的模型是基于时间序列的,并且在数据融合之前执行了手动特征工程。熊猫等。[ 73 ] 使用脑电图 (EEG)和客户评论文本来预测情绪反应。来自两种模式的数据在被传递到随机森林分类器之前被编码到一个共享的特征空间中。
尽管随机森林是最常用的传统分类器,但其他算法也被证明是有效的。例如,李等人[ 60 ] 使用线性回归分类器从局部晚期直肠癌患者中提取了 396 个 CT 和 MRI 放射组学特征,用于预测新辅助化疗后的治疗反应。使用梯度提升树 (GBT)分类器,Liang 等人[ 61 ] 使用结构磁共振成像 (sMRI)和基于扩散张量成像的特征预测精神分裂症患者。李等[ 55 ] 开发了一种基于支持向量机 (SVM)的多模态模型,用于人类活动和跌倒检测,使用惯性测量单元 (IMU)和雷达。然而,这项工作使用了分层分类方法,其中将特征的子组分组以预测子活动。为了区分患有轻度认知障碍、阿尔茨海默病或没有神经系统疾病的患者,Ieracitano 等人[ 45 ] 使用了来自 EEG 记录的连续小波变换 (CWT)和双谱 (BiS)数据。实验结果表明,MLP 在具有这些级联特征的情况下优于 AE、LR 和 SVM 分类器。Huddar 等人没有使用单个分类器[ 43] 建立了一个由五个单独的分类器组成的集合。这项工作使用了经过大量预处理和特征选择的转录、音频和视频数据。因为主要学习是使用融合的多模态数据完成的,所以我们选择将其视为早期融合架构。
Qureshi 等人使用极限学习机 (ELM)分类器。[ 75 ]建立了一个模型来辅助诊断精神分裂症。从结构和功能 MRI 扫描中提取的特征被组合在一起,以创建单独训练的新数据模式。基于它们各自的预测能力,每种模态都被赋予了一个权重,用于最终的多模态分类步骤。古普塔等[ 33 ] 创建了一个预测模型,用于区分健康患者与患有阿尔茨海默病或轻度认知障碍的患者,其中在使用多核学习 (MKL)进行分类之前,将基于转换图像和载脂蛋白 (APOE)基因型的特征塑造到核空间中算法[ 5 ]。索里纳斯等人[ 91 ] 还使用k-最近邻 ( k NN)分类器和从脑电图、心电图和皮肤温度数据中手动提取的特征来预测对视频的情绪反应。
4.1.2 Late Fusion
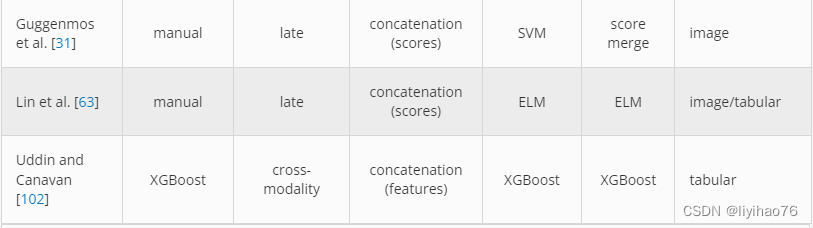
在 Guggenmos 等人的工作中。[ 31 ],五种神经影像学方法被用于对精神疾病进行分类。每种模式都使用 SVM 和加权稳健距离 (WeiRD)分类器进行独立训练。该模型还使用了一种优化方法,其中为每种模式选择了最佳分类器和超参数。使用来自每个模态特定分类器的结果的加权平均值进行最终分类。李等[ 54 ] 还使用 SVM 进行特征提取和分类,以使用脑成像和心率数据预测临床疼痛状态。为了区分健康患者和患有阿尔茨海默病或轻度认知障碍的患者,Lin 等人[ 63] 使用 MRI、氟脱氧葡萄糖正电子发射断层扫描 (FDG-PET)、脑脊液 (CSF)和 APOE开发了一个预测模型ε4 基因数据。与前两种方法不同,该模型使用了 ELM 分类器 [ 41 ],它是传统 SVM 算法的变体。
4.1.3 Cross-modality Fusion
Uddin 等人将多层模型与 XGBoost 结合使用。[ 102 ] 作为 EmoPain 2020 Challenge [ 8 ]的一部分,建立了慢性背痛存在的预测因子。在每一层,对背痛的某些方面进行分类,然后将所得类别概率与现有特征向量合并。这种融合方法与早期和晚期融合架构有一些相似之处,但具有逐步更新特征向量的独特特性。
4.2 Deep Learning
4.2.1 Early Fusion
Jafari 等人同时使用专用集成电路 (ASIC)和基于现场可编程门阵列 (FPGA)的硬件平台。[ 47 ] 使用来自可穿戴传感器的时间序列数据通过 CNN 检测人类活动。传感器数据被转换为单通道图像,每个传感器一行,每列作为时间序列点。使用可见光和高光谱成像,Garillos-Manliguez 和 Chiang [ 28 ] 创建了一个用于对木瓜果实成熟度进行分类的多模式网络。在使用 CNN 进行训练之前,生成的 RGB 和高光谱图像数据被堆叠为单独的列。李等。[ 57] 使用多模式卫星图像来预测土地覆盖类型。对每个图像模态进行预处理,并将生成的像素堆叠到 DBN 的单个输入向量中。然后使用具有学习到的深层特征的 SVM 进行分类。
