






今天看到微信公众号上推送了使用Stream流来减小 查询树形结构(因为存parentId,取树时多次查)压力,因此,相对自己代码进行下优化。
使用如下:
建立实体类
public class TaareaTreeVo implements Serializable {
private static final long serialVersionUID = 5857019442742853202L;
//行政区划ID
private String areaid;
//父级ID
private String parentid;
//行政区划名称
private String areaname;
//行政区划编码
private String areacode;
//行政区划层级
private Integer arealevel;
// 子节点数量
private Integer childNum;
//子节点
private List<TaareaTreeVo> children;
// 属性 对应 get/set方法
}/**
* 递归查询子节点
* @param root 根节点
* @param all 所有节点
* @return 根节点信息
*/
private List<TaareaTreeVo> getChildrens(TaareaTreeVo root,List<TaareaTreeVo> all){
List<TaareaTreeVo> childrens = all.stream().filter(m -> {
return Objects.equals(m.getParentid(), root.getAreaid());
}).map((m) -> {
m.setChildren(getChildrens(m, all));
return m;
}
).collect(Collectors.toList());
return childrens;
}调用
//先直接获取所有的节点
List<TaareaTreeVo> taareaList = taareaReadMapper.queryAllTree(areacode);
//将节点先进行过滤获取到根节点,然后根据根节点,通过递归查询子节点
List<TaareaTreeVo> taareaTree = taareaList.stream().filter((m) -> "0".equals(m.getParentid())).map((m) -> {
m.setChildren(getChildrens(m, taareaList));
return m;
}).collect(Collectors.toList());
System.out.println("===输出结果====");
System.out.println(JSON.toJSON(taareaTree));代码解释:
1、获取到行政区划树的所有节点,将装节点的list转成流
taareaList.stream()stream():对list 进行流化化操作,这是Collection类中的方法(List继承Conllection),能根据list返回一个对集合中的元素进行顺序排列有序的流
*当spliterator()方法不能返回spliterator时,应重写此方法

![]()
2、对流进行过滤
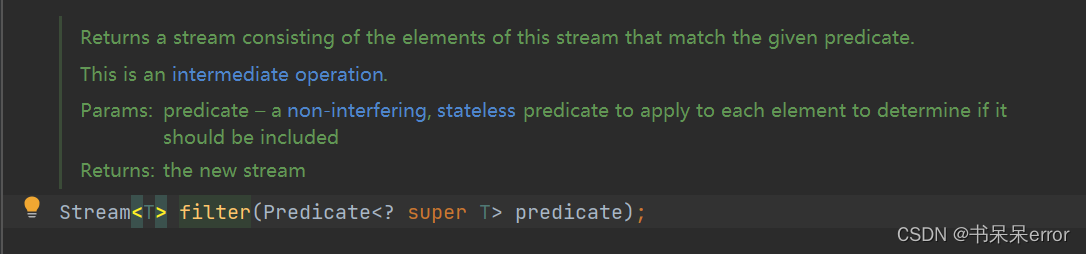
taareaList.stream().filter((m) -> "0".equals(m.getParentid()))filter(boolean)对流进行过滤操作, 遍历每个元素,进行比较,把所有条件符合的返回形成新的stream。( "0".equals(m.getParentid())便是条件,得到返回true的元素)
中间操作(intermediate operation),得到的是一个stream对象
![]()
3、获取元素的映射,进行递归操作,查询下级子节点
taareaList.stream().filter((m) -> "0".equals(m.getParentid())).map((m) -> { m.setChildren(getChildrens(m, taareaList)); return m; }) map(function)方法用于映射每个元素到对应的结果,map((m) -> { m.setChildren(getChildrens(m, taareaList)); return m; })中 ,(m)既获取到的流中的每个元素(Lambda 表达式),然后对每个元素进行操作。map()会把执行function后的返回值放入一个新的stream中,然后返回新的流
中间操作(intermediate operation)

