







01.查询优化的概念

02.例子:优化关系代数





转换关系代数:
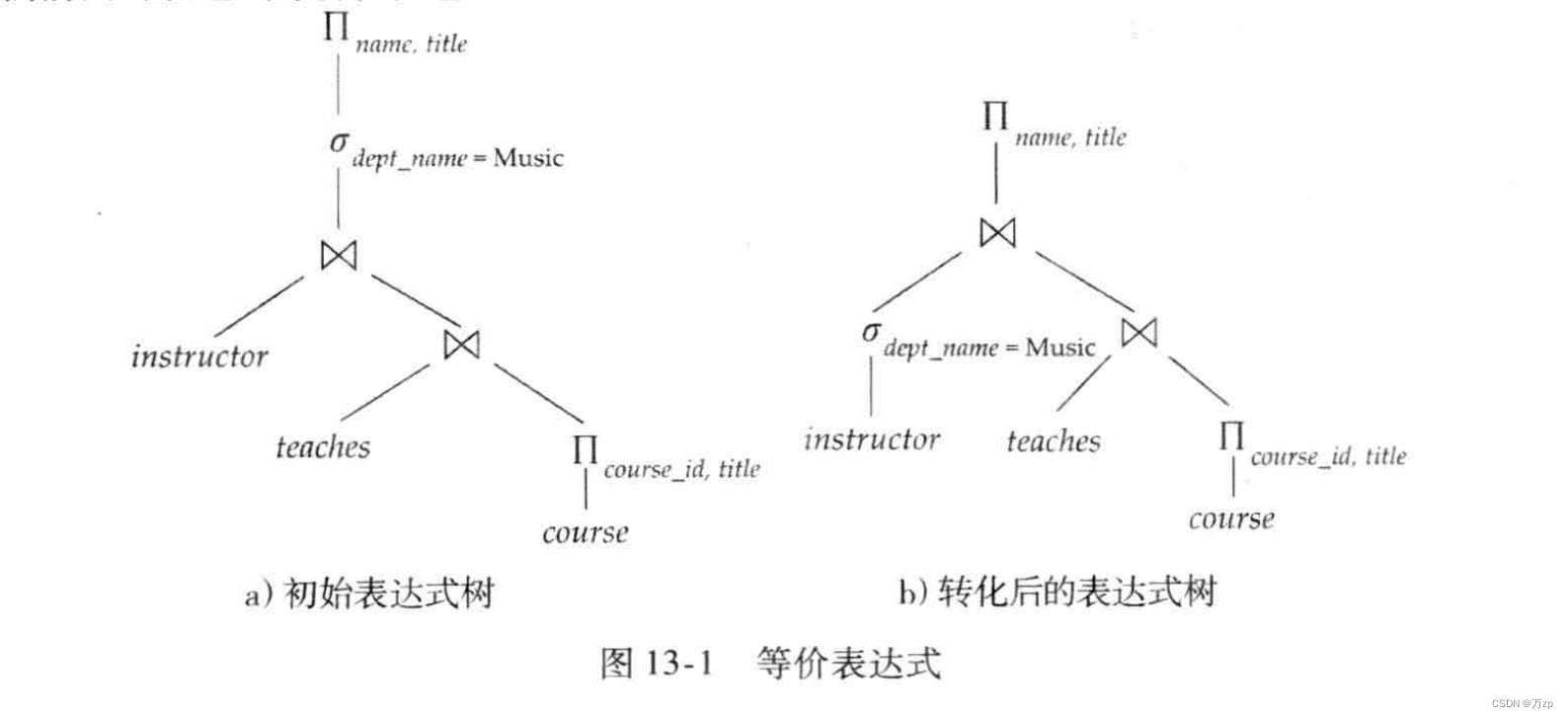
03.优化查询执行计划

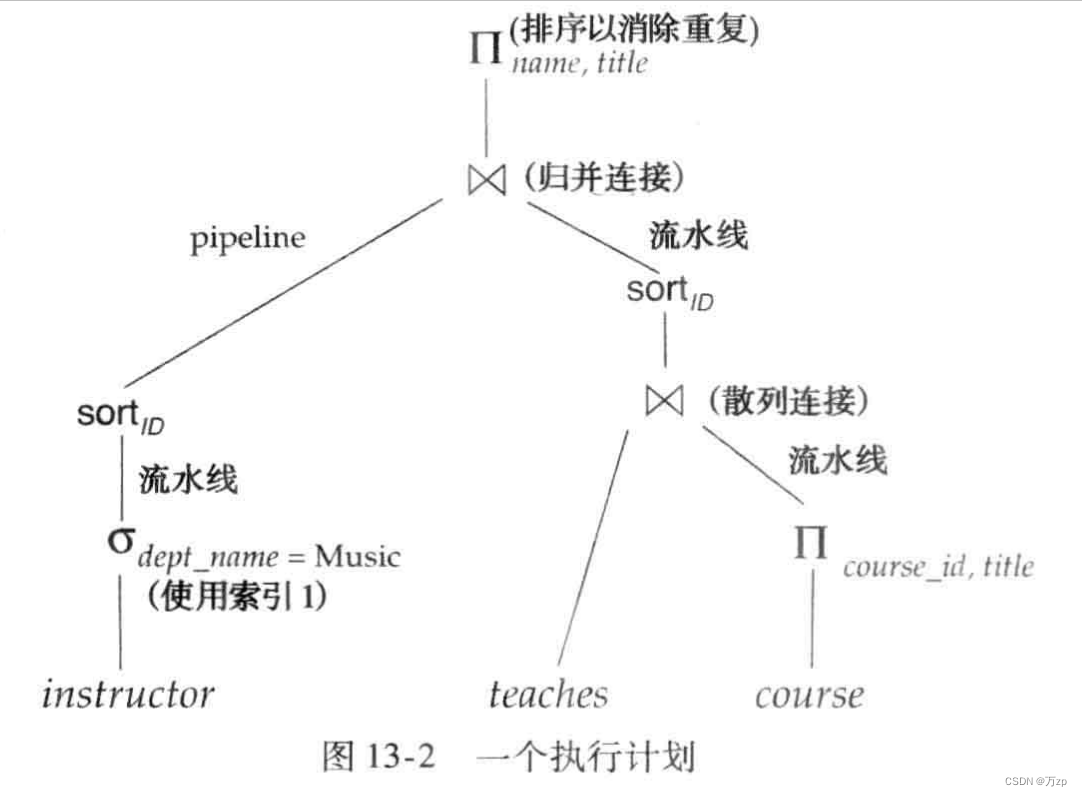




04.这些都是查询优化器,详细介绍:
一.

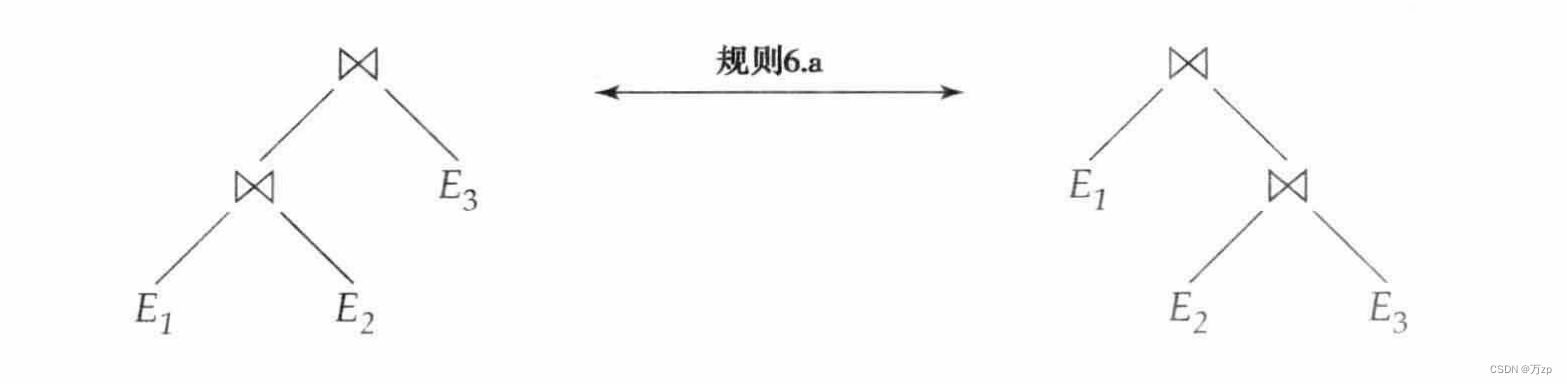
等价表达式

等价规则:


01.

02.


03.

04.

E1 X E2 是全部笛卡尔积
什么是自然连接?
自然连接(Naturaljoin)是一种特殊的等值连接,它要求两个关系中进行比较的分量必须是相同的属性组,并且在结果中把重复的属性列去掉。
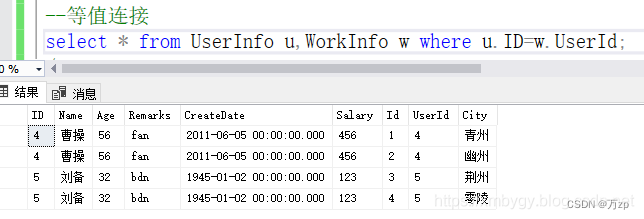
什么是等值连接?
等值连接是关系运算-连接运算的一种常用的连接方式。是条件连接(或称θ连接)从左表中取出每一条记录,去右表中与所有的记录进行匹配:匹配必须是某个条件在左表中与右表中相同最终才会保留结果,否则不保留。
举例分析:
UserInfo表:
WorkInfo表: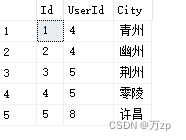


06.