4.2.2 Late Fusion
生物识别系统可以通过多种验证方法提高安全性。在 Vijay 和 Indumathi [ 106 ] 的工作中,使用了耳朵和手掌静脉图像,并使用多支持向量神经网络 (Multi-SVNN)分类器对每种模式进行了特征提取。在优化模型权重后,使用模态特定分数的总和进行最终识别检查。这项工作后来被扩展 [ 107 ] 使用指关节、耳朵和虹膜图像数据。尽管 Mutli-SVNN 再次用于学习每种模态,但 DBN 用于分类。Alay 和 Al-Baity [ 6] 还构建了一个带有虹膜、面部和手指静脉图像的生物识别分类器。所有三种模式都使用 CNN 进行训练,并且它们的输出通过 softmax 层传递。这些值在使用算术平均值或乘积规则组合之前进行归一化,并为预测类别选择最高值。
在 Aceto 等人的工作中[ 1 ],作者开发了一个名为 MIMETIC 的多模式框架,用于对网络流量进行分类。从每种模式中,数据是从网络跟踪中提取的,并使用 CNN 或门控循环单元 (GRU)模型进行独立训练。最终层与 FCNN 层连接和分类。这项工作后来被扩展为使用称为 DISTILLER [ 2 ] 的新框架来支持多任务分类。这种方法在初始模态连接后在共享 FCNN 层上进行训练,但为了训练特定于任务的层再次拆分特征。
医学领域使用来自许多潜在来源的数据,包括成像、文本注释和离散信息,使其成为多模态学习的自然领域。在 Said 等人的工作中。[ 82 ],建立了一个 AE 网络,用于对脑电图和肌电图 (EMG)数据进行分类。每种模态都有自己的合并 AE,并且通过微调 softmax 函数作为网络瓶颈来执行分类。谭等[ 98 ] 从脑电图和光流时间数据预测认知事件。两种模式都使用 CNN 进行训练,并在使用 RNN 进行分类之前重塑为二维特征向量。Venugopalan 等。[ 104] 使用 MRI、SNP 和临床数据来预测认知障碍。这些模态使用 CNN 和 AE 进行训练,它们的输出层连接在一起并使用两层 FCNN 进行分类。
使用心血管和活动记录传感,Zhai 等人[ 121 ] 建立了一个预测睡眠周期的整体模型。为两种传感器类型选择了三个不同的时间窗口,并分别在 CNN 和 LSTM 模型上对组合数据进行了训练,从而产生了总共六个分类器的集合。所有的后验概率都被添加到一个分类矩阵中,最终的分类是用最高的平均值或 argmax 值进行的。Ahmad 等人使用来自 ECG 数据的三种派生图像模式。[ 4 ]开发了一个心跳分类模型。每种模态都在 CNN 上进行训练,对结果求和,并选择 SVM 进行最终分类。Agbley 等人使用了临床和咳嗽音频数据。[ 3] 来预测 COVID-19 感染。音频数据被转换为二维尺度图并使用 CNN 进行训练,而临床数据则使用 FCNN 进行编码。合并最后的层,并使用密集层和 softmax 进行分类。
刘等人[ 67 ] 使用基因组数据和病理图像来预测乳腺癌亚型。在主成分分析 (PCA)执行特征缩减后,基因组数据使用 FCNN 进行训练,图像数据使用 CNN 进行训练。宋等[ 90 ] 使用来自对比增强光谱乳腺 X 线摄影 (CESM)扫描的两种图像模式来检测乳腺癌。每种模态都使用 CNN 进行训练,最后一层连接起来用于使用两个 FCNN 层进行分类。对于皮肤损伤分类,Yap 等人。[ 117 ] 将 CNN 生成的特征与表格临床数据相结合,并使用三层 FCNN 进行分类。马和贾[ 69] 使用 MRI 和病理图像来预测脑肿瘤的癌症阶段。两种模式都使用 CNN 进行分类,并且它们的最后一层被连接起来并使用 LR 分类器进行分类。
Liu 等人使用地面云层图像和天气信息。[ 66 ]创建了一个联合融合卷积神经网络(JFCNN)。图像数据使用 CNN 进行训练,天气数据使用解码器类型 FCNN 进行训练以进行特征学习。最后的层被连接起来并用一个联合 FCNN 层进行分类。JFCNN 后来与 GAN 生成的人工示例一起使用,以增加训练数据集的大小 [ 65 ]。铃木等[ 93 ] 使用机载图像和地理空间特征对森林覆盖进行分类。每种模态都使用 CNN 进行训练,结果使用 CNN 和 FCNN 层进行分类。许等。[ 113] 使用图像和表格访问数据进行城市功能区分类。从图像和区域访问信息中学习到的特征使用 GBT 进行训练,并且它们的类别概率使用 softmax 层进行分类。