![]()
4、对处理后的流进行类型转换,转换成最后我们需要的List类型
终端操作
taareaList.stream().filter((m) -> "0".equals(m.getParentid())).map((m) -> {
m.setChildren(getChildrens(m, taareaList));
return m;
}).collect(Collectors.toList());collect() 是一个终止方法,将流进行保存,Stream不调用终止方法,中间的操作不会执行
Collectors 类实现了很多归约操作,例如将流转换成集合和聚合元素。Collectors 可用于返回列表或字符串。
//<R> – the type of the result
//<A> – the intermediate accumulation type of the Collector
<R, A> R collect(Collector<? super T, A, R> collector);总结:
1、stream与集合的区别:
 ①无存储,流不是存储元素的数据结构,它只是某种数据源的一个视图,数据源可以是一个数据结构、数组、生成器函数或I/O通道;它通过计算操作的管道传递来自数据源的元素。
①无存储,流不是存储元素的数据结构,它只是某种数据源的一个视图,数据源可以是一个数据结构、数组、生成器函数或I/O通道;它通过计算操作的管道传递来自数据源的元素。
②流上的操作产生一个结果,但不修改其源。例如,过滤从集合中获得的Stream会生成一个没有过滤元素的新Stream,而不是从源集合中删除元素。
③惰式执行。许多流操作,如过滤、映射或重复删除,可以延迟实现,从而暴露出优化的机会。例如,“查找包含三个连续元音的第一个String”不需要检查所有的输入字符串。流操作分为中间(产生流)操作和终端(产生值)操作。中间操作总是惰性的(既操作并不会立即执行,只有当有终端操作时,才会执行中间操作)。
④可无上限。集合的大小是有限的,而流则不需要。像limit(n)或findFirst()这样的操作可以允许在有限的时间内完成无限流上的计算。
⑤可消费性。stream的元素在其生命周期中只会被访问一次。一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
⑥内部迭代: 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。stream使用内部迭代的方式, 通过访问者模式(Visitor)实现。
2、生成流的方式:
-
stream() − 为集合创建串行流。
-
parallelStream() − 为集合创建并行流。
-

