







[pytorch] detr源码浅析
为之后SAM的代码分析做铺垫
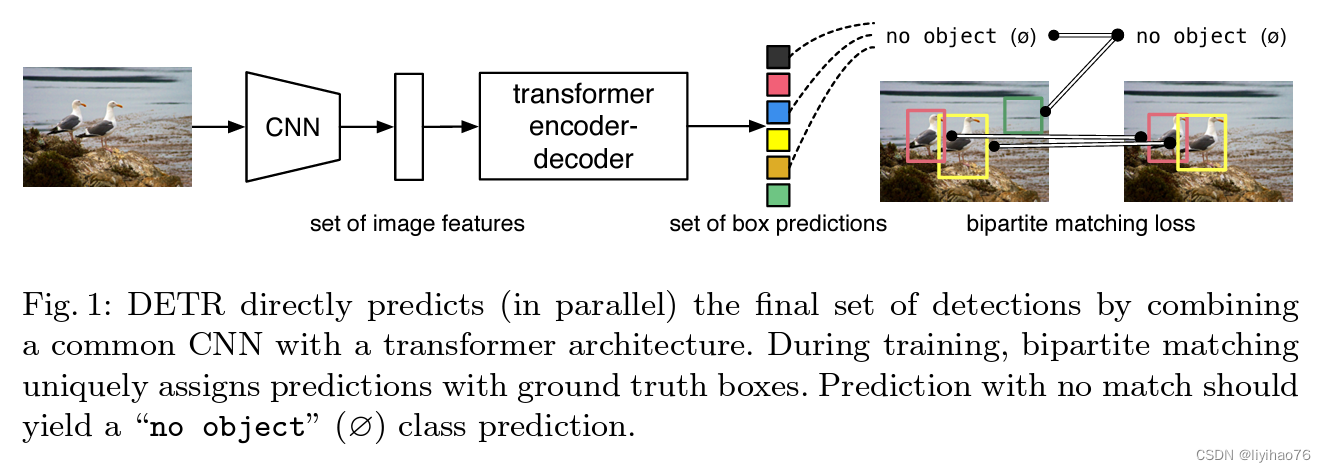
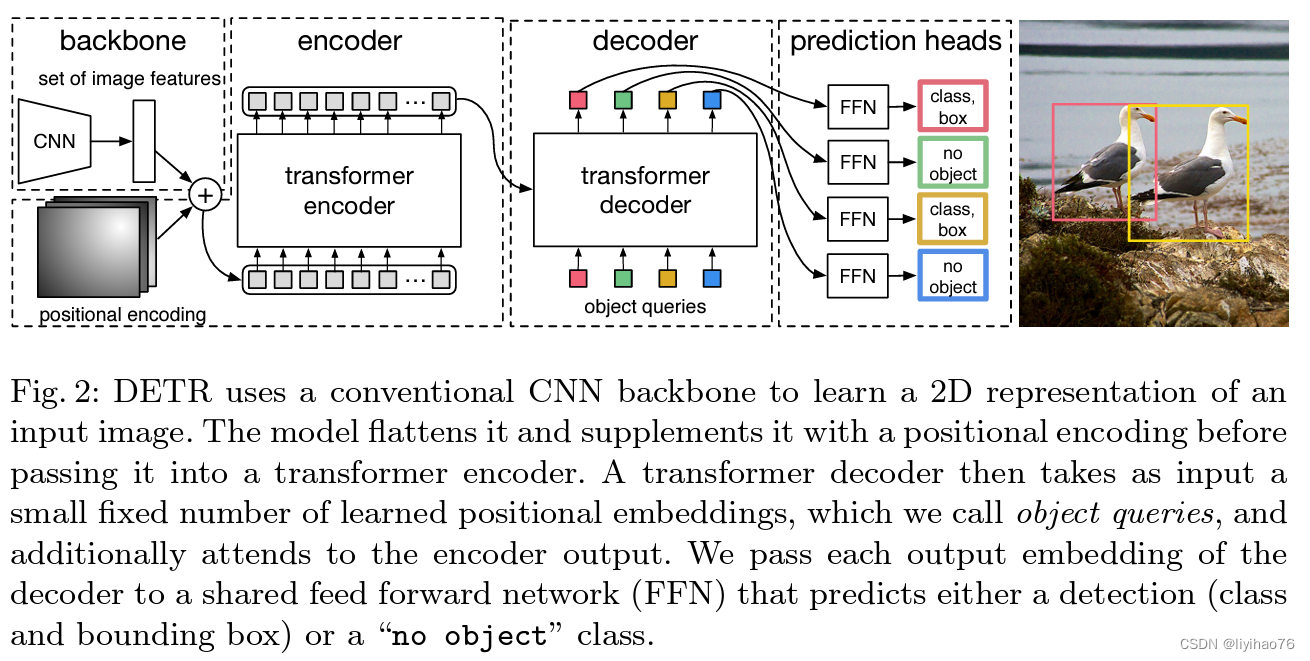
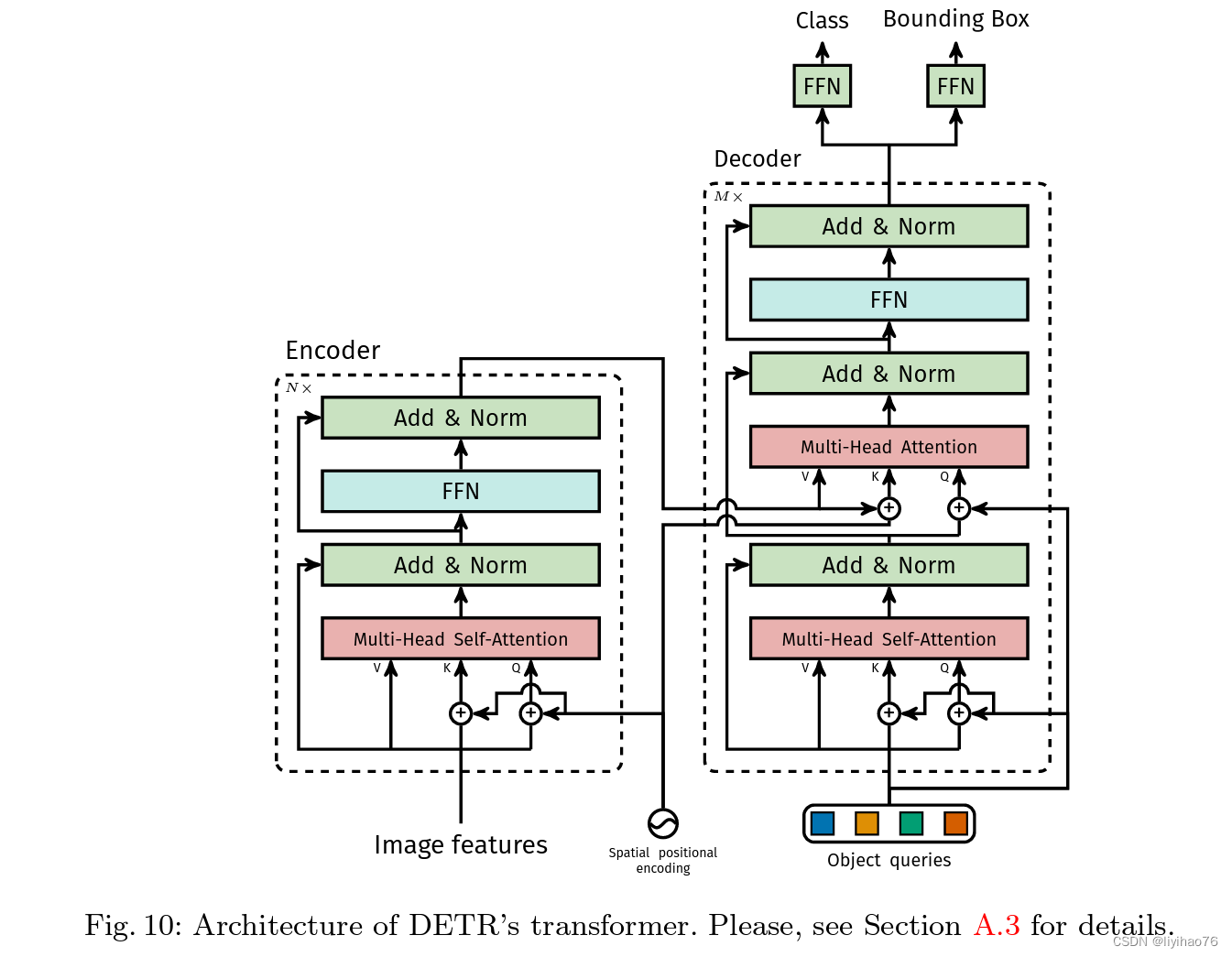
1. backbone部分
- detr.py中的DETR class
class DETR(nn.Module):
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
...
def forward(self, samples: NestedTensor):
features, pos = self.backbone(samples)
# 第一步,从图像提取特征
# 返回值:特征图,pos位置编码(当前得到的特征图编码.不是对原始图像)
# 跳到backbone - backbone.py里的Joiner函数
- backbone.py 中的 Joiner class
class Joiner(nn.Sequential):
def __init__(self, backbone, position_embedding):
super().__init__(backbone, position_embedding)
def forward(self, tensor_list: NestedTensor):
# print(tensor_list.tensor.shape)
xs = self[0](tensor_list)
# 输入图像经过resnet
# 得到特征图
out: List[NestedTensor] = []
pos = []
for name, x in xs.items():
out.append(x)
pos.append(self[1](x).to(x.tensors.dtype))