大臣等[ 13 ] 使用文本和图像数据来检测 Tumblr 上的进食障碍政策违规行为。文本是使用带有完全连接层的标签嵌入和带有 CNN 的图像数据进行训练的。将生成的层连接起来并使用两层 FCNN 进行分类。在 Illendula 和 Sheth [ 46 ] 的工作中,建立了一个模型来使用图像和文本预测社交媒体帖子的情绪。图像数据用 ResNet [ 37 ] 分类,文本数据用 BiLSTM 分类,最终分类用 softmax 层进行。赛义德等人[ 95],使用音频、文本和图像数据来预测公众对政客的信任程度。对每种模态使用 CNN 和词嵌入模型,使用多数投票或总置信度分数进行最终分类。
加洛等[ 24 ] 使用图像和文本标签预测真实世界的对象。CNN 用于学习图像特征,词袋方法用于文本。实验表明,带有图像的 SVM 和用于文本的随机森林可获得最佳性能。Erickson 等人使用了视觉和近红外光谱图像。[ 21 ] 用于帮助机器人与物体交互。图像数据使用 FCNN 进行训练,最后一层在分类之前与另一个两层 FCNN 连接。
维尔泽夫等人。[ 105 ]使用视频帧和音频数据对视频剪辑中表达的情感进行分类。使用基于 CNN 和 RNN 的网络,每种模态的最终值均使用加权平均值进行评分。在 Oramas 等人的工作中。[ 71 ],音频和专辑封面艺术被用来预测音乐流派。每种模态都使用一个 CNN 和两个 FCNN 层进行训练,最终结果使用余弦损失函数进行分类。田等[ 101 ]使用音频、视频帧和文本描述来识别不同类型的自然灾害。使用 AENet [ 97 ] 提取音频,使用 Inception v3 [ 96 ] 提取视频数据,使用 GloVe [ 74 ] 进行文本嵌入]. 音频和视频特征使用 LSTM 和基于 SVM 的顺序最小优化 (SMO)算法进行训练,文本特征使用一维 CNN 和用于分类的 softmax 层进行训练。由于许多视频帧中不存在一些视频概念,因此文本模型用于不太常见的概念,而不是联合音频视频。
Kang 等人构建了 FCNN 多模态网络[ 51 ] 使用空间、时间和环境数据预测犯罪事件。每种模态都使用 FCNN 进行训练,最后的层被连接起来,并使用两个带有 softmax 的密集层进行分类。Shen 等人使用维基百科文档的文本和视觉呈现。[ 84 ]建立了一个模型来预测文档质量。使用 BiSTLM 对文本数据进行分类,对图像数据使用 Inception v3 对图像数据进行分类。使用密集层和 softmax 组合最终结果。Zehtab-Salmasi 等人[ 120] 使用设备图像及其离散属性预测智能手机价格。每种模态都用 CNN 进行训练,输出层被展平、连接,并用另外三个 FCNN 层进行分类。EmbraceNet [ 17 ] 框架旨在接受来自任何类型输入模式的数据。此方法使用对接层将来自模态特定网络的数据嵌入到公共长度向量中。使用多项式分布从对接输出构建单个包含向量,因此每个特征仅由单一模态填充。
多模式学习的另一种方法是从相同的训练数据创建不同的特征集。例如,梁等人[ 62 ] 通过使用空间视图注意卷积神经网络 (SVA-CNN)框架将数据拆分为短语、单词、n-gram 或其他粒度,将文本表示为不同的模式。该架构旨在保留这些文本表示之间的关系。使用上下文关注、并行连接和串行连接 CNN 子网络,将输出卷积层连接起来并使用 FCNN 进行分类。同样,Felipe 等人[ 22] 还根据大鼠的肠神经系统图像创建了几种数据模式。结合手工制作和模型生成的图像特征,对几种慢性退行性疾病进行了分类。
4.2.3 Cross-modality Fusion
Liu 等人使用图像和离散气象站数据。[ 64 ]建立了一个系统来预测云类型。低级特征是通过图像的 CNN 和离散数据的全连接网络学习的。这些特征与另一个完全连接的网络相结合以进一步学习,并且在最终分类之前将产生的新特征与先前学习的特征相结合。该网络设计包括多模态跳跃连接,类似于 ResNet [ 37 ] 等神经网络架构中的连接。
