






持续更新中
| 模块 | 序号 | 目录 | 链接 |
|---|---|---|---|
| 前言介绍 | 1 | 前言 | 地址 |
| 2 | 介绍 | 地址 | |
| 基础知识 | 3 | 计算机网络 | 地址 |
| 4 | 操作系统 | 地址 | |
| 5 | Java基础 | 地址 | |
| 6 | Java并发 | 地址 | |
| 7 | Java虚拟机 | 地址 | |
| 中间件 | 8 | Mysql | 地址 |
| 9 | Redis | 地址 | |
| 10 | Elasticsearch | 地址 | |
| 11 | RabbitMQ | 地址 | |
| 12 | RocketMQ | 地址 | |
| 框架 | 13 | 分布式系统 | 地址 |
| 14 | MyBatis | 地址 | |
| 15 | Dubbo | 地址 | |
| 16 | Spring | 地址 | |
| 17 | Spring MVC | 地址 | |
| 18 | Spring Boot | 地址 | |
| 19 | Spring Cloud | 地址 | |
| 20 | Spring Cloud Alibaba Nacos | 地址 | |
| 21 | Spring Cloud Alibaba Sentinel | 地址 | |
| 22 | Spring Cloud Alibaba Seata | 地址 | |
| 23 | Tomcat | 地址 | |
| 24 | Netty | 地址 | |
| 容器 | 25 | Docker | 地址 |
| 26 | Kubernetes | 地址 | |
| 架构设计 | 27 | 场景架构设计 | 地址 |
| 28 | 领域驱动设计 | 地址 | |
| 29 | 设计模式 | 地址 | |
| 数据结构与算法 | 30 | 数据结构与算法 | 地址 |
| 31 | LeetCode题解 | 地址 |
Mybatis常见面试题
Mybatis常见面试题、Mybatis常见面试题
:::tips
- 什么是MyBatis?
MyBatis是一个优秀的持久层框架,它支持定制化SQL、存储过程以及高级映射。MyBatis避免了几乎所有的JDBC代码和手动设置参数以及获取结果集的工作。MyBatis可以使用简单的XML或注解进行配置和原始映射,将接口和Java的POJOs(Plain Old Java Objects,普通的Java对象)映射成数据库中的记录。 - MyBatis与Hibernate的主要区别是什么?
- SQL控制:MyBatis提供了手动编写SQL的能力,因此对SQL优化和调整有更大的控制权;而Hibernate则采用HQL或JPAQL,自动生成SQL,更偏向于自动化管理。
- 性能:由于MyBatis允许直接编写SQL,对于复杂的查询,其性能可能优于Hibernate。
- 学习曲线:Hibernate的学习曲线较陡峭,因为它是一个全功能的ORM框架;MyBatis相对简单,易于上手。
- 对象关系映射:Hibernate实现了完整的对象关系映射(ORM),而MyBatis则提供了数据映射的基本实现,更侧重于SQL本身。
- #{}和${}的区别是什么?
在MyBatis中,#{}用于动态参数绑定,它可以防止SQL注入,因为MyBatis会对其进行预编译处理。例如,SELECT * FROM table WHERE id = #{id}中的#{id}会被替换为实际值并进行预编译。
${} 则是字符串替换,不会进行预编译处理,因此存在SQL注入的风险,但可以用于拼接SQL片段或动态表名等。如 SELECT * FROM ${tableName},其中 ${tableName} 直接替换为变量值,不进行转义处理。
- MyBatis是如何进行分页的?
MyBatis本身没有直接提供分页功能,但可以通过以下几种方式实现:- 在SQL语句中使用LIMIT关键字(针对MySQL等支持LIMIT的数据库)。
- 使用RowBounds对象(但这种方式效率较低,因为它需要先获取所有数据再进行分页处理)。
- 自定义插件或者使用第三方分页插件(如PageHelper),这些插件可以在执行SQL前自动添加分页条件,提高效率。
- 如何在MyBatis中实现一对一和一对多的关联映射?
- 一对一关联:通常通过在映射文件中使用
<association>标签来实现。例如,一个用户有一个地址,可以在用户映射文件中定义一个<association>来映射地址实体。 - 一对多关联:使用
<collection>标签来实现。如果一个部门有多名员工,那么在部门的映射文件中,会定义一个<collection>来表示员工集合。
- 一对一关联:通常通过在映射文件中使用
- MyBatis的缓存机制有哪些?
MyBatis提供了两种级别的缓存:一级缓存(Session级别)和二级缓存(全局级别)。- 一级缓存:默认开启,作用域为SqlSession级别,当SqlSession关闭或提交事务后,该缓存就会清空。适用于单个应用请求周期内的数据缓存。
- 二级缓存:需要手动配置,作用域为Mapper的namespace级别,可以跨SqlSession使用,可以被所有共享相同Mapper配置的SqlSession访问。二级缓存是跨session的,且生命周期长,通常需要序列化和反序列化对象。
以上是部分关于MyBatis的常见面试问题及其答案,如果您有更具体的问题或想要了解其他方面的内容,请继续提问。
:::
Mybatis是什么
:::tips
MyBatis是一个流行的、轻量级的Java持久层框架,它简化了与数据库的交互,消除了大部分JDBC编码的重复工作。MyBatis最初被称为iBatis,后来改名为MyBatis。它不仅支持传统的SQL查询,还支持存储过程和高级映射。