当并行执行时,多个中间结果可能被实例化、填充和合并,以保持可变数据结构的隔离。因此,即使在与非线程安全的数据结构(如ArrayList)并行执行时,也不需要额外的同步来进行并行缩减。
获取流的方式(中间操作)
stream 可以分为串行流(sequential streams)、并行流(parallel streams)和无序流(unordered streams)
①串行流:对于串行流,不论流中元素的出现顺序是否已经定义好都不影响性能,只影响结果。如果流是有序的,对完全相同的流执行重复的操作会产生完全相同的结果。
list.stream().sequential()//是基础流串行化,获取串行流②并行流:对元素可并行处理的流可以转换成并行流进行处理,使中间操作处理更高效。
并行流上的操作必须满足三个特性:
a、无状态:对流中的每个元素单独处理,与流中其他元素无关(例:filter就是无状态的中间操作,只与当时操作的元素有关,而sorted就是有状态的,它同时和 比较和被比较元素有关)
b、不干预 :操作不会改变流
c、关联性:及在方法中先处理哪个元素不影响逻辑和结果
-list.stream().parallel()//解除顺序的限制,获取并行流 list.parallelStream()//直接获取并行流③无序流:流是否有序是指其元素出现顺序。有序流既 要么数据源有序,如:List、Arrays等,要么中间操作使流有序,如sorted()。
如果一个数据源无序,且中间操作不进行排序,则是一个无序流。(无序流能提升某些中间操作的并发性能)
list.stream().unordered()
3、常用中间操作:
<!--释义:类名::方法名 可以直接调用类下的该方法,详情见底-->
①filter: filter 方法用于通过设置的条件过滤出元素。Predicate断言,返回true/false,拿到为true的值的流
Stream<T> filter(Predicate<? super T> predicate);例:
List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
// 获取空字符串的数量
long count = strings.stream().filter(string -> string.isEmpty()).count();②limit:limit 方法用于获取指定数量的流。
ints:返回一个有效的无限制的伪随机int值流。(无穷大的int类型的数字流必须limit截断使用)
例:
Random random = new Random();
random.ints().limit(10).forEach(System.out::println);③sorted:sorted 使用自然顺序对流的元素进行排序。元素类必须实现Comparable接口,默认升序
例:
list.stream().sorted().forEach(System.out::println);若是想使用降序排序则使用Comparator提供reverseOrder()方法
例:
list.stream().sorted(Comparator.reverseOrder()).forEach(System.out::println);若想自定义的排序,可以传入Comparator作为参数
Stream<T> sorted(Comparator<? super T> comparator);例:
taareaList.stream().sorted(Comparator.comparing(TaareaTreeVo::getAreaid)).forEach(System.out::println);例:降序(将比较器翻转,相当于逆序)
taareaList.stream().sorted(Comparator.comparing(TaareaTreeVo::getAreaid).reversed()).forEach(System.out::println);④distinct:distinct()去重,返回由该流的不同元素组成的流。distinct()使用hashCode()和equals()方法来获取不同的元素,因此必须重写equels()和hashCode()
处理有序流,那么对于重复元素,将保留以遭遇顺序首先出现的元素。
list.stream().dictinct().count();//计算不重复元素个数有序流的并行流的情况下,保持distinct()的稳定性需要大量的缓冲开销,所以若不强制要求考虑数据顺序,可以使用BaseStream.unordered()来使流变为无序,从而节省空间。
例:
list.stream().unordered().distinct().findFirst();//每次获取第一个元素,可能等,可能不等,是随机取的⑤map:map(function)对流中的每个元素进行映射,进行function处理,将返回值放入新的流中(例如最上方的递归查询子元素)
<!--双冒号(::):方法引用(method reference)-->
静态方法引用(static method)语法:classname::methodname 例如:Person::getAge 对象的实例方法引用语法:instancename::methodname 例如:System.out::println 对象的超类方法引用语法: super::methodname 类构造器引用语法: classname::new 例如:ArrayList::new 数组构造器引用语法: typename[]::new 例如: String[]:new
<!--END-->
4、终端操作(缩减操作)
将流的元素合成一个总的结果。
①collect():
方法一:参数使用Collector。
Params:collector – the Collector describing the reduction //Collector
Type parameters:
<R> – the type of the result //返回值类型
<A> – the intermediate accumulation type of the Collector //集合元素类型
Returns:
the result of the reduction
<R, A> R collect(Collector<? super T, A, R> collector);Collectors中提供了一系列Collector(规约操作执行器),可直接调用来求值或转换成所需数据类型。
例:
//最大值
Collectors.maxBy();
//最小值
Collectors.minBy();
//总和
Collectors.summingInt();/Collectors.summingDouble();/Collectors.summingLong();
//平均值
Collectors.averagingInt();/Collectors.averagingDouble();/Collectors.averagingLong();
//总个数
Collectors.counting();
//转换成List
Collectors.toList();
//拼接
Collectors.joining();//joining(CharSequence delimiter, CharSequence prefix, CharSequence suffix); ---三个参数分别为分隔符、前缀、后缀
//转换成map
Collectors.toMap(key, value, (v1, v2) -> v1);//参数分别为:主键、值、key冲突时存哪个value
//分组
Collectors.groupingBy();//可分多个组
//分区
Collectors.partitioningBy();//分区只能分两个 true/false分组: //接收两个参数: 1.Function 参数 2.Collector多级分组
groupingBy(Function<? super T, ? extends K> classifier,Collector<? super T, A, D> downstream)
例:
studentStream.collect(Collectors.groupingBy(s -> {
if (s.getScore() >= 60) {
return "及格";
} else {
return "不及格";
}
}));
②reduce:缩减操作,指定的计算模型将Stream中的值计算得到一个最终结果
// 第一种
Optional<T> reduce(BinaryOperator<T> accumulator);
// 第二种
T reduct(T identity, BinaryOperator<T> accumulator);
// 第三种
<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
--identity 元素,既是缩减的初始操作元素(seed value),也是在流中没有元素时缩减的默认返回值(reduce 的返回类型与identity 类型相同)。
--accumulator函数(累加器),输入一个局部结果和下一个元素,输出一个新的局部结果(会作为下次累加器计算的第一个参数)
--combiner函数,将两个局部结果合并,产生一个新的局部结果(它必须与accumulator函数兼容)
例:
ArrayList<Integer> newList = new ArrayList<>();
ArrayList<Integer> accResult_ = Stream.of(2, 3, 4)
.reduce(newList,
(acc, item) -> {
acc.add(item);
System.out.println("item: " + item);
System.out.println("acc+ : " + acc);
System.out.println("BiFunction");
return acc;
}, (acc, item) -> null);
//最后会得到一个ArrayList类型的数据 reduce 详细可以看看这个大佬的:Java 1.8 新特性——Stream 流中 Reduce 操作_CSDN-Lemon的博客-CSDN博客_stream的reduce














 795
795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