余等[ 119 ]使用图像和文本建立了一个分类网络,用于基于社交媒体的情感分析。首先,使用具有平均池化的 LSTM 从文本中提取目标实体信息。这些结果与在图像数据上训练的 CNN 以及在其他两个 LSTM 上训练的文本上下文信息相结合。几个不同的融合特征组合被连接起来用于 softmax 分类。这种方法允许不同的模式从其他模式中学习信息。
Hong 等人使用了不同的图像模式。[ 39 ] 预测土地覆盖,他们测试了多种融合网络架构。除了早期和晚期融合的版本之外,还使用编码器-解码器和模态共享方案研究了更高级的架构。最好的结果来自后一种方法,它也使用合并融合风格来压缩多模态数据而不是连接。
Yang 等人建立了一个基于文本和图像的情感分析网络。[ 116 ]结合文本嵌入和提取的图像特征,并在基于多模态 CNN-LSTM 的注意力网络上对其进行训练。这些网络的结果被连接起来并使用 softmax 进行分类,以预测社交媒体帖子中表达的情绪。
为了预测阿尔茨海默氏症等脑部疾病,Gao 等人[ 26 ] 使用具有路径传输网络的成像数据,其中部分提取的特征在模态之间共享。在网络的每一层,来自每个模态的权重被连接和卷积,然后再次与原始模态输出连接。这个过程允许在每个特定于模式的网络之间持续共享信息。在分类步骤中,每种模式的最终结果再次与 CNN、dense 和 softmax 层连接和微调。此外,这项工作使用 GAN 创建人工示例来解决其中一种图像模态缺失的情况。
在 Huddar 等人的一项工作中。[ 44 ],创建了一个多模式网络,用于使用音频、视频和文本数据进行情感分析。使用基于贪婪搜索的遗传算法 (GGA)对每个模态独立执行特征选择,然后使用 BiLSTM 模型进行上下文提取。然后将单峰结果连接起来形成三个新的双峰特征向量,代表音频-视频、文本-视频和文本-音频组合。对这三种模式执行了相同的 GGA/BiLSTM 过程,结果向量再次连接成单个特征向量。最后,使用 GGA/BiLSTM 再次处理组合向量,然后使用 softmax 分类器。
多交互记忆网络(MIMN) [ 112] 的开发是为了根据相关的图像和文本信息预测情感标签。特征提取是通过文本数据的词和短语嵌入和图像数据的 CNN 进行的。来自每种模态的特征在被两个并行记忆网络使用之前由它们自己的 LSTM 进一步处理,一个用于文本,另一个用于图像数据。每个网络都有多个块,包括一个 GRU 和一个注意力机制。第一个块接受其匹配的图像或文本 LSTM 特征向量以及来自方面向量的平均池,并返回 GRU 的输出。在以下块中,输入是匹配的 LSTM 向量和来自另一个并行网络的 GRU 输出向量,提供来自其他模态的上下文。
4.3 Observations
从我们的文献搜索中,我们已经确定了一些趋势,包括使用特征提取、融合架构和模型共享。很明显,目前多模态分类的重点是深度学习,尽管仍在进行基于传统机器学习的新研究。表6提供了机器学习和深度学习模型之间的一些比较,以及每种模态、融合方法和模型共享方法的使用频率。
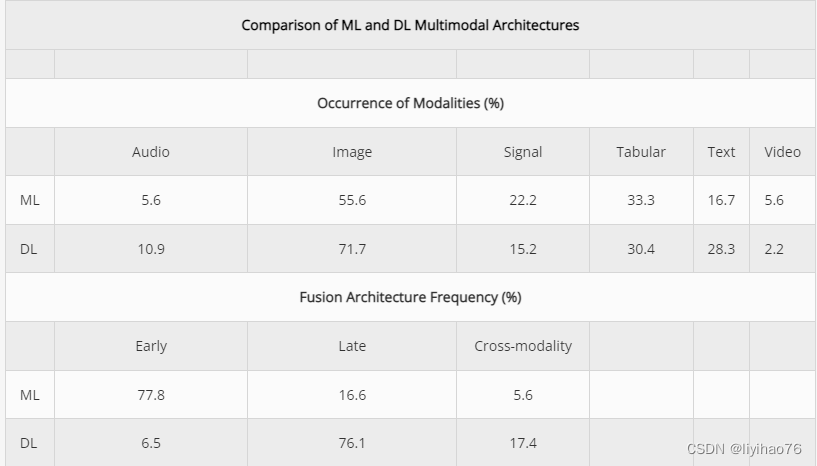
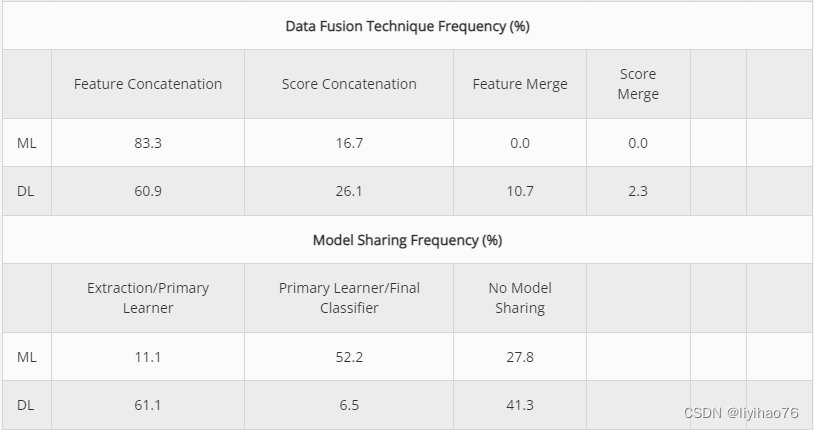
与深度学习相比,传统的机器学习模型主要使用人工特征提取。早期融合类型用于 18 个传统机器学习模型中的 14 个,可能是因为这些分类器期望将单个特征向量或矩阵作为输入,并且不提供在训练期间进一步扩充数据的方法。出于同样的原因,这些模型都使用简单的多模态特征连接。大多数作品也使用相同的算法进行学习和分类,除非它是多任务问题或使用集成,因为主要学习者-最终分类器阶段在 18 个模型中的 11 个中共享,而特征提取-主要学习者只有两次阶段。随机森林、GBT 和 XGBoost 等基于树的算法是最流行的分类器。机器学习模型中使用了所有主要数据类型,但图像是最常见的。
在深度学习相关的论文中,3篇使用了early fusion,8篇使用了cross-modality fusion,35篇使用了late fusion,颠覆了传统的机器学习著作。特征提取通常依赖于数据类型,CNN 是迄今为止最受欢迎的方法,其次是 RNN,例如 LSTM 和 GRU。深度学习早期融合模型的架构设计与使用机器学习的模型相似,最大的区别在于所使用的各个算法。