MyBatis的核心特性包括:
- SQL映射:允许开发人员将SQL语句和Java方法直接关联起来,通过XML文件或注解来描述SQL语句和结果映射,这样可以将SQL代码从Java源代码中分离出去,使得代码更加清晰和可维护。
- 动态SQL:提供强大的动态SQL功能,可以根据传入参数的不同自动生成不同的SQL语句,无需手动拼接SQL字符串,这既提高了代码的安全性,也增强了SQL的灵活性。
- 结果映射:能够将查询结果直接映射到Java对象,无论是简单的查询还是复杂的关系映射,MyBatis都提供了相应的机制来处理,大大简化了数据转换的过程。
- 事务处理:MyBatis支持手动和自动管理事务,可以根据应用程序的需求选择合适的事务管理策略。
- 缓存机制:内置一级缓存(Session级别)和二级缓存(跨Session的全局缓存),可以有效减少数据库访问次数,提升系统性能。
总之,MyBatis提供了一种灵活且高效的方式来访问数据库,尤其适合那些对SQL性能有较高要求或者需要执行复杂SQL查询的项目。
:::
Mybatis优缺点
:::tips
MyBatis的优点:
- SQL控制力强:MyBatis允许直接编写SQL语句,这对于复杂的查询和优化提供了极高的自由度和控制力,开发者可以根据需求编写最符合实际应用场景的SQL。
- 性能高效:因为可以直接编写SQL,避免了ORM框架自动生成SQL可能带来的性能损耗,特别是在处理大量数据和复杂查询时,性能优势更为明显。
- 易于上手和集成:MyBatis相对于重量级的ORM框架如Hibernate来说,学习曲线较为平缓,同时它对项目的入侵性较小,易于与其他框架或现有系统集成。
- 提供映射标签和动态SQL:MyBatis提供了丰富的XML标签和动态SQL功能,使得映射复杂对象和编写条件查询变得更加方便和灵活。
- 缓存机制:虽然简单,但MyBatis的一级缓存和二级缓存机制能有效提升应用程序的运行效率,尤其是二级缓存可以在多个SqlSession间共享数据,减少数据库访问。
MyBatis的缺点:
- 工作量增加:相比于Hibernate等全自动化ORM工具,MyBatis需要手动编写SQL和结果映射,这在一定程度上增加了开发工作量,尤其是在处理大量的数据库表和字段时。
- SQL编写和维护成本:虽然直接编写SQL提供了灵活性,但这也意味着开发团队需要投入更多精力来维护SQL语句,特别是当数据库结构发生变化时,可能需要同步修改多个地方的SQL。
- 缺乏对象关系映射的全自动管理:MyBatis更侧重于SQL操作,而不是完全的ORM,这意味着对象关系的映射和维护不如Hibernate等框架自动化程度高,对于对象模型和数据库模型之间关系复杂的场景,管理成本较高。
- 可能的SQL注入风险:虽然通过使用
#{}参数可以避免大多数SQL注入问题,但在使用${}进行字符串替换时,如果处理不当,仍然存在SQL注入的风险。
综上所述,MyBatis是一个强大且灵活的工具,特别适合那些需要精确控制SQL、对性能有严格要求或者面对复杂数据库环境的项目,但同时也要求开发者具备一定的SQL知识和维护能力。
:::
Mybatis和Hibernate的区别
:::tips
MyBatis和Hibernate都是Java领域中广泛使用的持久层框架,它们各有特色,适用于不同场景。以下是两者之间的主要区别:
- SQL控制与自动化程度:
- MyBatis提供了更多的SQL控制自由度,开发者需要手动编写SQL语句,这使得针对特定需求进行SQL优化成为可能,适合复杂查询和性能敏感的应用。
- Hibernate采用的是声明式编程,通过HQL(Hibernate Query Language)或JPAQL(Java Persistence Query Language)来操作数据库,自动生成SQL,减少了手动编写SQL的工作量,更加面向对象,适合快速开发和对象关系模型相对简单的情况。
- 学习曲线和复杂度:
- MyBatis学习起来相对容易,因为它更接近原生的JDBC,理解成本低。
- Hibernate功能全面,提供了完整的对象关系映射(ORM)解决方案,包括事务管理、缓存策略等,因此学习曲线较陡,掌握起来需要更多时间。
- 性能:
- MyBatis由于直接编写SQL,可以做到高度优化,对于性能要求极高的应用而言,可能会表现得更好。
- Hibernate在自动管理对象关系映射时可能会引入一些性能开销,但对于标准CRUD操作,现代Hibernate版本通过优化也能达到很好的性能。
- 对象关系映射:
- MyBatis专注于SQL映射,对象关系的映射较为基础,更多依赖于手动处理。
- Hibernate提供了一个全面的ORM解决方案,可以自动管理对象状态的转换和数据库的同步,对于复杂的对象模型映射尤为有用。
- 适用场景:
- MyBatis更适合于那些对SQL有特定需求、需要精细控制SQL执行或是与遗留系统集成的项目。
- Hibernate则更适合那些追求开发效率、希望利用高级ORM特性、对象模型与数据库模型高度一致的项目。
总的来说,选择MyBatis还是Hibernate取决于项目需求、团队熟悉度以及对性能、控制力和开发效率的权衡。
:::
Mybatis的工作原理
Mybatis的工作原理是什么
:::tips
MyBatis是一个半自动化的ORM(Object-Relational Mapping,对象关系映射)框架,它简化了Java应用程序与SQL数据库之间的交互。MyBatis的工作原理主要包括以下几个核心步骤:
- 配置解析:MyBatis启动时,首先读取配置文件(如mybatis-config.xml),从中获取数据库连接信息、事务管理器、别名、类型处理器、插件配置等。同时,MyBatis会加载映射文件(Mapper XML),解析其中定义的SQL语句、结果映射等信息,并将其注册到SqlSessionFactory中。
- SqlSessionFactory构建:基于解析的配置和映射信息,MyBatis创建SqlSessionFactory。SqlSessionFactory是一个线程安全的工厂类,用于创建SqlSession实例。每个数据库对应一个SqlSessionFactory。
- SqlSession管理:应用程序通过SqlSessionFactory打开SqlSession,SqlSession是线程不安全的,代表一次数据库会话,提供了执行SQL、提交或回滚事务、获取映射器等操作。SqlSession中包含了一个Executor(执行器),负责SQL的执行。
- SQL执行:当调用SqlSession的方法执行SQL时,MyBatis会根据SQL映射文件中的配置动态生成SQL语句。Executor根据不同的执行器类型(如SIMPLE、REUSE、 BATCH)执行SQL,并处理结果。
- 对于查询操作,MyBatis会根据
<resultMap>映射配置,将查询结果转换为Java对象或对象列表。 - 对于插入、更新、删除操作,执行相应的SQL语句,并根据配置处理事务。
- 对于查询操作,MyBatis会根据
- 事务管理:MyBatis支持手动和自动事务管理。通过SqlSession的commit、rollback方法来提交或回滚事务。MyBatis可以配置JDBC事务或集成第三方事务管理器(如Spring的事务管理)。
- 缓存处理:MyBatis提供了一级缓存(本地缓存,基于SqlSession)和二级缓存(全局缓存,基于命名空间)。在执行查询前,MyBatis会检查缓存中是否存在所需数据,如果存在则直接返回,减少数据库访问。每次执行增删改操作后,相关缓存会被清空或更新。
- 结果映射:MyBatis使用结果映射将查询结果中的列与Java对象的属性进行匹配,支持基本类型、复杂类型、一对一、一对多等多种映射关系。
- 动态SQL:MyBatis支持在XML映射文件中使用动态SQL标签(如
<if>、<choose>、<foreach>等),根据传入参数动态拼接SQL语句,提供灵活的查询能力。 - 资源关闭:使用完SqlSession后,应确保关闭它以释放资源。虽然SqlSession提供了自动关闭的机制(如使用try-with-resources),但良好的实践是显式关闭以保持代码的清晰和资源管理的明确。
通过这一系列步骤,MyBatis将Java方法调用转换为数据库操作,实现了对象与关系数据的桥梁作用,极大地简化了数据访问层的编码工作。
:::
Mybatis的功能架构
Mybatis的功能架构是怎样的
:::tips
MyBatis的功能架构主要由以下几个核心组件构成,它们共同协作以实现高效、灵活的数据库访问功能:
- 配置解析器:负责解析MyBatis的配置文件(mybatis-config.xml)和映射文件(Mapper XML),将配置信息和SQL映射信息转换为数据结构(如Configuration对象),为后续的数据库操作准备必要的配置信息。
- SqlSessionFactoryBuilder:该组件根据配置解析器解析出的Configuration对象构建SqlSessionFactory。这个过程主要是实例化SqlSessionFactory,并将配置信息和映射信息注入到SqlSessionFactory中。SqlSessionFactoryBuilder是一个临时对象,构建完成后即可丢弃。
- SqlSessionFactory:这是MyBatis的核心组件之一,扮演着数据库连接工厂的角色。每个数据库对应一个SqlSessionFactory,它负责创建SqlSession实例。SqlSessionFactory是线程安全的,可以被多个线程共享使用。
- SqlSession:代表了MyBatis与数据库之间的一次会话,它是线程不安全的,不能被共享。SqlSession提供了执行SQL、获取映射器、提交事务、回滚事务等操作。每次数据库交互通常都始于创建一个新的SqlSession实例,并在操作完成后关闭它。
- Executor(执行器):位于SqlSession内部,是实际执行SQL的组件。Executor有多种类型(如SimpleExecutor、ReuseExecutor、BatchExecutor等),每种类型的Executor提供了不同的执行策略,以适应不同的性能需求。Executor负责管理查询缓存、事务、二级缓存以及异常处理等。
- StatementHandler(语句处理器):负责处理PreparedStatement的创建、设置参数、执行SQL以及处理结果集。它与数据库驱动交互,将SQL命令发送给数据库,并接收结果。
- ParameterHandler(参数处理器):负责在执行SQL前对参数进行处理,包括参数类型转换、设置PreparedStatement参数等。
- ResultSetHandler(结果集处理器):负责将执行SQL后得到的ResultSet结果集转换为Java对象。它根据映射配置(resultMap)将结果集中的每一行数据映射成Java对象或对象集合。
- TypeHandler(类型处理器):负责Java类型与数据库类型之间的转换工作。每个数据库类型(如VARCHAR、INTEGER等)和Java类型(如String、Integer等)都有对应的TypeHandler,用于在Java对象和数据库字段值之间进行转换。
