






算法介绍
SSD目标检测算法出现在Faster-RCNN和YOLOv1算法之后,融合了二者的优点的one-stage算法。速度比faster-RCNN更快,比YOLOv1算法准确率更高。
如果你对YOLOv1算法不了解的话,可以先了解一下。
关于YOLOv1目标检测算法的理解
英文名 SSD: Single Shot MultiBox Detector
论文地址:https://arxiv.org/abs/1512.02325
下面是该算法的具体表现:

可以看出SSD算法比Faster-RCNN的mAP还高出一点点,而且FPS高出三倍以上。而相比于YOLOv1,mAP有很大的提升。所以SSD算法不仅兼顾速度也兼顾准确率。但是遗憾的是还是无法满足实时性的要求,依然只能在高端硬件上面运行。
算法分析
我们先介绍一下网络结构,以下是YOLOv1和SSD算法的网络结构:

SSD算法前段网络采用的是改进后的VGG-16的网络结构,后端是用多个卷积层多尺度进行预测图片位置和种类,运用3x3xp的小卷积进行识别预测,大的特征图预测小的特征,小的特征图预测大的特征。他所用的思想和YOLO一样,把整个问题看成是个回归问题。
我们先来说一下VGG-16。
VGG-16是牛津大学2016年提出来的卷积神经网络模型,一经提出,就在简洁性和实用性方面表现突出,并迅速成为主流的神经网络结构。
 D组的模型就是VGG-16,由16层结构,包括卷积层、最大池化层和全连接层加最后的soft-max层。
D组的模型就是VGG-16,由16层结构,包括卷积层、最大池化层和全连接层加最后的soft-max层。
本文采用的是VGG-16前面的卷积层,保留部分网络到VGG-16的conv3-512层,去掉了后面的全链接层。
以上改进的VGG-16网络的作用是用来对图片进行特征提取。
后面不同尺度的卷积层用于多尺度特征的识别。
后面结构的目的是用来在不同的卷积层上进行检测。对于一个mxn大小p个通道的特征图。预测目标的基本元素是用3x3xp的小卷积核,用来产生种类的分数和默认框坐标的偏移值。SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。
默认框及它的长宽比:
把每个默认框与每个特征图的cell用卷积层的方式相关联,因此每个框与特征图的cell是一一对应的。在每个特征图的cell中,我们预测在cell里面的默认框的偏移值及每个种类的分数,每个点都有k个默认框,每个默认框由c个种类分数及4个坐标位置信息(xy坐标,及xy的偏移量),假设特征图为mxn,那么会产生(c+4)mnk个输出结果。
默认框的思想就是来自于Faster-RCNN的anchor和YOLO的回归思想。SSD算法是用多个个卷积层分别预测大小不同的物体。生成的特征图由大到小,大的特征图预测小物体,小的特征图预测大物体。
例如第一个特征图是38x38x1024,那么那张特征图的就有38x38个点,由于卷积的位置不变性可知,每个点都对应了输入图像的一个位置。那问题来了,为什么要有默认框呢?为什么不直接回归呢?就像YOLO算法一样。
为了提高速度,从而降低训练难度,每个点都有4个默认框或者6个。如下图:

那初始默认框是怎么产生的了?
初始的默认框也叫prior box
包括两个方面:中心点和长宽。
中心点的生成:
就以conv6那一层为例子,输入的图片为300x300x3,输出的特征图为19x19x1024,也就是每张特征图的大小为19x19。根据卷积神经网络的的位置不变性,那么特征图的每个点都对应着输入图像的一个中心点。
例如特征图的(2,2)位置对应在原图片的位置为(300/19x2,300/19x2)即(31,31)
长宽的生成:
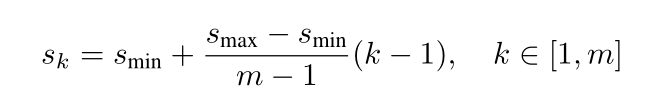
本文中的 Smin为0.2,Smax为0.9
所以最靠前的prior boxes的Sk为0.2,最靠后的prior boxes为0.9,中间层按照上面公式来。
使用不同的ratio值[1,2,3,1/2,1/3] 用下面的公式计算默认框的长宽:
w
=
s
k
∗
r
a
t
i
o
1
/
2
,
w
=
s
k
/
r
a
t
i
o
1
/
2
w=sk*ratio^{1/2}, w=sk/ratio^{1/2}
w=sk∗ratio1/2,w=sk/ratio1/2
当ratio为1时,
s
k
2
=
(
s
k
∗
s
k
+
1
)
1
/
2
sk^2=({sk*s{k+1}})^{1/2}
sk2=(sk∗sk+1)1/2
这样的话我们就可以生成6个不同的 prior boxes
匹配策略:
安装上面的方式,我们每个不同大小的特征图上面的每个点都会生成6个prior boxes,那么一共会生成
38x38x4+19x19x6+10x10x6+5x5x6+3x3x4+1x1x4=8732
为啥有的特征图每个点只有4个prior box,有些却有6个呢?
我也不知道!
问题来了,一张图片上面真的需要这么多prior boxes,显然是不需要的。这会大幅度增加耗时而且准确率也不高。
我们在生成prior box后,与原图的每个ground truth boxes相匹配,选择与其IOU最大的的先验框(best jaccard overlap),保证每个ground truth boxes都有一个prior boxes相匹配。被选择出来的prior boxes就是default boxes,保证每一个default boxes预测一个ground truth boxes,其他的prior boxes作为负样本,这也造成了大量的负样本。面对如此大的负样本,我们不可能全都加入训练中,所以以1:3的正负比例提取负样本,这也会使优化更快训练更稳定。
同时,该算法为了取得更好的效果使用了数据增强
每个训练图像从以下中随机选择一个:
1.使用整个原始图像
2.从图像中采样一个patch,与目标的最小值IOU为0.1,0.3,0.5,0.7,0.9
3.随机采样这个patch:
每个采样的patch为原图像的0.1到1,长宽比为0.5到2之间。当ground truth boxes的采样中心在采样的patch中时,保留重叠部分。在这个采样步骤之后,每个采样的patch转化为固定尺寸,以0.5的概率翻转。
我们现在已经得到了相当数量的样本
下面我们继续说一下如何从default box实现目标检测
以conv6为例,生成19x19x1024特征图
本文舍弃了传统的全连接层,而是用3x3的卷积层代替它的工作,这样做的目的是减少参数,加快运算速度。
试想一下如果用全链接层来进行检测工作,那么将19x19x1024的参数铺平后,就有19x19x1024=369664,如果后面接100个全链接的神经元,那么参数高达369966400。这将大大拖慢运算速度。
下面是整体的损失函数
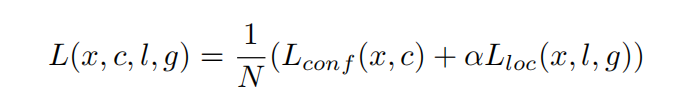
N代表的是匹配的default boxes的数量,N为0时损失值也为零。
你看的没错,位置和置信度的损失函数是一个公式。
 位置回归是典型的smooth L1 loss
位置回归是典型的smooth L1 loss
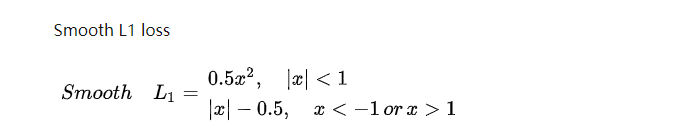
下面是置信度的回归
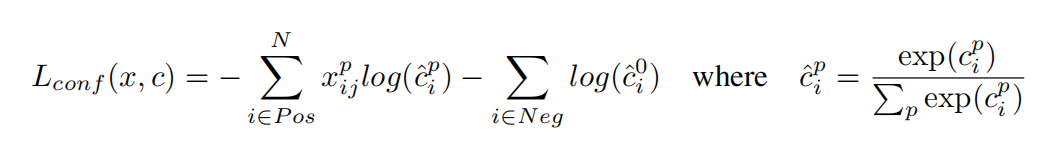
采用的是softmax的损失函数
重要补充
IOU是目标检测算法中一个非常重要的函数
全称是Intersection over Union,也就是交并比
也就是default boxes和ground truth boxes的交并比

NMS算法:由于直接由神经网络训练出来的结果有大量重复和重叠的框,这将大大加大训练的难度,所以论文采用了NMS算法来抑制默认框的产生以加快运算速度。
在这里就不详细介绍了。
以上是SSD算法的细节流程,可能有很多遗落的,希望指正!















 3062
3062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