使用后期融合的模型独立执行大量模态训练,这允许在深度学习解决方案中使用预训练模型。这也支持为每个特定模态使用根本不同的模型,例如用于图像的 CNN 和用于文本的 LSTM。级联仍然是最流行的数据融合技术,但也使用了节点合并。在大多数后期融合模型中,使用浅层神经网络和 softmax 层作为最终分类器。
虽然跨模态融合仍然不是最常用的方法,但它的受欢迎程度可能会增加,因为它在深度学习模型中更为突出。这些架构往往比早期或后期融合更复杂,但已经表明性能可能更优越。目前,多模态学习缺乏可用于单模态学习的大型预训练网络,例如 ResNet、Inception v3 或 VGG [ 87 ]。如果性能最好的跨模态架构可以在非常大的数据集上进行预训练,那么生成的模型将为未来的工作提供显着的好处。
这些先前的工作也出现了几个子网络模式。最常见的架构是用于特征提取的共享 CNN -初级学习阶段,然后是 FCNN 和 softmax 分类器。与传统机器学习不同,深度学习架构倾向于使用特征提取-初级学习器阶段共享,这发生了 24 次,而初级学习器-最终分类器组合仅发生了 3 次。在每种模式使用不同网络类型的情况下,CNN 和 RNN 网络通常会配对使用。
使用Primary Learner阶段模型作为完整分类器的架构更有可能使用分数合并作为最终分类器方法而不是 FCNN。这种方法可能经常被使用,因为简单地将单个 softmax 层应用于预训练模型输出很方便。然而,未来的工作需要确定该方法是否优于使用早期层作为融合阶段的输入。
5. APPLYING THE TAXONOMY 应用分类法
5.1 Challenges with Model Descriptions
虽然多篇论文 [9、18、38、42、77、86、123] 对早期和晚期融合风格的描述相对一致,但仍有使用其他术语的情况。在郭等人的工作中。[ 32 ],一种被描述为多视图一个网络的网络架构本质上是早期融合,而一个视图一个网络可以被认为是后期融合。李等[ 58 ] 提供了一种视图特征提取架构,可以通过使用不同的学习器和分类器模型映射到我们的后期融合分类法。高等[25 ] 将早期融合描述为阴影多模态,将晚期融合描述为深度多模态。对于跨模态风格的架构,Ramachandram 和 Taylor [ 77 ] 以及 Syed 等人。[ 94 ] 使用术语中间体,而 Gao 等人[ 25 ] 使用深度共享模式。在 Gao 等人的调查中[ 25 ],作者还使用深度跨模态来描述多任务架构,但这些术语用于生成模型的上下文中,例如受限玻尔兹曼机 (RBM)。Oloyede 和 Hancke 描述了更具体的模型 [ 70] 包括决策级的融合(后期融合,分数合并),匹配分数级的融合(后期融合,使用不同的学习器/分类器),传感器级的生物特征(早期融合)和特征级的融合(后期融合,特征连接)。以类似的方式,Yaman 等人[ 114 ]使用术语数据融合(早期融合)、特征融合(后期融合、特征合并)和分数融合(后期融合、分数合并)。
术语中间体已用于跨模态融合,但也可以指代发生在特征提取和分类之间某处的融合 [ 17 ]。middle [ 39 ]、joint [ 42 ] 和hybrid [ 123 ]等术语] 也被用来描述这种融合。由于我们提出的分类法基于五个处理阶段,因此中间融合概念可以通过早期或晚期融合风格的架构来捕捉。这允许跨模式融合仅描述跨模式数据共享概念。这些例子只涵盖了所有现有作品的一小部分,因此很可能存在许多其他多模态分类架构的描述。使用我们提出的分类法,我们能够用一致的术语标记各种模型。
5.2 Describing Multimodal Classification Models 描述多模态分类模型
我们在审查以前的作品时面临的挑战之一是,除了不一致的术语外,许多出版物没有提供足够的信息来自信地重建他们的过程。为了解决这个问题,我们在表7中提供了一个清单,它可以帮助确保多模态分类模型的关键方面以明确定义的术语完整呈现。
| 描述多模式分类架构的清单 | |
|---|---|
