






汇编器
- 汇编器是将汇编语言转化为机器码的程序。
- 或许你会以为汇编转化到机器码没什么大不了的,毕竟几乎是一对一的转换。但nasm存在的意义在于它可以很好的适应多种处理器平台,让编写汇编这件事都变得可移植了。
- nasm可以在Ubuntu下汇编,使用elf32或者elf64格式(具体取决于你的机器)
- 在Mac下使用Macho64格式,在Win下使用Win64格式。
在Mac下
nasm -f macho64 helloworld.asm
ld -e _main helloworld.o -macosx_version_min 10.13 -lSystem
在Ubuntu下
nasm -f elf64 helloworld.asm
ld -e _main helloworld.o
- helloworld.o是目标文件,它几乎就是可执行文件,它离我们完整的可执行程序只差了链接这一步。而ld正是GUN自带的链接工具,可以将目标文件链接起来。
C程序转化为一个可以在Unix内核机器上执行的文件,需要经历下面四个步骤:
- 预处理:处理C中的预处理命令,也就是#开头的那些,默认的生成文件格式为.i
- 编译:将C程序编译为汇编语言, 默认的生成文件格式为.s,这里的.s和我们的.asm没什么区别
- 汇编:将汇编语言转化为机器码,默认的生成文件格式为.o
- 链接:链接动态库和静态库
汇编语言入门三:是时候上内存了
- 把寄存器里的值存放到内存中
global main
main:
mov ebx, 1
mov ecx, 2
add ebx, ecx
mov [0x233], ebx
mov eax, [0x233]
ret
不出所料,报错,段错误 Segmentation fault (core dumped)
原因:我们的程序运行在一个受管控的环境下,是不能随便读写内存的
global main
main:
mov ebx, 1
mov ecx, 2
add ebx, ecx
mov [sui_bian_xie], ebx
mov eax, [sui_bian_xie]
ret
section .data
sui_bian_xie dw 0
返回 3,没问题
注意:程序返回时eax寄存器的值,便是整个程序退出后的返回值,这是当下我们使用的这个环境里的一个约定,我们遵守便是。
第一行先不管,它表示接下来的内容经过编译后,会放到可执行文件的数据区域(data区),同时也会随着程序启动的时候,分配对应的内存。
第二行就是描述真实的数据的关键所在,这一行的意思是开辟一块2字节的空间,并且里面用0填充(当然,这里也可以是10,20,30等,是十进制的数)。这里的dw(define word)就表示2个字节(dd是指define double word,这个才是定义了32bits的空间),前面那个sui_bian_xie的意思就是这里可以随便写,也就是起个名字而已,方便自己写代码的时候区分,这个sui_bian_xie会在编译时被编译器处理成一个具体的地址,我们无需理会地址具体时多少,反正知道前后的sui_bian_xie指代的是同一个东西就行了。
反汇编
- 把反汇编的格式调整称为intel的格式
(gdb) set disassembly-flavor intel
- 查看main函数的反汇编代码
disas main
或者
disassemble main
ok 看看输出:

不错,与原代码差不多。
动态调试
- 注意看反汇编代码,每一行代码的前面都有一串奇怪的数字,这串奇怪的数字指它右边的那条指令在程序运行时的内存中的位置(地址)。注意,指令也是在内存里面的,也有相应的地址。
- 打断点
(gdb) break *0x080483f5
- 步进
(gdb) stepi
- 查看寄存器信息
(gdb) info register ebx
汇编语言入门四:打通C和汇编语言
-
test01反汇编出来的代码(test01, 是.c文件编译链接生成的机器码):

-
test02反汇编出来的代码(test02, 是汇编代码编译链接生成的机器码):

