







 本文介绍一款Python脚本工具,用于解决Word转PDF后出现的空白页问题,通过分割、编辑和合并PDF,实现高效去除多余页面,适合学术论文制作
本文介绍一款Python脚本工具,用于解决Word转PDF后出现的空白页问题,通过分割、编辑和合并PDF,实现高效去除多余页面,适合学术论文制作
到了写论文的日子,总是会有各种奇怪的需求出现,比如说,在你把word导成pdf后,会因为分页符,出现空白页,这时候老师又要说你态度不认真了,那么就有了下面这个工具
#coding=utf-8
import os, shutil
try:
from PyPDF2 import PdfFileReader, PdfFileWriter
except ImportError:
# warning please use pip install pypdf2==1.26.0
# if use pypdf2==1.27.3 , will AttributeError: 'PdfFileWriter' object has no attribute 'stream'
# try to see https://github.com/py-pdf/PyPDF2/issues/670
os.system('pip install pypdf==1.26.0')
from PyPDF2 import PdfFileReader, PdfFileWriter
tempPathName = './temp1045699/'
def check(question):
option = input(">> " + question + " Yes(Y) // No(N): \n>> ")
return option == "Y" or option == "yes" or option == "Yes" or option == "y"
def list_allfile(path, all_files=[]):
if os.path.exists(path):
files=os.listdir(path)
else:
print('this path not exist')
for file in files:
if os.path.isdir(os.path.join(path, file)):
list_allfile(os.path.join(path, file), all_files)
else:
all_files.append(os.path.join(path, file))
return all_files
class PdfEdit:
def __init__(self, filePath) -> None:
self.file_reader = PdfFileReader(filePath)
self.pageNum = self.file_reader.getNumPages()
if not os.path.exists(tempPathName):
os.mkdir(tempPathName)
if not os.path.exists(tempPathName + '/out/'):
os.mkdir(tempPathName + '/out/')
self.pdfName = os.path.basename(filePath)
def getNumPages(self):
return self.pageNum
def split(self):
for page in range(self.pageNum):
pdf_writer=PdfFileWriter()
pdf_writer.addPage(self.file_reader.getPage(page))
output=f'{tempPathName}{page}.pdf'
with open(output,'wb') as output_pdf:
pdf_writer.write(output_pdf)
def merge(self):
file_writer = PdfFileWriter()
for page in range(self.getNumPages()):
fileName = f'{tempPathName}{page}.pdf'
if not os.path.exists(fileName): continue
file_reader = PdfFileReader(fileName)
for page in range(file_reader.getNumPages()):
file_writer.addPage(file_reader.getPage(page))
output = tempPathName + "out/" + self.pdfName
print(output)
with open(output,'wb') as out:
file_writer.write(out)
@staticmethod
def clear():
try:
shutil.rmtree(tempPathName)
os.mkdir(tempPathName)
except Exception as e:
print(e)
def fileObj(filePath):
helper = PdfEdit(filePath)
print(">> 载入成功, 当前文件对象路径:" + filePath + "\n")
while True:
print("### 当前文件对象路径:" + filePath + " ###\n")
option = input("请选择要执行的操作: 分割(S), 合并(M), 清除临时文件(C), 查看临时文件(T), 退出当前对象(Q)\n>>")
option = option.upper()
if option == "S" and check("是否分割"):
helper.split()
if option == "M" and check("是否合并"):
helper.merge()
os.startfile(os.path.abspath(tempPathName + "out"))
if option == "C" and check("是否清除临时文件"):
helper.clear()
if option == "T":
try:
os.startfile(os.path.abspath(tempPathName))
except Exception as e:
files = list_allfile(tempPathName)
print(files)
print(len(files))
if option == "Q":
print(">> 处理完毕\n")
break
def main():
print("欢迎使用PDF裁剪程序\n")
while True:
option = input("请输入要解析的PDF文件路径:\n>> ")
if option == 'exit' or option == 'quit' or option == 'q':
print(">> 退出!\n")
break
elif option == '':
print(">> 输入为空\n")
elif option == 'help' or option == '-h':
print(">> 请输入要解析的PDF文件路径:\n")
else:
if not os.path.exists(option):
print(">> 路径出错!!!, 请输入要解析的PDF文件路径:\n")
continue
fileObj(option)
if __name__ == "__main__":
main()
使用方法
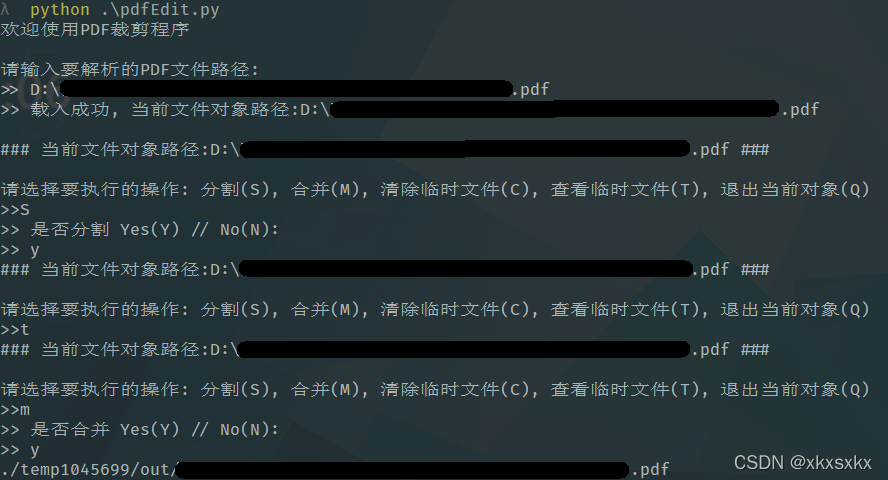
黑黑的就是pdf的文件名了,
大致的流程就是,载入pdf
分割它,然后自己把不要的页删除掉,再合并一下,就没有空白页了
设计思路
-
程序打开后,用户需要输入pdf路径
-
程序根据路径,创建一个可操作对象用于管理pdf
在这里主要用途是分割及合成 -
在使用分割后,会将每一页pdf保存在临时文件夹中
临时文件夹与脚本位于同一目录下 -
可以删除或者添加临时文件夹中的pdf页
-
在合并的时候,会读取临时文件夹中的pdf页,将其进行合并,最终按照原pdf名,保存到临时文件夹下的out目录
-
可以选择是否清空临时文件夹
-
退出当前可操作对象后,可以继续输入下一个路径,生成另一个可操作对象,重复上述步骤


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