| Model Property | Description |
| Input Data | 描述每种模式的数据类型和属性及其对模型性能的潜在好处 |
| Preprocessing | 根据具体情况,详细说明对每种模式执行的任何预处理. 讨论任何数据集级别的修改,例如类平衡、规范化或插补 |
| Feature Extraction | 列出特征提取的方法(如手工特征工程、模型学习的特征)以及这种选择的目的. 用于主要学习者步骤的模型的描述,包括任何相关设置,例如超参数、辍学率或正则化 |
| Data Fusion | 描述何时在架构中执行数据融合(早期、晚期、跨模态). 描述如何进行数据融合(串联、合并) |
| Cross-Fusion | 如果进行了跨模态融合,则用匹配图详细描述这个过程. |
| Primary Learner | 用于主要模型步骤的模型的描述,包括任何相关设置,例如超参数、丢失率或正则化 |
| Final Classifier | 用于分类器步骤的模型的描述,包括任何相关设置,例如超参数、丢失率或正则化. 解释输出格式(二元或多类标签、类概率) |
| Shared Stages | 描述在多个架构阶段之间共享的任何模型 |
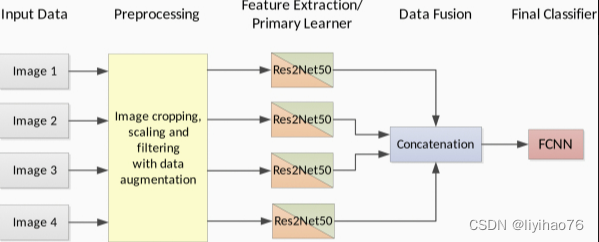
除了用文本描述模型架构外,视觉描述也很有用。在图8和图9中,我们展示了如何使用网络架构图将第3节中定义的分类法应用于先前发布的模型。图8显示了 Syed 等人开发的 ML 架构。[ 94 ] 预测放射治疗结构的名称基于 3-D 体积和医生提供的标签。预处理和特征提取步骤显示了每种模式的不同技术。然后使用连接执行数据融合,随机森林算法在主要学习者之间共享和最终分类器步骤。图9显示了 Song 等人提出的 DL 方法。[ 90 ] 用于对乳腺癌进行分类。所有四种输入数据模式都是患者医学成像的不同表示,并且它们都接受相同的预处理操作。使用Res2Net50 模型为每个模态独立执行特征提取和主要学习者步骤。在应用最终分类器之前,为数据融合步骤连接输出节点使用浅层全连接神经网络。在手稿中呈现此类模型时,应提供适用于特定案例的其他详细信息,如表7所示。

6. DISCUSSION OF OPEN PROBLEMS 未决问题的讨论
尽管近年来多模态数据分类取得了很大进展,但仍有几个重要领域尚未得到充分解决。在本节中,我们将讨论与不断增长的数据集大小、困难的分类任务以及缺乏用于多模型分类的通用工具相关的开放性问题。
6.1 Big Data
大数据的出现带来了新的机遇和挑战。虽然有许多有效的大型数据集分类解决方案,但很少有专门针对多模态数据的解决方案,因为到目前为止,单模态一直是重点。多模态学习研究的主要局限之一是缺乏大型、公开可用的数据集。在审查的论文中进行的绝大多数实验使用的是只有几万到几千个例子的小数据集。通常包含医学影像的私人数据集也很小,因为收集医疗保健数据可能既耗时又昂贵,而且通常对其使用有道德和法律限制。
深度学习网络是目前最流行的多模态分类方法,这种技术最适合大型训练数据集。尽管 Illendula 和 Sheth [ 46 ] 使用了一个包含大约 500,000 个示例的数据集,但大多数其他作品使用的示例要少得多。当出现多类数据集时,有限数据的挑战进一步复杂化,因为每个类的示例总数将进一步减少。创建涵盖不同模态组合的大型基准数据集将对未来的多模态研究大有裨益。
虽然缺乏数据可能会对这些模型产生负面影响,但其对多模态分类的影响尚未得到充分研究。使用预训练模型的迁移学习可能有助于有限的训练数据,并且这种方法已在许多已审查的论文中使用。数据增强是插入新训练示例(例如图像移位或旋转)的常用方法。GAN 还被用于添加合成示例以增加多模态数据集的大小[ 56、65 ]。
大型数据集通常没有经过全面整理,可能存在缺失值或错误值。由于这些问题对于每种模态都可能独立存在,因此很可能更高比例的训练示例需要数据清理。除了传统的数据插补之外,还表明 GAN 可用于添加其中一种模式中缺失的数据 [ 26 ]。然而,即使 GAN 生成或清理的示例看起来是真实的,重要的是要确保模态间关系也代表原始数据集。未来的工作需要提供发现这些关系的方法以及如何安全地修改训练数据。