# 跳到position encoding.py
return out, pos
- position encoding.py
第一种:Attention Is All You Need中的正余弦编码方式,不用学习,默认方法

class PositionEmbeddingSine(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.
"""
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperature = temperature # 经验值
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
# 输入特征图大小 batch, c, h, w resnet50 c = 2048
mask = tensor_list.mask
# mask 表示实际的特征true 还是padding出来的false
# 大小 batch,h,w
assert mask is not None
not_mask = ~mask
y_embed = not_mask.cumsum(1, dtype=torch.float32) # 行方向累加 最后一位为累加的得到的最大值
x_embed = not_mask.cumsum(2, dtype=torch.float32) # 列方向累加 最后一位为累加的得到的最大值
if self.normalize:
eps = 1e-6
# 归一化
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
# 算奇数维度或者偶数维度 公式不一样
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
# 前一半是pos_x 后一半是pos_y
return pos
第二种:可学习的位置编码
class PositionEmbeddingLearned(nn.Module):
"""
Absolute pos embedding, learned.
"""
def __init__(self, num_pos_feats=256):
super().__init__()
# 行和列进行编码
self.row_embed = nn.Embedding(50, num_pos_feats)
self.col_embed = nn.Embedding(50, num_pos_feats)
# 50经验值
self.reset_parameters()
def reset_parameters(self):
nn.init.uniform_(self.row_embed.weight)
nn.init.uniform_(self.col_embed.weight)
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
h, w = x.shape[-2:]
i = torch.arange(w, device=x.device)
j = torch.arange(h, device=x.device)
x_emb = self.col_embed(i)
y_emb = self.row_embed(j)
pos = torch.cat([
x_emb.unsqueeze(0).repeat(h, 1, 1),
y_emb.unsqueeze(1).repeat(1, w, 1),
], dim=-1).permute(2, 0, 1).unsqueeze(0).repeat(x.shape[0], 1, 1, 1)
return pos
2. encoder部分
- detr.py中的DETR class
class DETR(nn.Module):
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
...