- 缓存机制:MyBatis提供了两级缓存机制。一级缓存是基于SqlSession的本地缓存,生命周期与SqlSession相同;二级缓存是基于命名空间的全局缓存,可以被所有SqlSession共享,提高查询效率。
通过这些组件的紧密协作,MyBatis实现了从配置加载、SQL执行、结果映射到缓存管理的完整数据库操作流程,为开发人员提供了简洁、高效的数据库访问接口。
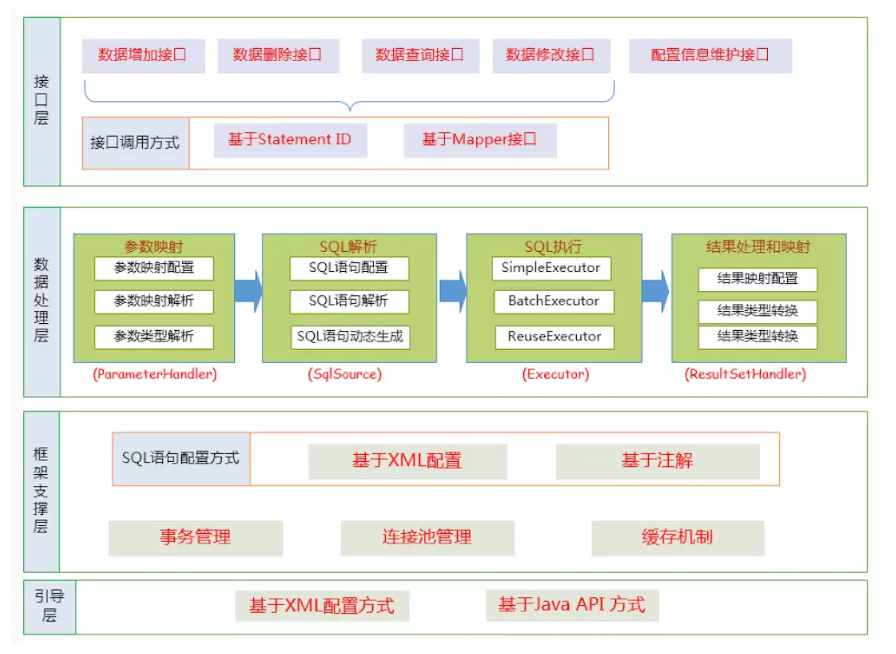
:::
Mybatis的框架架构设计
Mybatis的框架架构设计是怎样的
:::tips
MyBatis的框架架构设计遵循了模块化和分层的原则,旨在提供一个灵活、高效、易于使用的ORM框架。其核心架构大致可以分为以下几个层次:
1. 配置层(Configuration Layer)
- 配置解析:MyBatis通过XML配置文件(如mybatis-config.xml)和Mapper映射文件来配置数据库连接信息、事务管理、映射关系等。框架首先解析这些配置文件,构建出
Configuration对象,该对象包含了MyBatis运行所需的全部配置信息。 - 类型别名、类型处理器:配置层还负责注册Java类型别名和类型处理器,使得Java类型与数据库类型之间能够顺畅转换。
2. 核心层(Core Layer)
- SqlSessionFactory:这是MyBatis的工厂类,负责创建SqlSession实例。基于配置信息,SqlSessionFactory构建了一个包含数据库连接、事务管理、缓存策略等核心服务的环境。
- SqlSession:代表了应用程序与数据库之间的一次会话,提供执行SQL、获取Mapper接口代理对象、管理事务等功能。SqlSession是线程不安全的,每次数据库交互建议使用新的SqlSession实例。
- Executor(执行器):负责SQL语句的执行,包括查询缓存的使用、事务边界、二级缓存的维护等。不同的Executor实现提供了不同的执行策略,以满足不同场景下的性能需求。
3. SQL执行层(SQL Execution Layer)
- StatementHandler(语句处理器):负责SQL语句的预编译、参数设置、执行及结果集处理。它是MyBatis与数据库交互的直接接口。
- ParameterHandler(参数处理器):负责SQL语句执行前的参数处理,包括参数类型转换和绑定。
- ResultSetHandler(结果集处理器):负责将数据库查询结果集转换为Java对象,依据
ResultMap完成复杂结果集的映射。 - TypeHandler(类型处理器):实现Java类型与数据库类型之间的双向转换,保证数据的正确传输。
4. 映射层(Mapping Layer)
- Mapper XML:定义了SQL语句和结果映射,MyBatis通过解析这些文件来了解如何执行SQL以及如何将结果映射到Java对象上。
- Mapper接口:提供了面向对象的方式来调用SQL,MyBatis通过动态代理技术,使得接口方法调用能够映射到具体的SQL执行上。
- 动态SQL:支持在Mapper XML中使用动态标签,如
<if>、<choose>、<foreach>等,根据运行时参数动态生成SQL语句,增强了SQL的灵活性和可重用性。
5. 缓存层(Cache Layer)
- 一级缓存(Local Cache):位于SqlSession级别,自动维护,对当前会话中的多次相同查询结果进行缓存,提高查询效率。
- 二级缓存(Global Cache):位于SqlSessionFactory级别,可被所有SqlSession共享,通过Namespace隔离,适用于不经常更改且经常查询的数据,进一步提升系统性能。
6. 插件与扩展(Plugins and Extensions)
MyBatis提供了一套插件机制,允许用户通过拦截器(Interceptor)的方式,对核心组件如Executor、ParameterHandler等进行扩展,实现自定义功能,如日志记录、性能监控、自定义缓存策略等。
综上所述,MyBatis的架构设计围绕着解耦、灵活性和高性能展开,通过分层和模块化的设计,使得开发者可以根据需要定制化地使用框架,满足复杂多变的业务需求。
:::
Mybatis的预编译
说一下Mybatis的预编译,为什么需要预编译
:::tips
MyBatis中的预编译(也称为参数化查询或预处理语句)是指在执行SQL语句之前,数据库驱动程序会先解析SQL语句的结构,并为它编译一个执行计划,然后在真正执行时再将参数值绑定到这个已经预编译好的SQL模板上。这种做法对比传统的字符串拼接SQL有以下几个显著优点:
- 安全性提升:预编译最显著的优点是能够有效防止SQL注入攻击。因为参数不是直接嵌入到SQL文本中,而是作为单独的参数传递给数据库,即使参数包含恶意的SQL代码,也不会影响到SQL的结构,从而确保了查询的安全性。
- 性能优化:数据库服务器会对预编译的SQL语句进行分析、编译和优化,这个过程只在第一次执行时发生。之后,对于相同的SQL结构(仅参数变化),数据库可以直接复用之前的执行计划,减少了编译和解析的时间,提高了执行效率。这对于高并发或频繁执行的查询尤为重要。
- 减少错误:预编译可以避免因手动拼接SQL导致的语法错误,特别是当SQL语句较为复杂或者包含多个参数时,使用预编译可以减少因字符串格式错误导致的问题。
在MyBatis中,预编译是通过PreparedStatement实现的。当MyBatis执行一个带有参数的SQL语句时,它会使用PreparedStatement来设置参数值,而不是直接将参数值拼接到SQL字符串中。例如,在Mapper的XML文件中,你可以看到如#{}这样的占位符,这些占位符在执行时会被实际的参数值替换,而不会参与到SQL的字面构造中。