07.



09.

10.

11.

12

例子1:



例子2:






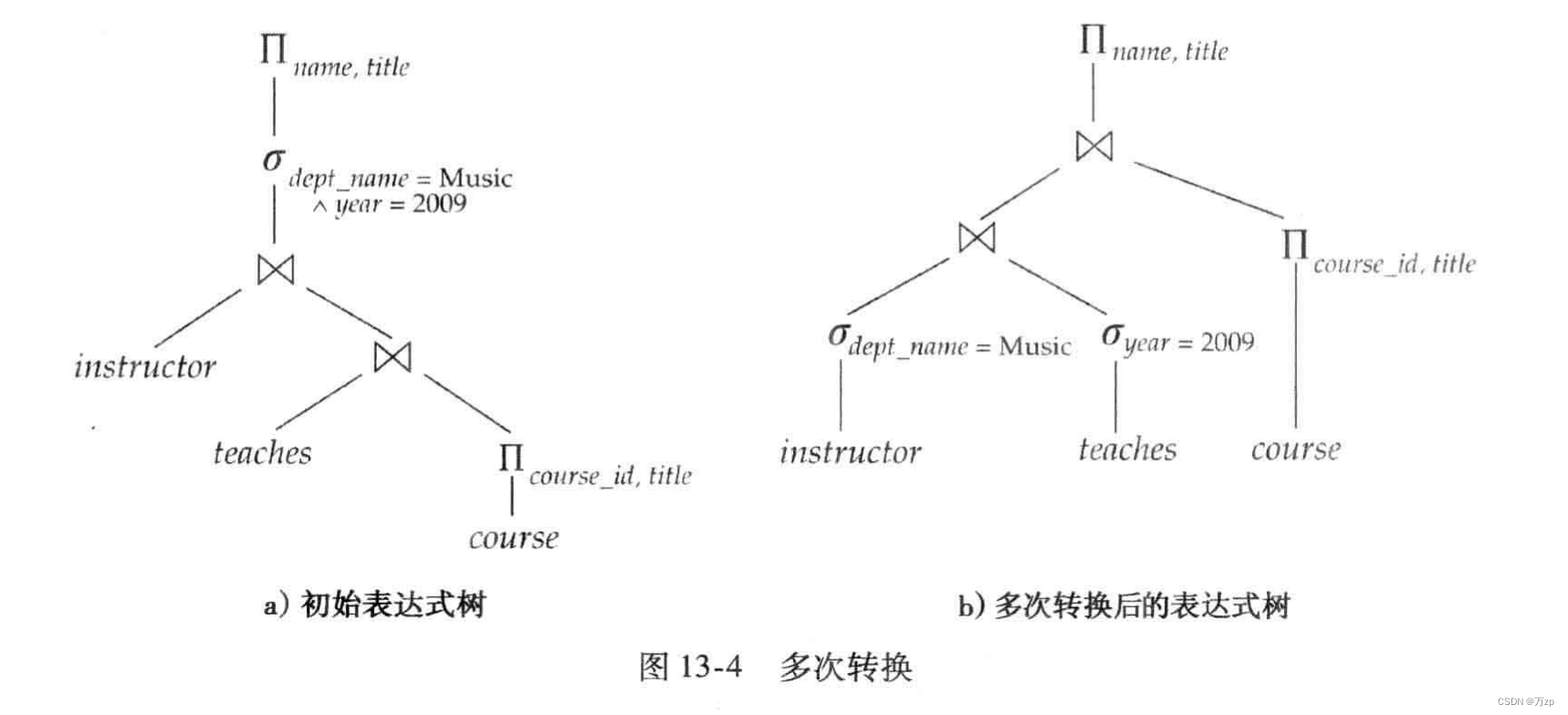








13.2.4 等价表达式的枚举
可以用枚举的方式产生所有的等价表达式,如下图所示。这种方式在时间上和空间上的代价都很大。可以采用两种关键思想,优化器可以极大地减少时间和空间上的开销:






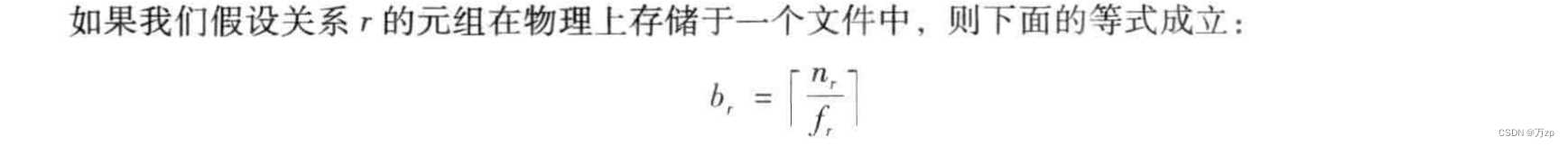



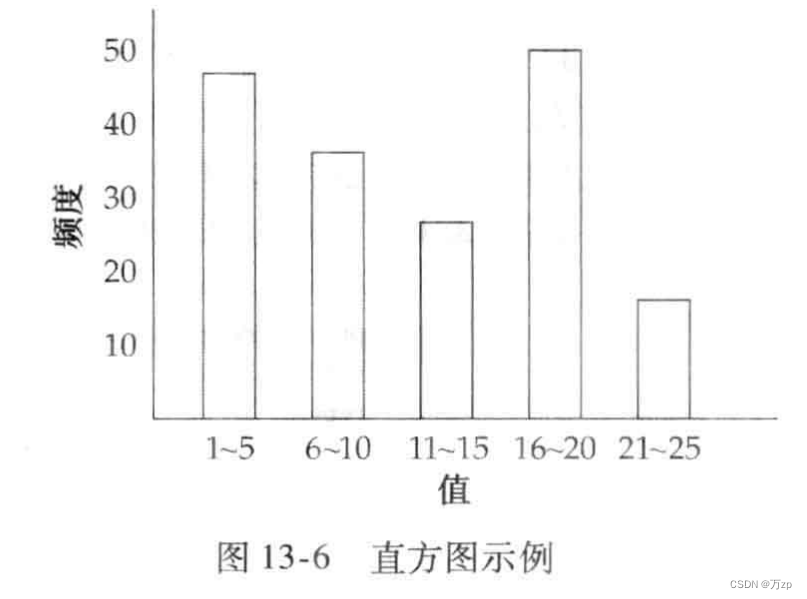



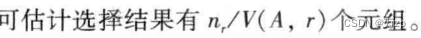






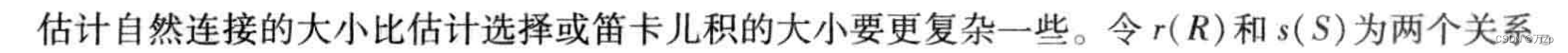

解释:


码是指主码,具有唯一。


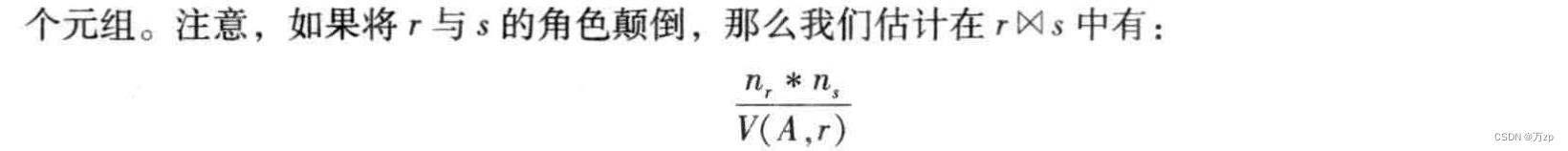

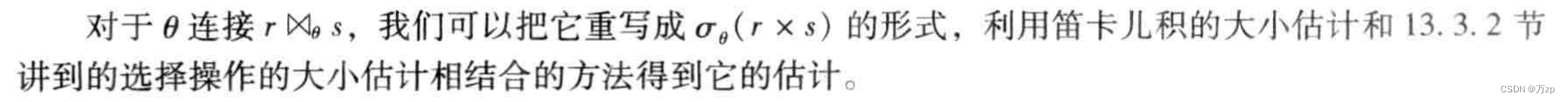





01.







02.




采用等价规则的基于代价的通用优化器(可以处理各种查询结构)
优点:采用等价规则可以使它易于扩展新的规则到优化器来处理不同的查询结构。例如:使用扩展的关系代数结构表达嵌套查询
产生所以有的可能的执行计划的过程:
01.添加一类新的称为物理等价(physical equivalence rule )的等价规则,允许将例如连接这样的逻辑操作转为散列连接或嵌套循环连接这样的屋里操作。
02.通过将这类规则加入到原来的等价规则(13.2.4节的算法)中,程序可以产生所有的可能的执行计划
03.利用基于代价的估计技术选择最优计划
如何使得上述算法更高效?

03.




注意:基于规则的启发式优化不一定总会带来高效的查询。
多数现实的查询优化器采取更多的启发式规则来减少优化的代价。例如:




04.
嵌套子查询的与优化
复杂的嵌套子查询的优化非常困难,许多优化器仅做少量的去除相关的工作。只要有可能,要尽量避免使用复杂嵌套子查询,因为不能保证优化器是否能将它们转换成一种能够有效运算的形式。
















































 3889
3889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