这里我们发现了,原来
mov eax, 2
mov [x], eax
可以被精简为一条语句:
mov [x], 2
汇编语言入门五:流程控制(一)if else if
eip 寄存器
- CPU里有一个寄存器专门存放“程序执行到哪里了”,这个执行位置的信息,是保存在叫做eip的寄存器中的。不过很遗憾,这个寄存器比较特殊,无法通过mov指令进行修改。
- 在执行一条指令的时候,eip此时代表的是下一条指令的位置,eip里保存的就是下一条指令在内存中的地址。
- 断点其实就是指在这个eip中存的位置
jmp 指令
- 实际上,C语言中的goto语句,在编译后就是一条jmp指令。它的功能就是直接跳转到某个地方,你可以往前跳转也可以往后跳转,跳转的目标就是jmp后面的标签,这个标签在经过编译之后,会被处理成一个地址,实际上就是在往某个地址处跳转,而jmp在CPU内部发生的作用就是修改eip,让它突然变成另外一个值,然后CPU就乖乖地跳转过去执行别的地方的代码了。
global main
main:
mov eax, 1
mov ebx, 2
jmp gun_kai
add eax, ebx
gun_kai:
ret
返回值是 1,而非 3。
if语句在汇编
global main
main:
mov eax, 50
cmp eax, 10 ; 对eax和10进行比较
jle xiaoyu_dengyu_shi ; 小于或等于的时候跳转
sub eax, 10
xiaoyu_dengyu_shi:
ret
if 语句 是 cmp 与 jxx 指令的组合
- 第一条,cmp指令,专门用来对两个数进行比较
- 第二条,条件跳转指令,当前面的比较结果为“小于或等于”的时候就跳转,否则不跳转
else if和else怎么办
若将以下c代码反编译成汇编代码
int main() {
register int grade = 80;
register int level;
if ( grade >= 85 ){
level = 1;
} else if ( grade >= 70 ) {
level = 2;
} else if ( grade >= 60 ) {
level = 3;
} else {
level = 4;
}
return level;
}
gdb反汇编代码:

状态寄存器
在汇编语言里面实现“先比较,后跳转”的功能时,即:
cmp xxx,xxx
jxx xxxxxxx
提问: 后面的跳转指令是怎么利用前面的比较结果的呢?
- CPU里面也有一个专用的寄存器,用来专门“记住”这个cmp指令的比较结果的,而且,不仅是cmp指令,它还会自动记住其它一些指令的结果。这个寄存器就是:eflags
- 名为“标志寄存器”,它的作用就是记住一些特殊的CPU状态,比如前一次运算的结果是正还是负、计算过程有没有发生进位、计算结果是不是零等信息,而后续的跳转指令,就是根据eflags寄存器中的状态,来决定是否要进行跳转的。
汇编语言入门六:流程控制(二) while 循环
将while循环拆解成只有if和goto的结构
while 循环
int sum = 0;
int i = 1;
while( i <= 10 ) {
sum = sum + i;
i = i + 1;
}
if 与 goto 语句
int sum = 10;
int i = 1;
_start:
if( i > 10 ) {
goto _end_of_block;
}
sum = sum + i;
i = i + 1;
goto _start;
_end_of_block:
逐行翻译成汇编代码
global main
main:
mov eax, 0
mov ebx, 1
_start:
cmp ebx, 10
jg _end_of_block
add eax, ebx
add ebx, 1
jmp _start
_end_of_block:
ret
nasm 编译看一下,结果妹问题

