






目录
概念:
Apache™Hadoop®项目为可靠的,可扩展的分布式计算开发开源软件。
Apache Hadoop软件库是一个框架,它允许使用简单的编程模型跨计算机群集分布式处理大型数据集。它旨在从单个服务器扩展到数千台机器,每台机器提供本地计算和存储。该库本身不是依靠硬件来提供高可用性,而是设计用于在应用层检测和处理故障,从而在一组计算机之上提供高可用性服务,每个计算机都可能出现故障。
模块:
- Hadoop Common:支持其他Hadoop模块的常用工具。
- Hadoop分布式文件系统(HDFS):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
- Hadoop YARN:作业调度和集群资源管理的框架。
- Hadoop MapReduce:一种用于并行处理大型数据集的基于YARN的系统。
优点:
- 扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
- 成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
- 高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
- 可靠性(Reliable):hadoop能自动地维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
缺点:
- 不适合低延迟数据访问
- 无法高效存储大量小文件
- 不支持多用户写入及任意修改文件
常见的大数据产品及框架:

HDFS(Hadoop分布式文件系统)
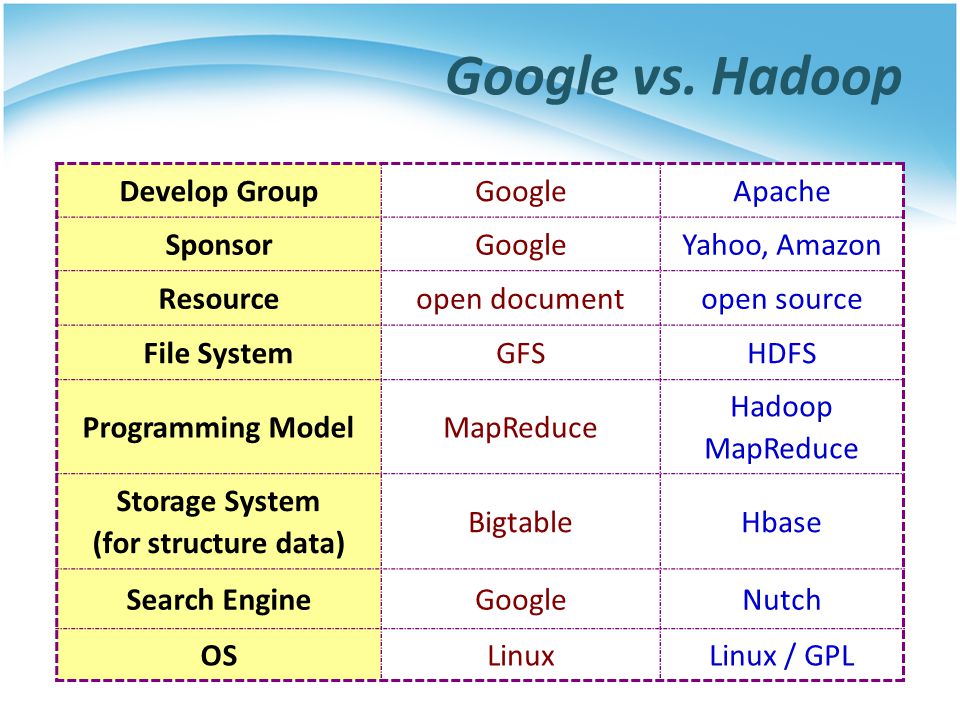
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS的实现版。HDFS是Hadoop体系中数据存储管理的基础,它是一个高度容错的系统,能检测和应对硬件故障,在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。HDFS提供一次写入多次读取的机制,数据以块的形式,同时分布存储在集群的不同物理机器上。
MapReduce(分布式计算框架)
源自于Google的MapReduce论文,发表于2004年12月,HadoopMapReduce是GoogleMapReduce克隆版。MapReduce是一种分布式计算模型,用以进行海量数据的计算。它屏蔽了分布式计算框架细节,将计算抽象成Map和Reduce两部分,其中Map对数据集上的独立元素进行指定的操作,生成键值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。
HBase(分布式列存数据库)
源自Google的BigTable论文,发表于2006年11月,HBase是GoogleBigTable的实现。HBase是一个建立在HDFS之上,面向结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。HBase采用了BigTable的数据模型,即增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
ZooKeeper(分布式协作服务)
源自Google的Chubby论文,发表于2006年11月,ZooKeeper是Chubby实现版。ZooKeeper的主要目标是解决分布式环境下的数据管理问题,如统一命名、状态同步、集群管理、配置同步等。Hadoop的许多组件依赖于ZooKeeper,它运行在计算机集群上面,用于管理Hadoop操作。
Hive(数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行,通常用于离线分析。HQL用于运行存储在Hadoop上的查询语句,Hive使不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
Pig(adhoc脚本)
由yahoo开源,其设计动机是提供一种基于MapReduce的adhoc(计算在query时发生)数据分析工具。Pig定义了一种数据流语言——PigLatin,它是MapReduce编程的复杂性的抽象,Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(PigLatin)。其编译器将PigLatin翻译成MapReduce程序序列,将脚本转换为MapReduce任务在Hadoop上执行,通常用于进行离线分析。
Sqoop(数据ETL/同步工具)
是SQL to Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是MapReduce程序,充分利用了MR的并行化和容错性。Sqoop利用数据库技术描述数据架构,用于在关系数据库、数据仓库和Hadoop之间转移数据。
Flume(日志收集工具)
是Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统,当然也可以用于收集其他类型数据。
Mahout(数据挖掘算法库)
起源于2008年,最初是ApacheLucent的子项目,它在极短的时间内取得了长足的发展,现在是Apache的顶级项目。Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便、快捷地创建智能应用程序。Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB或Cassandra)集成的数据挖掘支持架构。
YARN(分布式资源管理器)
是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。YARN是下一代Hadoop计算平台,是一个通用的运行时框架,用户可以编写自己的计算框架,在该运行环境中运行。
Mesos(分布式资源管理器)
是一个诞生于UCBerkeley的研究项目,现已成为Apache项目,当前有一些公司使用Mesos管理集群资源,如Twitter。与YARN类似,Mesos是一个资源统一管理和调度的平台,同样支持诸如MR、steaming等多种运算框架。
Spark(内存DAG计算模型)
是一个Apache项目,被标榜为“快如闪电的集群计算”,它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。最早Spark是UCBerkeleyAMPLab所开源的类HadoopMapReduce的通用并行计算框架,Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。
SparkGraphX
最先是伯克利AMPLab的一个分布式图计算框架项目,目前整合在Spark运行框架中,为其提供BSP大规模并行图计算能力。
SparkMLlib
一个机器学习库,它提供了各种各样的算法,这些算法用来在集群上针对分类、回归、聚类、协同过滤等。
Kafka
Linkedin于2010年12月开源的消息系统,主要用于处理活跃的流式数据。活跃的流式数据在Web网站应用中非常常见,这些数据包括网站的PV(PageView),用户访问了什么内容,搜索了什么内容等。这些数据通常以日志的形式记录下来,然后每隔一段时间进行一次统计处理。
ApachePhoenix
HBase的SQL驱动(HBaseSQL接口),Phoenix使得HBase支持通过JDBC的方式进行访问,并将你的SQL查询转换成HBase的扫描和相应的动作。
ApacheAmbari
安装部署配置管理工具,其作用就是创建、管理、监视Hadoop的集群,是为了让Hadoop以及相关的大数据软件更容易使用的一个Web工具。














 8356
8356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