在这个例子中,#{id}就是预编译的占位符,当执行这个查询时,MyBatis会使用PreparedStatement预编译SQL,然后将传入的参数值安全地绑定到这个预编译的SQL语句上,确保了执行效率和安全性。
:::
#{}和${}的区别
:::tips
在MyBatis中,#{} 和 ${} 都是用来动态地向SQL语句中插入参数的占位符,但它们的处理方式和应用场景有着本质的区别:
- #{}(预编译参数):
- 安全性:
#{}是安全的占位符,它会将参数自动进行预编译处理,有效防止SQL注入攻击。这是因为MyBatis会把#{}中的内容替换为PreparedStatement中的参数,并自动做类型转换和安全转义。 - 使用场景:适合用于传入具体的值,比如数字、字符串等,用于WHERE子句中的条件判断、IN语句的值列表等。
- 示例:
SELECT * FROM users WHERE username = #{username}。在这个例子中,#{username}会被替换为实际的用户名值,并作为PreparedStatement的一部分安全执行。
- 安全性:
- ${}(字符串替换):
- 安全性:
${}不会对内容进行预编译处理,而是直接进行字符串替换。这意味着如果直接使用来自用户输入的内容,可能会导致SQL注入的风险。 - 使用场景:主要用于需要进行字符串拼接的情况,比如表名、列名或者动态生成部分SQL语句时。但是,使用
${}时必须非常小心,确保插入的变量是安全的,不受外部恶意控制。 - 示例:
SELECT * FROM ${tableName}。如果tableName变量的值为users,则生成的SQL为SELECT * FROM users。这里假设tableName的来源是可信的,否则可能导致SQL注入。
- 安全性:
总结来说,#{} 更加安全,适用于绝大多数情况下的参数传递,而${} 提供了更多的灵活性,但也伴随着手动处理字符串的风险,应当谨慎使用。在可能的情况下,优先推荐使用#{}以保持SQL语句的安全性。
:::
resultType和resultMap的区别
:::tips
在MyBatis中,resultType 和 resultMap 都是用来指定查询结果如何映射到Java对象上的,但它们的工作方式和应用场景有所不同:
- resultType:
- 简明直接:
resultType属性用于简单的情况,当你查询的结果列与JavaBean的属性一一对应时,可以直接指定这个属性为JavaBean的全限定类名。MyBatis会自动将查询结果映射到指定类型的对象中。 - 限制:它不支持列名与JavaBean属性名不匹配的情况,也不支持复杂类型(如一对一、一对多关联映射)的处理。适用于查询结果结构简单,且数据库列名与Java对象属性名相同时。
- 简明直接:
- resultMap:
- 强大灵活:当查询结果需要更复杂的映射,如列名与Java对象属性名不一致、需要处理一对一或多对一关联、集合关联等情况时,就需要用到
resultMap。resultMap允许你自定义映射规则,包括指定列名到属性名的映射、构造复杂类型等。 - 结构:
resultMap内部可以包含多个id(唯一标识符)、result(普通属性映射)、association(一对一关联)、collection(一对多关联)等元素,提供了高度的定制化能力。 - 重用性:定义好的
resultMap可以在多个查询中重用,提高代码的复用性和维护性。
- 强大灵活:当查询结果需要更复杂的映射,如列名与Java对象属性名不一致、需要处理一对一或多对一关联、集合关联等情况时,就需要用到
总结来说,resultType适用于简单查询结果的映射,而resultMap则提供了更强大的映射功能,适合处理复杂的数据结构和关联关系。当查询结果较为复杂或者需要进行额外的转换逻辑时,应首选resultMap。
:::
怎么进行批量操作
:::tips
在MyBatis中进行批量操作(如批量插入、更新或删除),可以通过以下几种方式实现,以提高执行效率和减少数据库的往返次数:
1. 使用foreach标签
批量插入示例:

- collection:表示要遍历的集合参数名,通常是传递给Mapper方法的一个List。
- item:表示集合中每一个元素的别名,用于在SQL语句中引用。
- separator:定义每个元素之间的分隔符,通常是逗号
,。
2. 使用Mapper接口和XML映射
确保你的Mapper接口中定义了批量操作的方法,XML映射文件中正确配置了批量操作的SQL语句,然后通过调用Mapper接口的方法来执行批量操作。
注意事项:
- 事务管理:批量操作时,确保所有操作在一个事务中完成,最后统一提交,以保证数据一致性。
- 错误处理:批量操作中如果某条记录执行失败,可能会影响整个批次的操作。根据业务需求,决定是否需要捕获异常并进行部分回滚或记录日志。
- 性能监控:监控批量操作的性能,合理设置批量操作的大小,避免因批量太大而导致内存溢出或数据库负载过高。
通过上述方法,可以在MyBatis中有效地执行批量操作,提高数据处理的效率。
:::
Dao接口的工作原理
Dao接口的工作原理是什么
:::tips
DAO(Data Access Object)设计模式是一种编程模式,用于隔离低层的数据访问API(如JDBC)与高层的业务服务逻辑。在MyBatis框架中,DAO接口的工作原理结合了Java的接口技术和MyBatis的映射配置,实现了数据访问逻辑的抽象与实现分离,提升了代码的可维护性和可测试性。其工作原理大致可以分为以下几个步骤:
- 定义DAO接口:首先,开发者定义一个Java接口,这个接口通常包含了一系列操作数据库的方法声明,比如查询、插入、更新和删除等。接口方法的命名通常反映了它所执行的数据库操作。
- 映射文件(Mapper XML):为每个DAO接口创建一个对应的XML映射文件,这个文件中包含了SQL语句以及如何将SQL查询结果映射到Java对象的具体配置。每个接口方法在映射文件中都有一个与之对应的
<select>,<insert>,<update>, 或<delete>标签。 - MyBatis配置:在MyBatis的主配置文件中,需要注册这些映射文件,或者通过自动扫描的方式让MyBatis发现它们。
- SqlSession与Mapper动态代理:当应用程序需要执行数据库操作时,通过SqlSession工厂获取一个SqlSession实例。MyBatis通过Java的动态代理技术,为DAO接口生成一个代理对象。这个代理对象能够拦截对DAO接口方法的调用,根据方法名找到对应的映射文件中的SQL语句,然后执行SQL并处理结果。
- 结果映射:执行完SQL后,MyBatis根据映射文件中的配置,将查询结果映射为Java对象或对象集合,然后通过DAO接口方法返回给调用者。
- 事务管理:在整个过程中,SqlSession也负责事务的管理,确保数据库操作的原子性和一致性。
通过这种机制,开发者可以只关注业务逻辑的实现,而不必关心底层数据访问的细节,提高了代码的模块化和可重用性。同时,由于SQL语句与业务逻辑分离,便于维护和优化数据库访问逻辑。
:::
Mybatis怎么实现分页
:::tips
MyBatis本身并没有直接提供内置的分页功能,但提供了几种常见的实现分页的方法:
1. 使用SQL语句自带的分页功能
对于支持LIMIT或OFFSET语法的数据库(如MySQL、PostgreSQL等),可以直接在SQL语句中加入分页关键字来实现分页。