def forward(self, samples: NestedTensor):
features, pos = self.backbone(samples)
src, mask = features[-1].decompose()
# features和pos保存的都是cnn中每个block的结果,用的时候取最后一个block的结果
# features大小 batch, c, h, w resnet50 c = 2048
# mask 大小 batch, h, w 是否padding
assert mask is not None
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
# self.input_proj降维 cnn得到的特征图维度2048太大了把它降低到256
# 跳到 transformer.py中的Transformer class
- transformer.py中的Transformer class
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1) # NxCxHxW to HWxNxC
# N是batchsize大小 把特征图长×宽得到token个数
# 输出大小 [token个数,batch size,token 长度]
pos_embed = pos_embed.flatten(2).permute(2, 0, 1) # NxCxHxW to HWxNxC
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
# query_embed 在decoder中用到,大小为[100,batch size,token 长度]
mask = mask.flatten(1) # mask大小 [token个数,batch size]
tgt = torch.zeros_like(query_embed)
# tgt在decoder中用到
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
# 跳到 transformer.py中的TransformerEncoderLayer class
# encoder的输出大小 [token个数,batch size,token长度]
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
- transformer.py中的TransformerEncoderLayer class
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos) # 只有K和Q 加入了位置编码
# q k 的大小都为 [token个数,batch size,token长度]
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
# pytorch自带函数
# src_mask 是nlp中防止透题用的,这里不用
# src_key_padding_mask padding为true的不计算
# 返回值 [新的特征图,权重项] 第二项不需要
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
- transformer.py中的TransformerEncoder class
将TransformerEncoderLayer 重复多次
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
for layer in self.layers:
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
if self.norm is not None:
output = self.norm(output)
return output
3. decoder部分
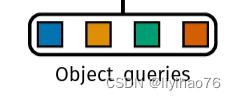
detr要学习的核心 100个queries向量tgt 大小[100,batch size,token长度]
第一次初始值都为0
最终输出的100个queries最后预测框
无论输入为什么,都输出100个框
- transformer.py中的Transformer class
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1) # NxCxHxW to HWxNxC
# N是batchsize大小 把特征图长×宽得到token个数
# 输出大小 [token个数,batch size,token 长度]
pos_embed = pos_embed.flatten(2).permute(2, 0, 1) # NxCxHxW to HWxNxC
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
# query_embed 在decoder中用到,大小为[100,batch size,token 长度]
mask = mask.flatten(1) # mask大小 [token个数,batch size]
tgt = torch.zeros_like(query_embed) # 一开始初始化为0
# tgt在decoder中用到
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
# 跳到 transformer.py中的TransformerDecoderLayer class
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
- transformer.py中的TransformerDecoderLayer class
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos)
# 大小[100,batch size,token长度]
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
# 先自注意力机制
# tgt_mask 和 tgt_key_padding_mask 都为None
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
# q 是 100个queries
# 图像提供k,v 大小[图像token个数,batch size,token 长度]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
- transformer.py中的TransformerDecoder class
将TransformerDecoderLayer 重复多次
tgt 在经过第一层之后就不为0了
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
output = tgt
intermediate = []
for layer in self.layers:
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate)
return output.unsqueeze(0)
4. 输出预测
- detr.py中的DETR class
把decoder产生的100个token进行输出
两个任务:检测(回归4个值)和分类
class DETR(nn.Module):
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
...
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
def forward(self, samples: NestedTensor):
features, pos = self.backbone(samples)
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
# decoder输出大小 [batch size,100,token长度]
outputs_class = self.class_embed(hs) # 分类任务
outputs_coord = self.bbox_embed(hs).sigmoid() # 检测/回归任务,输出四个值,sigmoid让输出为正数
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}















 332
332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