汇编语言入门七:函数调用(一)
函数调用需要做的事情
- 保存现场(一会好回来接着做)
- 传递参数(可选,套公式的时候需要些什么数据)
- 返回(把计算结果带回来,接着刚才的事)
示例代码
global main
eax_plus_1s:
add eax, 1
ret
ebx_plus_1s:
add ebx, 1
ret
main:
mov eax, 0
mov ebx, 0
call eax_plus_1s
call eax_plus_1s
call ebx_plus_1s
add eax, ebx
ret
运行程序,得到结果:3
- 陌生指令call,这个指令是函数调用专用的指令,从程序的行为上看应该是让程序的执行流程发生跳转。前面说到了跳转指令jmp,这里是call,这两个指令都能让CPU的eip寄存器发生突然变化
- 区别:
- jmp 跳过去了就不知道怎么回来了,
- call 这种方式跳过去后,是可以通过ret指令直接回来的
- 实现方式:在call指令执行的时候,CPU进行跳转之前还要做一个事情,就是把eip保存起来,然后往目标处跳。
- 当遇到ret指令的时候,就把上一次call保存起来的eip恢复回来,当eip恢复的时候,就意味着程序又会到之前的位置了。
- 一个程序免不了有很多次call,那这些eip的值都是保存到哪里的呢?有一个地方叫做“栈(stack)”,是程序启动之前,由操作系统指定的一片内存区域,每一次函数调用后的返回地址都存放在栈里面
- call总结:
- 本质上也是跳转,但是跳到目标位置之前,需要保存“现在在哪里”的这个信息,也就是eip
- 整个过程由一条指令call完成
- 后面可以用ret指令跳转回来
- call指令保存eip的地方叫做栈,在内存里,ret指令执行的时候是直接取出栈中保存的eip值,并恢复回去达到返回的效果
CPU中的栈
在实际的CPU中,上述的栈顶top也是由一个寄存器来记录的,这个寄存器叫做esp(stack pointer),每次执行call指令的时候。
在x86的环境下,栈是朝着低地址的方向伸长的。什么意思呢?每一次有东西入栈,那么栈顶指针就会递减一个单位,每一次出栈,栈顶指针就会相应地增加一个单位(和数据结构中一般的做法是相反的)。至于为什么会这样,我也不知道,可见以下计算机内存地址示意图:
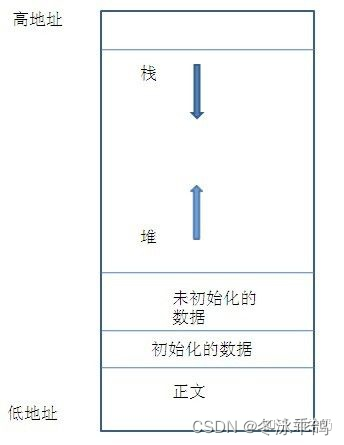
其中,栈正如一个倒放的杯子,最上面是栈底,最底下为栈顶,而内存地址从上至下为高地址到低地址,故每次入栈,栈顶指针esp需要往下移,也就是递减一个单位;而每次出栈,栈顶指针esp需要上移,也就是增加一个单位。
eip在入栈的时候,大致就相当于执行了这样一些指令:
sub esp, 4
mov dword ptr[esp], eip
翻译为C语言就是(假如esp是一个void*类型的指针):
esp = (void*)( ((unsigned int)esp) - 4 )
*( (unsigned int*) esp ) = (unsigned int) eip
也就是esp先移动,然后再把eip的值写入到esp指向的内存中。那么,ret执行的时候该干什么,也就非常的清楚了吧。无非就是上述过程的逆过程。
同时,eip寄存器的长度为32位,即4字节,所以每一次入栈出栈的单位大小都是4字节。
实操
asm代码:
global main
eax_plus_1s:
add eax, 1
ret
main:
mov eax, 0
call eax_plus_1s
ret
gdb调试:

- 已知 eip 是存储的下一个会被运行命令的位置。先打上断点在0x080483e9,利用 disas 可以看到,breakpoint 打到的位置正好是 eip 所存值的位置,表示这个位置指令还没有被运行(下一个就是你)。
- 此时看一看 esp 内存的值:0xffffd46c;再康康 esp 所存值指向的值(esp存的就是栈指针,所以可以指向其他内容): 0xf7e08647
- 步进到下一步,可以看到eip内的值被更新为 0x80483e0,也就是对应着被调函数的第一行代码所在位置。
- 此时,再观察esp的值变为了 0xffffd468,相较于之前 0xffffd46c,esp值减4,表示入栈一个元素,再看看此时esp所指向的值,可以见到 *(esp)为0x80483ee,也就是调用函数的下一行指令所在位置。
- 执行到ret时,esp会有出栈的动作,把所存的值pop到eip中。
汇编语言入门八:函数调用(二) 作用域
实际上,在汇编语言中,函数调用的参数和返回值均可以通过寄存器来传送,只要函数内外相互配合,就可以精确地进行参数和返回值传递。
通常eax会被用作参数和返回值,所以进入函数后就需要将eax保存到别的寄存器,一会需要的时候才能够更方便地使用。
以斐波那契数列为例:
C code:
int fibo(int n) {
if(n == 1 || n == 2) {
return 1;
}
return fibo(n - 1) + fibo(n - 2);
}
接近汇编形式的 C code:
int fibo(int n) {
if(n == 1) {
return 1;
}
if(n == 2) {
return 1;
}
int x = n - 1;
int y = n - 2;
int a = fibo(x);
int b = fibo(y);
int c = a + b;
return c;
}
汇编代码:
fibo:
cmp eax, 1
je _get_out
cmp eax, 2
je _get_out
mov edx, eax
sub eax, 1
call fibo
mov ebx, eax
mov eax, edx
sub eax, 2
call fibo
mov ecx, eax
mov eax, ebx
add eax, ecx
ret
_get_out:
mov eax, 1
ret
- 补全main函数使用gcc编译 C code 得到:
int fibo(int n) {
if(n == 1 || n == 2) {
return 1;
}
return fibo(n - 1) + fibo(n - 2);
}
int main(){
int a = 5;
return fibo(a);
}
输出第五个fib数为:5
- 补全汇编代码使用 nasm 编译得到:
global main
fibo:
cmp eax, 1
je _get_out
cmp eax, 2
je _get_out
mov edx, eax
sub eax, 1
call fibo
mov ebx, eax
mov eax, edx
sub eax, 2
call fibo
mov ecx, eax
mov eax, ebx
add eax, ecx
ret
_get_out:
mov eax, 1
ret
main:
mov eax, 5
call fibo
ret
输出为:4
可见汇编代码输出并不正确,答案应该是 5.
警惕作用域
- 实际上上述汇编语言等价为这样的C代码:
int ebx, ecx, edx;
void fibo() {
if(eax == 1) {
eax = 1;
return;
}
if(eax == 2) {
eax = 1;
return;
}
edx = eax;
eax = edx - 1;
eax = fibo(eax);
ebx = eax;
eax = edx - 2;
eax = fibo(eax);
ecx = eax;
eax = ebx + ecx;
}
原因很简单,CPU中的寄存器是全局可见的。所以使用寄存器,实际上就是在使用一个像全局变量一样的东西。仔细推导上述的汇编代码,可以发现出错的原因正是,edx寄存器里原本存的值一直被被调用函数覆盖。
利用栈
借鉴call指令保存返回地址的思路,如果,在每一层函数中都将当前比较关键的寄存器保存到堆栈中,然后才去调用下一层函数,并且,下层的函数返回的时候,再将寄存器从堆栈中恢复出来,这样也就能够保证下层的函数不会破坏掉上层函数的状态。
解决了这个问题:被调用函数在使用一些寄存器的时候,不能影响到调用者所使用的寄存器值。
- 进出栈操作:
push eax ; 将eax的值保存到堆栈中去
pop ebx ; 将堆栈顶的值取出并存放到ebx中
注意了,这里发生了入栈和出栈的情况,那么,进行栈操作的时候对应的栈顶指针也会发生相应的移动,这里也一样。
在上述代码中,除了使用eax之外,还有ebx,ecx,edx三个。为了保证这三个寄存器不会在不同的递归层级串场,我们需要在函数内使用它们之前将其保存起来,等到不用了之后再还原回去(注意入栈和出栈的顺序是需要反过来的)
global main
fib:
cmp eax, 1
je _out
cmp eax, 2
je _out
push ebx
push ecx
push edx
mov edx, eax
sub eax, 1
call fib
mov ebx, eax
mov eax, edx
sub eax, 2
call fib
mov ecx, eax
mov eax, ebx
add eax, ecx
pop edx
pop ecx
pop ebx
ret
_out:
mov eax, 1
ret
main:
mov eax, 5
call fib
ret
此时,输出为:5,结果正确。
C语言中的函数
在C语言中,x86的32位环境的一般情况下,函数的参数并不是通过寄存器来传递的,返回值也得视情况而定。这取决于编译器怎么做。实际上,一些基本数据类型,以及指针类型的返回值,一般是通过寄存器eax来传递的,也就是和前面写的汇编一个套路。而参数就不是了,C中的参数一般是通过堆栈来传递的,而非寄存器(当然也可以用寄存器,不过需要加一些特殊的说明)
- 示例代码:
#include <stdio.h>
int sum(int n, int a, ...) {
int s = 0;
int *p = &a;
for(int i = 0; i < n; i ++) {
s += p[i];
}
return s;
}
int main() {
printf("%d\n", sum(5, 1, 2, 3, 4, 5));
return 0;
}
函数的参数是逐个放到堆栈中的,通过第一个参数的地址,可以挨着往后找到后面所有的参数。你还可以尝试把参数附近的内存都瞧一遍,还能找到混杂在堆栈中的返回地址。
- 对上述代码进行编译后反汇编查看地址变化
- 编译与反汇编
gcc -m32 fn.c -o fn.o gdb ./fn.o- 设置查看模式等等 (先 run 一遍, 这里只关注参数传递)