在Java代码中,你需要传递offset和limit(或pageIndex和pageSize)作为参数调用这个查询方法。
2. 使用RowBounds
MyBatis提供了RowBounds接口来实现分页,但它不是一个高效的分页解决方案,因为它实际上会先加载所有满足条件的数据,然后再在内存中进行分页处理。

尽管这种方法简单,但因为它加载了所有数据,对于大数据量的查询效率低下,不推荐在生产环境中使用。
3. 使用MyBatis的插件机制或第三方分页插件
为了更高效地实现分页,推荐使用MyBatis的插件机制或集成第三方分页插件,如PageHelper、MyBatis-Plus的分页插件等。
PageHelper插件示例:
- 添加依赖:首先,在Maven或Gradle项目中添加PageHelper的依赖。
- 配置插件:在MyBatis的配置文件中配置PageHelper插件。

- 使用插件:在Java代码中,只需在执行查询前设置分页信息即可。

PageHelper会在执行SQL之前自动修改查询语句,添加分页相关的LIMIT或OFFSET子句,从而实现真正的物理分页,避免了内存分页的性能问题。
通过上述方法,你可以根据实际情况选择合适的分页策略来实现MyBatis的分页功能。
:::
Mybatis懒加载
Mybatis支持懒加载吗?原理是什么
:::tips
MyBatis支持懒加载,主要体现在关联查询上,如一对一、一对多的关联关系。懒加载的原理是在访问关联对象时,如果该对象尚未加载,则延迟到第一次真正访问该对象时才去数据库查询并加载数据。
原理说明:
- 延迟加载(Lazy Loading):这是一种按需加载数据的技术,只有在真正需要使用某个对象时,才会去数据库加载该对象的数据。这有助于减少初次加载数据时的内存占用,提高应用的响应速度,尤其是在处理大型数据集和深层次对象图时效果显著。
- 实现机制:在MyBatis中,懒加载主要通过
resultMap中的association和collection元素的lazyLoadingEnabled属性来控制。默认情况下,MyBatis的懒加载是关闭的,需要在MyBatis的配置文件中全局开启,或者在特定的resultMap中开启。 - 配置示例:
在MyBatis的配置文件中全局开启懒加载:

或在特定的resultMap中开启懒加载:

- 工作流程:
- 当查询用户信息时,如果地址信息设置了懒加载,MyBatis不会立即执行关联的SQL(如查询地址信息的SQL)。
- 当应用程序首次尝试访问用户的地址信息时(如调用
getUser().getAddress()),MyBatis才执行关联查询的SQL,从数据库加载地址数据。 - 这个过程通常通过动态代理实现,当访问代理对象的延迟加载属性时,代理对象会检查数据是否已加载,如果没有,则执行加载逻辑。
注意点:
- 懒加载可能增加应用的复杂度,因为它引入了延迟行为,可能会导致N+1查询问题,影响性能,因此在使用时需要权衡。
- 在某些场景下,如Web应用中,需要特别注意懒加载和作用域的问题,以避免在序列化或视图渲染时触发不必要的数据库查询。
总之,MyBatis的懒加载机制为处理关联数据提供了灵活性,允许开发者根据需要优化数据加载策略,以平衡性能和资源消耗。
:::
Mybatis一级二级缓存
介绍下Mybatis的一级二级缓存
:::tips
MyBatis 提供了两层缓存机制来提高查询效率,分别是一级缓存(本地缓存/Session缓存)和二级缓存(全局缓存)。
一级缓存(Local Cache)
概念:一级缓存是MyBatis内部自动维护的一个基于Per-Session的缓存,它位于SqlSession级别。每当一个SqlSession被创建时,MyBatis就会创建一个与之相关联的缓存空间。这个缓存会存储在当前SqlSession执行的所有查询结果。当相同的SQL语句再次被执行时(在同一个SqlSession内),MyBatis会首先查看一级缓存中是否存在结果,如果有则直接返回,避免了数据库的重复访问。
生命周期:一级缓存的生命周期和SqlSession相同,即SqlSession关闭时,一级缓存也会被清空。此外,任何对数据库的增删改操作都会清空一级缓存。
使用:一级缓存是MyBatis默认启用的功能,无需额外配置即可使用。
二级缓存(Global Cache)
概念:二级缓存是应用级别的缓存,它可以被所有SqlSession共享,且生命周期比一级缓存长,通常跨越整个应用的生命周期。二级缓存是跨SqlSession的,因此可以大幅度提升效率,尤其是对于那些频繁读取且不经常改变的数据。
配置与使用:
- 开启全局二级缓存:在MyBatis的配置文件(mybatis-config.xml)中开启全局二级缓存。

