







01.查询的过程
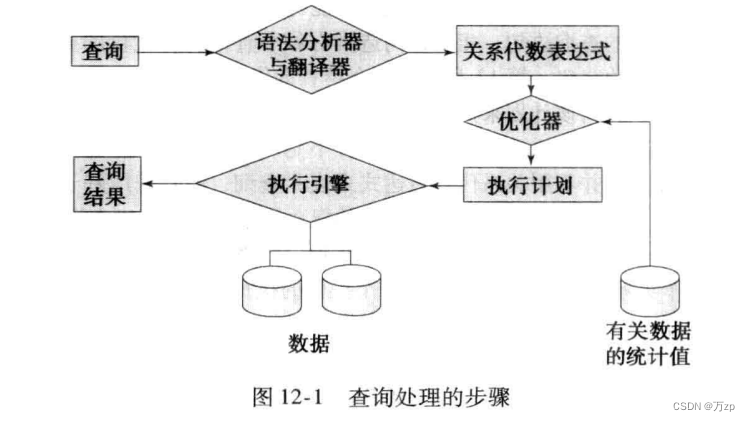

将SQL语句翻译成为关系代数:关系代数才是内部执行的基础


例子:

结果:


相关的术语:
计算原语:加了如何执行注释的关系代数运算
查询执行计划:执行一个查询的原语操作序列
查询执行引擎:接受一个查询执行计划,将结果返回给查询本身

有例外:

02.度量
度量的重要性:

度量的方面:

主要是磁盘的读取

具体过程:举个例子


计算的过程:读写磁盘分开计算

一般用最坏的情况考虑缓冲区的大小,缓冲区和磁盘读取的次数有关

缓冲区
缓冲区是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
为什么要引入缓冲区
比如我们从磁盘里取信息,我们先把读出的数据放在缓冲区,计算机再直接从缓冲区中取数据,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作大大快于对磁盘的操作,故应用缓冲区可大大提高计算机的运行速度。
又比如,我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情。现在您基本明白了吧,缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。
估算的原则:最开始的时候,数据必须从磁盘中读取出来



03.选择运算


直接依次扫描整个块


这里的主索引特指主码
B+树查找:hi是结点高度,代表要访问几次磁盘,1是从叶结点获取的指针访问磁盘记录的数据

B+树查找:hi是结点高度,代表要访问几次磁盘,b是从叶结点获取的指针访问磁盘记录的存储的块数。

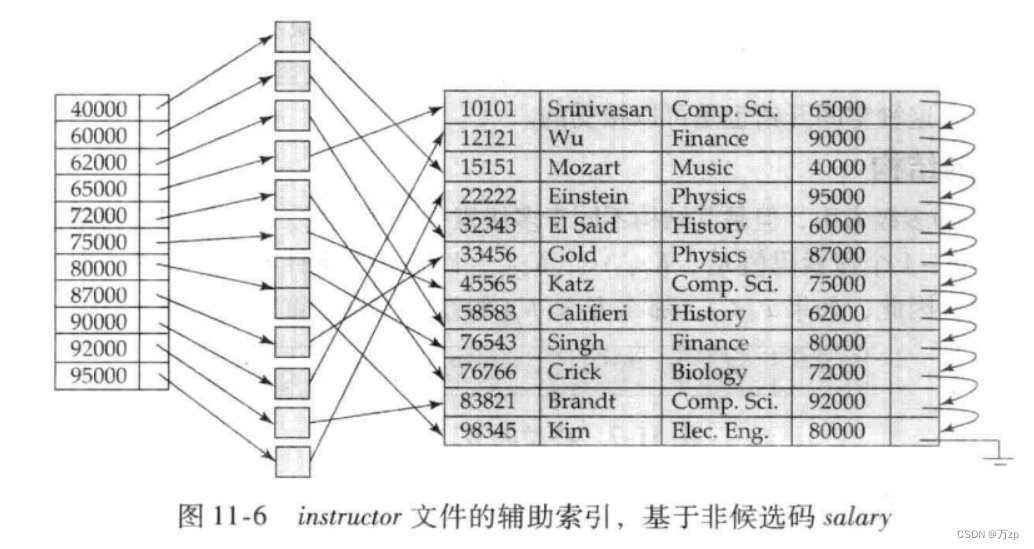
辅助索引是稠密索引:
记录唯一:和主索引一样查找 B+树查找:hi是结点高度,代表要访问几次磁盘,1是从叶结点获取的指针访问磁盘记录的数据
记录不唯一:B+树查找:hi是结点高度,代表要访问几次磁盘,n是从叶结点获取的指针访问磁盘记录的记录总数。