-
可以看见参数连续存在栈中

-
可以看见调用处的下一条指令也存在栈中

补充
一、x86汇编的两种语法
x86汇编的两种语法:intel语法和AT&T语法
x86汇编一直存在两种不同的语法,在intel的官方文档中使用intel语法,Windows也使用intel语法,而UNIX平台的汇编器一直使用AT&T语法,所以本书使用AT&T语法。 mov %edx,%eax 这条指令如果用intel语法来写,就是 mov eax,edx ,寄存器名不加 % 号,并且源操作数和目标操作数的位置互换。直观来说:
在intel语法下:
mov eax,edx
在AT&T语法下:
mov %edx,%eax
含义是把 edx 的值放入到 eax
本书不详细讨论这两种语法之间的区别,读者可以参考[AssemblyHOWTO]。介绍x86汇编的书很多,UNIX平台的书都采用AT&T语法,例如[GroudUp],其它书一般采用intel语法,例如[x86Assembly]。
二、x86的寄存器
x86的通用寄存器有eax、ebx、ecx、edx、edi、esi。这些寄存器在大多数指令中是可以任意使用的。但有些指令限制只能用其中某些寄存器做某种用途,例如除法指令idivl规定被除数在eax寄存器中,edx寄存器必须是0,而除数可以是任何寄存器中。计算结果的商数保存在eax寄存器中(覆盖被除数),余数保存在edx寄存器。
x86的特殊寄存器有ebp、esp、eip、eflags。eip是程序计数器。eflags保存计算过程中产生的标志位,包括进位、溢出、零、负数四个标志位,在x86的文档中这几个标志位分别称为CF、OF、ZF、SF。ebp和esp用于维护函数调用的栈帧。
esp为栈指针,用于指向栈的栈顶(下一个压入栈的活动记录的顶部),而ebp为帧指针,指向当前活动记录的底部。每个函数的每次调用,都有它自己独立的一个栈帧,这个栈帧中维持着所需要的各种信息。寄存器ebp指向当前的栈帧的底部(高地址),寄存器esp指向当前的栈帧的顶部(低地址)。
注意:ebp指向当前位于系统栈最上边一个栈帧的底部,而不是系统栈的底部。严格说来,“栈帧底部”和“栈底”是不同的概念;esp所指的栈帧顶部和系统栈的顶部是同一个位置。
NASM与GDB的使用指南:如何编好你的汇编
存器有eax、ebx、ecx、edx、edi、esi。这些寄存器在大多数指令中是可以任意使用的。但有些指令限制只能用其中某些寄存器做某种用途,例如除法指令idivl规定被除数在eax寄存器中,edx寄存器必须是0,而除数可以是任何寄存器中。计算结果的商数保存在eax寄存器中(覆盖被除数),余数保存在edx寄存器。
x86的特殊寄存器有ebp、esp、eip、eflags。eip是程序计数器。eflags保存计算过程中产生的标志位,包括进位、溢出、零、负数四个标志位,在x86的文档中这几个标志位分别称为CF、OF、ZF、SF。ebp和esp用于维护函数调用的栈帧。
esp为栈指针,用于指向栈的栈顶(下一个压入栈的活动记录的顶部),而ebp为帧指针,指向当前活动记录的底部。每个函数的每次调用,都有它自己独立的一个栈帧,这个栈帧中维持着所需要的各种信息。寄存器ebp指向当前的栈帧的底部(高地址),寄存器esp指向当前的栈帧的顶部(低地址)。
注意:ebp指向当前位于系统栈最上边一个栈帧的底部,而不是系统栈的底部。严格说来,“栈帧底部”和“栈底”是不同的概念;esp所指的栈帧顶部和系统栈的顶部是同一个位置。
最后,本文所有的知识,都是学习来自@不吃油条 ,感谢他对知识的无私奉献。
NASM与GDB的使用指南:如何编好你的汇编
x86汇编程序基础(AT&T语法)
汇编入门














 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