- 映射文件中配置:在需要使用二级缓存的Mapper的XML映射文件中,通过
<cache>标签来启用,并可以配置缓存的属性,如 eviction(清除策略)、flushInterval(刷新间隔)等。

- 实体类实现序列化:为了使二级缓存生效,被缓存的对象(查询结果的实体类)必须实现序列化接口(Serializable),以便在分布式环境下可以被序列化和反序列化。
失效策略:二级缓存的更新策略比较复杂,通常在执行插入、更新、删除操作时会自动清除或更新缓存,也可以通过设置缓存的刷新策略来定时清理。
注意事项:
- 二级缓存对于多线程和分布式环境需要特别考虑,确保数据的一致性和时效性。
- 由于二级缓存是全局的,所以在处理敏感数据或频繁变更的数据时,要谨慎使用,以免造成数据不一致的问题。
总之,MyBatis的一级缓存适用于单次数据库会话内的重复查询优化,而二级缓存则提供了跨会话的查询结果复用,能显著提升应用程序的整体性能,但使用时需要仔细设计和配置以避免潜在问题。
:::
XML中常用标签
XML中有哪些常用标签
:::tips
在MyBatis的XML映射文件中,有多种标签用于定义SQL语句及结果映射,以下是一些常用的标签及其用途:
**<select>**:用于执行查询语句,映射到SQL SELECT语句。可以返回单个对象、对象列表或Map集合。**<insert>**:用于执行插入语句,映射到SQL INSERT语句。可以用来插入新记录到数据库中。**<update>**:用于执行更新语句,映射到SQL UPDATE语句。用于修改数据库中的现有记录。**<delete>**:用于执行删除语句,映射到SQL DELETE语句。用于从数据库中删除记录。**<resultMap>**:定义结果集如何映射到Java对象。可以指定列名到对象属性的映射,以及处理一对一、一对多等复杂关系。**<association>**:在<resultMap>中使用,用于处理一对一关联关系。定义嵌套结果集的映射规则。**<collection>**:也在<resultMap>中使用,用于处理一对多关联关系。描述如何将查询结果中的多个重复结果映射为集合属性。**<paramterType>**:在<select>,<insert>,<update>,<delete>标签中使用,指定传入参数的类型,可以是基本类型、Java Bean或数组、集合等。**<result>**:在<select>标签的直接子元素或<resultMap>中使用,用于简单映射,指定列名和属性名的对应关系。**<include>**:用于包含其他XML片段,以减少重复的SQL代码,提高代码的可维护性。**<where>**:动态生成WHERE子句,根据传入参数的非空情况自动包含或排除条件。**<if>**、**<choose>**、**<when>**、**<otherwise>**:用于条件判断,支持动态SQL编写,可以根据参数值的不同执行不同的SQL片段。**<foreach>**:用于迭代集合,常用于IN语句中,将集合中的每个元素作为查询条件的一部分。**<sql>**:定义可重用的SQL代码片段,通过<include>标签在其他地方引用。**<cache>**:配置二级缓存的属性,可以在Mapper的XML文件中定义,控制缓存的行为和策略。
这些标签构成了MyBatis映射文件的基础,通过它们可以灵活地定义SQL查询、更新语句以及结果映射规则,实现Java对象与数据库记录之间的转换。
:::
自动生成主键值
如何获取自动生成的主键值
:::tips
在MyBatis中,如果你使用的是自增长的主键(如MySQL的AUTO_INCREMENT或SQL Server的IDENTITY列),在插入新记录后,你可能需要获取由数据库自动生成的主键值。MyBatis提供了几种方式来实现这一点,具体取决于你的应用场景和使用的数据库。
1. 使用useGeneratedKeys和keyProperty
在插入语句的映射文件中,通过设置useGeneratedKeys="true"并指定keyProperty属性来获取自动生成的键值。这样,MyBatis会在执行INSERT操作后自动将新生成的主键值设置到指定对象的属性中。
示例:

2. 返回主键值
如果你不希望直接设置到对象属性中,也可以让插入方法直接返回新生成的主键值。这通常通过在映射文件中使用selectKey标签来实现。
示例:

在此例中,selectKey标签用于查询刚插入的记录的ID(这里假设使用的是MySQL的LAST_INSERT_ID()函数来获取最新插入的自增值)。order="AFTER"表示先执行插入操作,再执行查询主键的操作。keyProperty指定将查询到的主键值设置到参数对象的哪个属性上,但在这个场景中因为我们想要直接返回,所以这个属性设置其实不是必要的,关键在于如何在Java代码中处理这个返回值。
Java代码中处理
在你的DAO或Service层,当你调用这样的插入方法时,如果是第一种情况(useGeneratedKeys),你可以直接从插入后的对象中获取主键值。如果是第二种情况(使用selectKey),则需要根据你的MyBatis配置和方法签名,可能需要调整方法的返回类型来接收这个主键值。
例如,对于第一种情况,你可以这样获取:

而对于第二种情况,假设Mapper接口定义了返回类型为Integer的方法:

这样,你就可以在插入数据后立即获取到由数据库自动生成的主键值。
:::















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