6.2 Imbalanced Data
许多机器学习算法的设计都假设训练数据集中的类分布是平衡的。然而,情况通常并非如此,类不平衡可能会引入偏差,从而对分类器性能产生负面影响 [ 36 ]。在许多现实世界的数据集中,可能有一个多数类明显大于其他少数类。同样的问题在多类数据集中会被放大,因为可能存在许多多数-少数类关系。
类不平衡数据可以通过修改数据本身、使用为解决此问题而设计的固有算法或两者的组合来解决 [ 53 ]。数据级方法最受单峰数据集的欢迎,并且是本文献综述中包含的多峰模型中发现的唯一方法。随机过采样是最常见的数据级方法之一,其中简单地复制随机示例,直到达到所需的类平衡水平。已使用随机欠采样,但可能存在删除有用示例或生成总体上太小的最终训练数据集的风险。另一种流行的方法是合成少数过采样技术 (SMOTE) [ 16],它从同一类的附近示例的组合中生成新示例。这种方法启发了许多其他过采样算法的开发,并已证明在许多情况下优于随机采样方法。
虽然在多模态不平衡学习方面所做的工作有限,但在一些评论的论文中已经解决了这个问题。例如,两个作品 [ 51 , 103 ] 使用随机欠采样,而另一个 [ 20 ] 使用随机过采样。Li等人也使用了更先进的SMOTE方法。[ 60 ] 以及 Uddin 和 Canavan [ 102 ]。由于 SMOTE 基于k -NN 算法,因此对各个特征进行归一化或按重要性进行加权非常重要。如果不执行此步骤,合成示例的生成可能会受到噪声或影响较小的特征的过度影响,从而导致示例质量较低。
GAN 已成为一种流行的数据增强方法 [ 85 ],并且已经用于多模态数据集。在一项工作中 [ 72 ],GAN 用于添加与图像数据配对的缺失文本模态数据。此外,李等人。[ 56 ] 生成了全新的合成示例,而不是仅仅输入缺失的模态数据。未来的工作需要更好地理解如何将 SMOTE 和 GAN 等方法与多模态数据集结合使用。
6.3 Instance-level Difficulty 实例级难度
分类器性能不佳不能总是归咎于类别不平衡,尤其是在类别分离良好的情况下。有些例子很难从中学习,因为它们存在于被其他类的例子污染的区域,或者靠近决策边界 [ 81 ]。从这些例子中学习的难度随着班级的增加或班级不平衡程度的增加而增加,因为这两者都会导致更多的区域污染。这些挑战在传统的单峰学习中得到了很好的研究,并且已经提出了许多解决方案来解决这个问题,尤其是在出现类别不平衡的情况下。
随机过采样和 SMOTE 等流行的过采样方法已被证明在解决类不平衡方面做得很好,但没有考虑哪些示例对分类更重要。Save Level SMOTE [ 12 ] 和 Borderline SMOTE [ 34 ] 等算法在过采样期间支持特定类型的示例,以更加强调特征空间的某些部分,例如安全类区域和决策边界。然而,还没有设计出包含这些学习概念和多模态数据集的方法。
这些单峰解决方案可能不会直接转化为多峰问题,因为个体模式可能表现出不同程度的学习困难。将每个模态嵌入到一个共享的潜在空间中可能有助于解决这个问题,但需要更多的实验来确定最佳解决方案。
6.4 Parallel and Distributed Computing
当前多模式研究中使用的相对较小的数据集不需要分布式计算解决方案。但是,与单个 CPU 或 GPU 相比,更大数据集上的分类模型需要更多的资源。Apache Hadoop、Apache Spark 和 GPU 集群等分布式系统是潜在的解决方案,但目前没有直接的多模式学习支持。尽管这种遗漏可能是由于缺乏历史用例造成的,但未来几年将需要与大型数据集兼容的多模态框架。
分布式计算为多模态学习提供了新的挑战,因为模型性能可能会受到计算节点之间数据共享方式的影响。如果不仔细考虑类实例或子概念的分布,则每个节点生成的部分结果可能无法正确反映训练数据的全局属性 [ 88 ]。虽然这已被证明是单模态学习的一个潜在问题,但尚未确定这将如何影响多模态模型。
多模式分布式解决方案的两种可能模式包括将每种模式一起处理(早期融合)或独立处理然后在最后减少(后期融合)。在早期融合的情况下,特定节点的数据可能与一种模式成比例,但与另一种模式不成比例。这可能会引入类似于传统单峰模型中发现的类不平衡或实例级困难的学习挑战。如果模态特定模型之间的数据分布不同,后期融合架构可能会出现其他问题。需要进一步的工作来更好地理解分布式多模式学习的潜在挑战以及解决这些挑战的最佳架构。