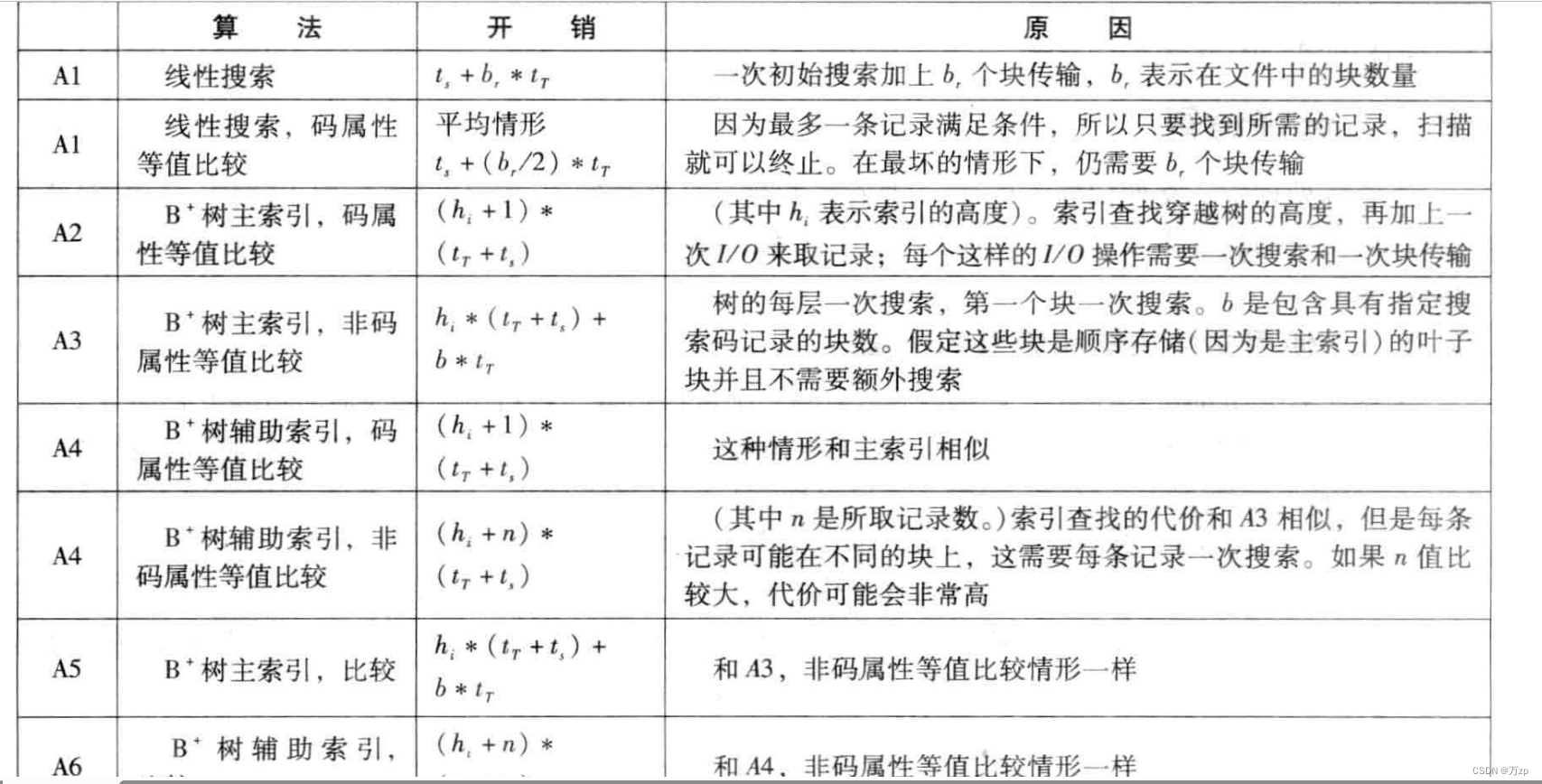


辅助索引:




位图

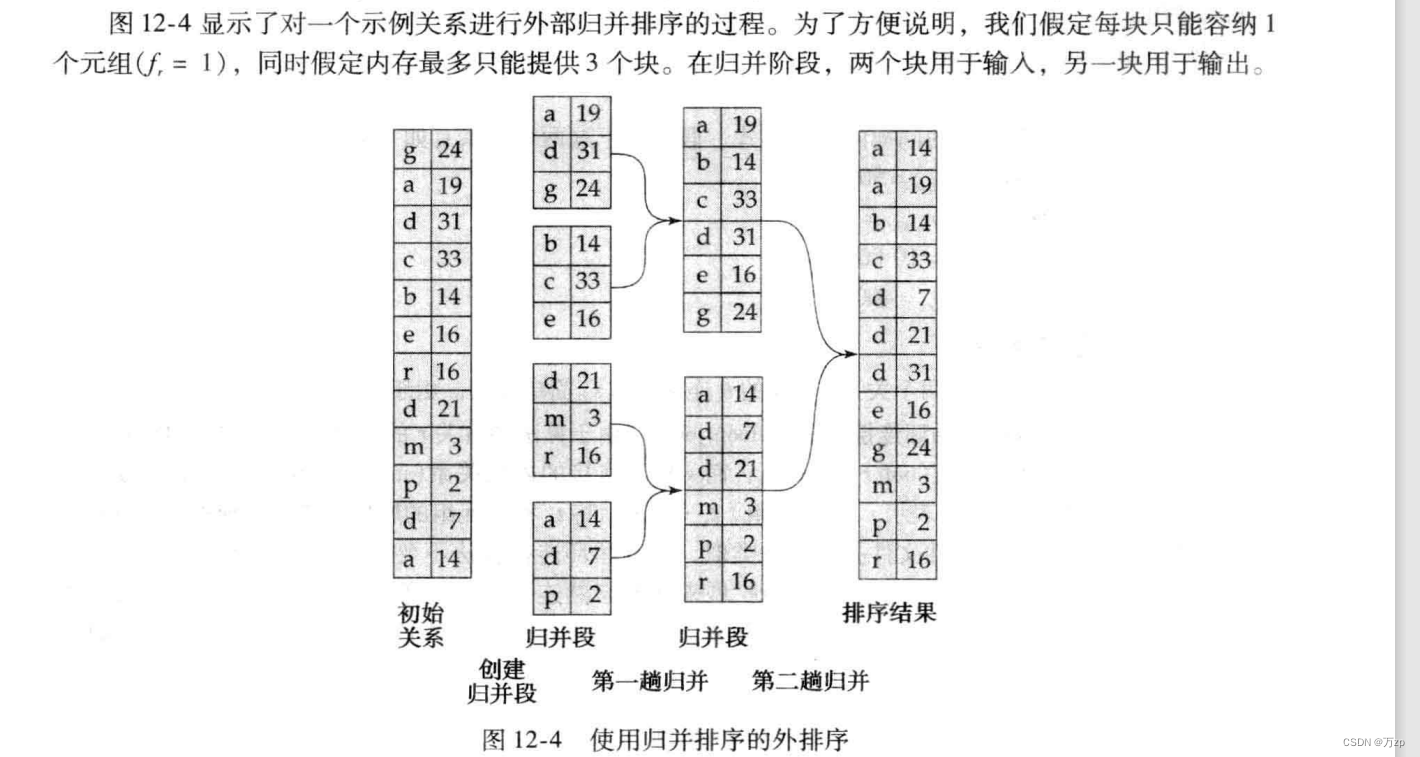
03.排序,这里是着重对数据的排序





这里是n个缓冲块一起进行排序,不是只有两个,所以是n路归并


因为要留下一个块来作为输出,所以参加排序的块是M-1。所以是1/(M-1)
分析:

01.创建归并段 2br
02.归并段归并 br{[2logM-1(br/M) ] -1} //最后一次没有返回磁盘
03. 2br+br{[2logM-1(br/M) ] -1}


04.连接运算,from语句,适用于等值连接和自然连接
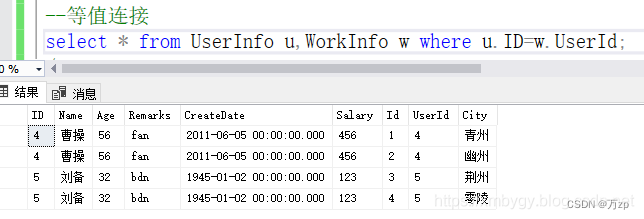
什么是等值连接?
等值连接是关系运算-连接运算的一种常用的连接方式。是条件连接(或称θ连接)从左表中取出每一条记录,去右表中与所有的记录进行匹配:匹配必须是某个条件在左表中与右表中相同最终才会保留结果,否则不保留。
举例分析:
UserInfo表:
WorkInfo表: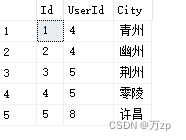

一.

计算这个链接访问磁盘的次数:

磁盘块传输:
nr和ns 是r,s这两个关系的元组总数。
br和bs 是r,s这两个关系的存储磁盘块总数。
nr*bs 对于每一条关系r中的记录,都需要把关系s中的全部记录都要扫描一遍
nr*bs +br 还需要把关系r的全部磁盘块读入缓冲区(最坏,一个关系一次只读入一个磁盘块)
bs+br 这个时候缓冲区足够大,两个关系都可以读入到缓冲区
磁盘搜索:
内层关系s,是顺序读取的,每次读取只需要找到最开始的那一个元组,所以每次的磁盘搜索就一次,一共nr次。
外层关系r,在要在每次读取完内层关系s之后,再次的重定向找到r在磁盘上的记录,所以是br次
nr+br (最坏)

例子:

二.

区别:

br和bs 块
计算

改进

三


tT和ts 是传输一个块的时间和 磁盘块访问时间
br(tT+ts) r关系的总和
nr*c s关系传输数据和磁盘块访问时间总和


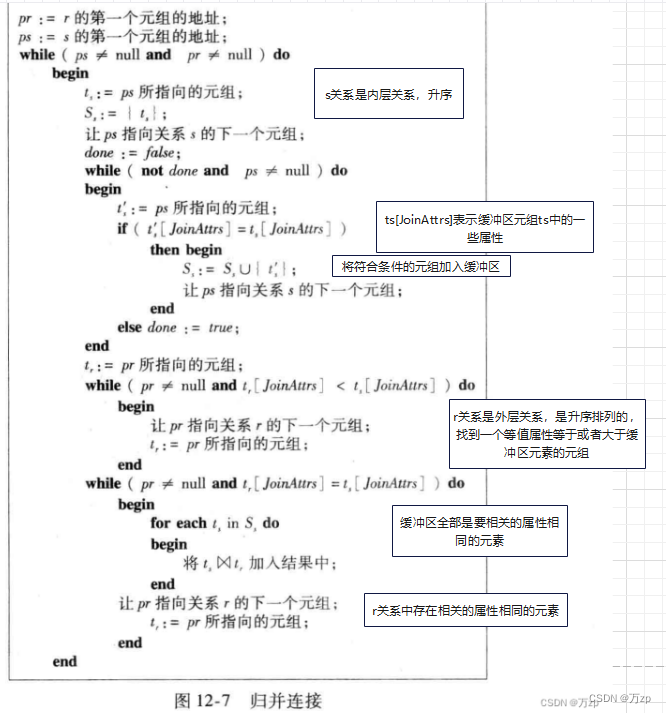
归并连接


注释:
01
“:=”表示的是赋值操作。
1)@num=@num+1
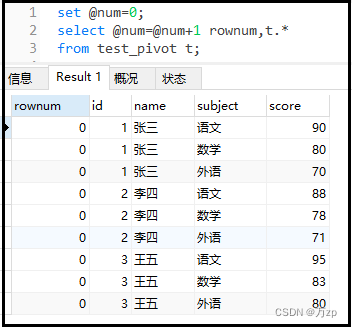
上图说明:
首先,第1行我们使用set @num=0;声明了一个用户变量,也就是你们在其它编程语言中常说的声明并初始化了一个变量,只不过不同编程语言的语法不同而已,你习惯了就好。记住,用户变量在当前窗口中的任何一个地方都可以使用。
接着,我们写了一个sql语句,在select后面我们写了@num=@num+1这样一句话,这句话表示的是等于的意思。当select每取出一行数据的时候,这里就会判断一次@num是否等于@num+1,很明显不等于呀!因此,每取出一条数据,显示的都是0(在mysql中false显示的是0)。
2)@num:=@num+1
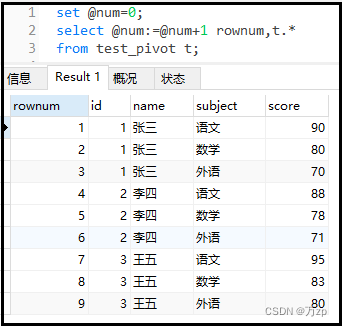
上图说明:
首先,第1行我们仍然是使用set @num=0;声明了一个用户变量。
接着,我们写了一个sql语句,在select后面我们写了@num:=@num+1这样一句话,这句话表示的是赋值的意思。当select取出第一行数据的时候,就会将@num+1赋值给左边的@num,由于@num原始值等于0,因此“:=”左边的@num变为了1。当select取出第二行数据的时候,又会将@num+1赋值给左边的@num,由于此时@num等于1,经过赋值以后,“:=”左边的@num就变为了2,这样依次进行下去。
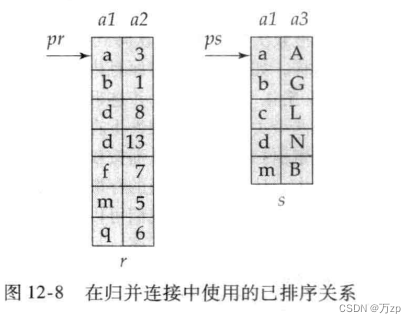
02.{ts}
这个是代表缓冲区上的元素是ts

总结:
归并连接的内容与前面讨论过的归并排序非常类似。不同的是不用从两张关系表中拿出所有的数据,我们仅需要拿出相等的数据即可。算法基本思路是:
- 先比较两张关系表的第一个元素。
- 如果第一个元素相等,将这两条数据放到结果集中。然后比较下一个元素。
- 如果不相等,取小的元素所在表的下一个元素,下一个元素可能就匹配了(译者注:在做merge join前先对两张表做由小到大的排序)。
- 重复前面的几步操作,直到其中一张表的数据比较完了为止。
这个算法能正常运作的前提是,两张关系表的数据都已经排好序,在比价的过程中不需要回溯前面的元素。
散列连接:

t1是外层关系,c1是外层关系的元组,t2是内层关系,d1是内层关系的元组。
首先我们讲下散列连接的原理:
1) 对 t1 表(称为构建表)进行全扫描,对于每一个记录,对 c1 值进行使用内部散列函数,然后将该数据存放到相应的散列桶。
2) 开始读 t2 表(称为探查散列表),对于 t2 的每一个记录,对 d1 值使用同样的散列函数,得到相应的散列值,查看该桶中是否有行。
如果相应的桶中没有行,则会丢失 t2 中这一行记录。如果散列桶中如果有一些行呢,则会精通的检查散列连接判断是否存在合适的匹配。因为不同的值可以产生同样的散列值。找到精确匹配的值,组合成记录放入结果集中。
我们来评估下代价。
1) 首先我们先看构建散列的代价,对于 t1 的每一个记录,一般只需要访问一个散列桶。
2) 对于 t2 的每一个记录,一般只需要访问一个散列桶。

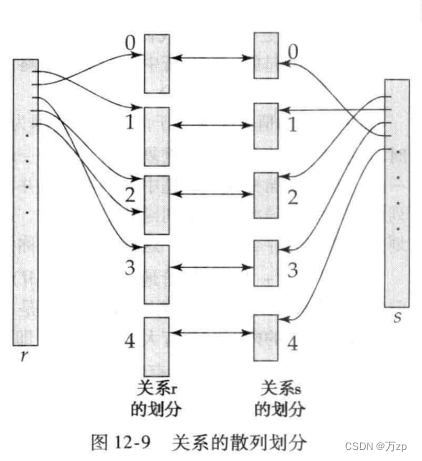


其他运算:

01.

02.
03.

04 外连接
左外连接、全外连接、右外连接
外连接的计算策略:
方法1:计算响应的自然连接/等值连接,然后将未连接的结果加入到结果集中作为最终的连接结果。
方法2:扩展连接算法
扩展嵌套循环连接、块嵌套循环连接==> 较简单的实现左外连接和右外连接,但是全外连接很难
扩展归并连接==> 可以计算全外连接,左外连接,和右外连接
计算全外连接:当两个关系的归并完成后,将两个关系中那些与另外一个关系的任何元组都不匹配的元组填充空值后写到结果中。
扩展散列连接算法 ==> 可计算全外连接、左外连接和右外连接

avg, min, max, sum, count
使用排序或散列,将元组进行分组;再在每个分组上进行聚集运算得到结果。


01.一种是计算表达式然后结果保存到临时表,供后续表达式计算使用,这种方式叫物化(Materialization)

过程


例子:
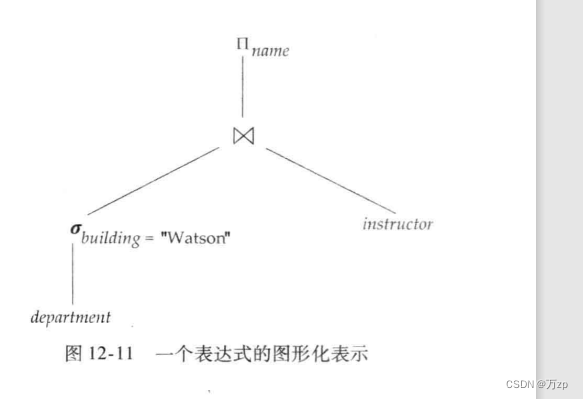


计算时间

02.另一种方法是流水线(pipelining)这种方式把表达式计算串起来,计算出结果后直接交给下个表达式用于运算。

区别


需求驱动的流水线有点像迭代器,从根往叶子执行,表达式不断向子表达式请求需要的数据。
生产者驱动的流水线刚好反过来,从叶子往根执行。子表达式不停的产生数据,直到用于保存中间数据的 buffer 满了,上层表达式从 buffer 取出数据执行,直到 buffer 空了,类似 producer-consumer 模型。



















 1748
1748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









