






比赛链接 http://bdc.saikr.com/c/cql/34541
比赛提供的数据已经被分成了训练集和测试集,这样我们就省去了划分的步骤,首先数据里面包括了序号、轨迹的坐标和时间(x,y,t)、参考点(x_,y_)、判断是机器还是人行为的0和1,然后比赛的数据的储存文件是txt,所以需要我们对数据进行处理,划分出我们需要的特征:
import numpy as np
import pandas as pd
train = pd.read_table("E:\比赛分享\data\dsjtzs_txfz_training_sample.txt", sep=' ', names=['id','numb','goal','label'])#将数据导入并储存在命名为train的字典中,可以看到轨迹的坐标和时间以字符串的形式储存在了‘numb’的列下,参考点的坐标以字符串的形式储存在了名为‘goal’的列下,如图:
然后接下来我们将这两个细分一下:
train['numb'] = train['numb'].apply(lambda x:[list(map(float,point.split(','))) for point in x.split(';')[:-1]])
train['goal'] = train['goal'].apply(lambda x: list(map(float,x.split(",")))) #我们一层一层的分析代码,首先apply函数,是对train['numb']的数据进行lambda匿名函数的运算,然后中括号里面是先将train['numb']通过';'将大字符串分割成一个个类似于"x,y,t"小的字符串,再利用循环将一个个小的字符串通过"."分解出一个个小的数来,这两步相当于将一个'numb'列分解成了一个二维数组,然后我们将相应的x,y,t,x_,y_进行赋值:
df = pd.DataFrame()
df['x'] = train['numb'].apply(lambda x:np.array(x)[:,0])
df['y'] = train['numb'].apply(lambda x:np.array(x)[:,1])
df['t'] = train['numb'].apply(lambda x:np.array(x)[:,2])
df['x_'] = np.array(train['goal'].tolist())[:,0]
df['y_'] = np.array(train['goal'].tolist())[:,1]
#然后我利用matplotlib库将轨迹画出:
import matplotlib.pyplot as plt
for i in range(5):
x = list(df['x'])[i]
y = list(df['y'])[i]
plt.plot(x, y)
plt.show()数据分割好以后接下来就是提取特征了,我提取了大概40个特征,然后就是对特征进行筛选我使用的是SelectBest ,下面是一个简单代码
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
y = train['label']del train['label']new_feature = SelectKBest(chi2, k=2).fit_transform(train,y)new_feature['label'] = y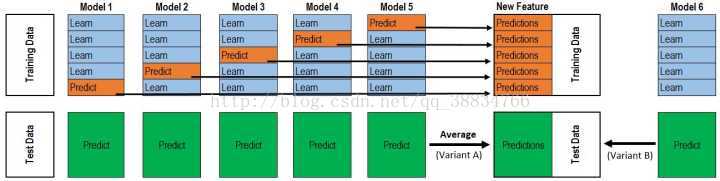
第一步要做的是选择一个模型,其次将训练集分成4比1的两部分,然后用4的那部分进行训练,训练得到的模型用1那部分测试,然后使用测试集进行测试。然后像图片中示意的一样,将1的部分换一下,在进行同样的训练和测试,这样的工作需要完成5次,也就是说保证内训练集的5个小部分每一个小部分都独立被测试过。接下来便需要将那五次训练分出来的五个1的部分组层一个新的训练集,测试集五次测试的平均值在组成一个新的测试集。这样用新的训练集和测试集做为下一个模型训练的训练集和测试集,所以说需要融合n个模型,则需要执行n-1这个步骤。以上只是一些简单的理解和收获,以后会更新出新的知识的。














 2595
2595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