6.5 Evaluation Metrics
必须评估分类模型以确定其性能,并且使用的具体指标取决于所需的结果。真阳性率、精确率、召回率和 F1分数经常被使用,特别是对于二进制类数据集。F的宏观和微观平均1也用于多类别数据集,但这些指标在呈现不平衡数据时可能会提供过于乐观的结果,因为它可能隐藏了少数类别的不良表现。据 Branco 等人报道。[ 11 ],还有许多其他指标更适合处理不平衡数据,例如类的平均准确度(AvAcc) 、每个类召回的几何宏观平均数(MAvG)和类平衡准确度(CBA ) )。
这些现有指标是为单峰问题设计的,我们不知道有任何指标是专门为评估多峰分类器而设计的。虽然这些指标正在解决与预测类别相关的性能,但了解每个模型对每个单独模态的表现可能很有价值。更进一步,每个类的性能可能会受到每种模式的不同影响。为多模态分类设计的新指标可以帮助识别模态特定模型表现不佳的区域,并更好地理解类别与每种模态之间的关系。
6.6 Universal Models and Benchmarks 通用模型和基准
如之前的研究所示,传统的机器学习算法和深度学习架构可以成功地用于多模态分类。然而,这些模型的一般可用性是有限的,因为大多数模型都是针对特定领域的输入模式量身定制的,可能无法直接用于不同的数据组合。虽然 EmbraceNet [ 17] 部分解决了这个问题,它只是为后期融合风格的网络设计的,并且可能会丢失模态之间的一些共享上下文,这取决于融合特征向量的构建方式。理想情况下,未来的多模式框架将可配置为使用定义良好的架构规则支持任意输入类型。这将允许直接手动或自动构建复杂的模型或网络。随着迁移学习的成功和预训练模型数量的不断增加,为这些网络提供即插即用支持将简化构建强大的多模态模型的过程。
单峰学习受益于大型、公开可用的数据集,例如来自修改后的国家标准与技术研究所 (MNIST)和 ImageNet 的数据集。需要这些数据集来训练可用于迁移学习的大型模型,并为评估不同方法提供基准。创建此类数据集将是推进多模态学习的重要一步。
7. CONCLUSIONS
尽管单峰学习在机器学习领域占据主导地位,但人们对多峰问题的兴趣越来越大。组合来自多个来源的数据的新方法、社交媒体和客户评论的大量收集以及医疗保健相关信息的聚合都为多模态学习提供了更多有价值的用例。我们还看到了可以将单峰数据集视为多峰问题的案例,从而利用这些新颖的学习方法。审查论文的普遍共识是,基于多模态的架构有可能胜过传统的单模态模型。然而,基于多模态的学习和分类架构的主要方面缺乏一致的术语,这使得比较或评估不同的方法变得困难。
正如第1节中所讨论的,我们有动力解决与多模态分类问题相关的四个突出问题。首先,第3节中介绍了特定于多模态分类的分类法,以便更轻松地描述此类模型。在第4节中,分类法应用于 64 个先前发布的多模式模型,以突出这些架构的最新趋势。第5节举例说明了如何将此分类法应用于新模型,并提供了一个清单,可用于指导手稿中的模型描述。最后,第6节讨论了未来的挑战。
本文未解决的许多其他重要挑战需要进一步研究。回归模型已成功用于多模态数据集 [54、108、109 ],但与分类相比,它受到的关注要少得多。未来关于该主题的调查可以帮助确定一般挑战和我们提出的分类分类法是否可以很好地转化为回归模型。生成模型,例如 GAN 和 AE,在多模态调查论文中得到了很好的体现,但仅在少数经过审查的分类模型中使用。以类似的方式,典型相关分析(CCA)已经在多模态学习的背景下进行了普遍讨论,但很少与分类模型一起使用。深入讨论如何或何时使用此类方法进行多模态分类将对研究界有益。
总之,我们提出了一种新的多模态分类法,用于描述整体模型架构和执行数据融合的风格。与以前的分类法不同,我们只关注分类问题,并根据先前作品的常见模式来指导我们的定义。我们相信这种分类法在描述往往比单峰模型更复杂的多峰模型时会有所帮助。

















 1735
1735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









