









模型训练与验证
在前面我们已经准备好了数据集并完成了模型的搭建,接下来我们就要进行模型的训练与验证。有些同学可能会觉得模型的训练代码编写并不难,我个人也认为如此,但我们并不是把模型训练一下就完事了,后续我们还需要计算模型的各项性能指标,并通过验证集选取最优模型,这里面也还是有些坑的,因此有必要好好说道说道。
训练函数
我们将一次训练过程封装到一个函数中,先看代码再解释:
model = SVHN_Model1()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), 0.001)
best_loss = 1000.0
use_cuda = False
if use_cuda:
model = model.cuda()
这是一些准备工作,包括定义损失函数与优化方式,以及完成模型向cuda上面的迁移。
def train(train_loader, model, criterion, optimizer):
# 切换模型为训练模式
model.train()
train_loss = []
for i, (input, target) in enumerate(train_loader):
if use_cuda:
input = input.cuda()
target = target.cuda()
c0, c1, c2, c3, c4 = model(input)
loss = criterion(c0, target[:, 0]) + \
criterion(c1, target[:, 1]) + \
criterion(c2, target[:, 2]) + \
criterion(c3, target[:, 3]) + \
criterion(c4, target[:, 4])
# loss /= 6
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print(loss.item())
train_loss.append(loss.item())
return np.mean(train_loss)
首先我们注意到use_gpu这个变量,我们通过这个变量来调节是否在gpu上训练模型。根据官网的描述train-on-gpu,我们需要通过这几步来进行模型在gpu上的训练:
- 首先如果有cuda可用的话我们定义cuda的名称:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
out:
cuda:0
输出这样的结果表明我们有cuda可用。
- 将模型迁移到cuda上:
net.to(device) - 在训练的每一轮将
input与target迁移到cuda上:
inputs, labels = data[0].to(device), data[1].to(device)
在上面的程序中,我们没有定义cuda名称,而是直接采用input.cuda()来完成模型的迁移,这样也是可以的。
随后我们通过定义的损失函数来计算损失,这里我们采用的是交叉熵损失。
验证函数
在训练之后我们需要对模型进行验证,验证集的作用是帮助我们选取训练过程中的最优模型并指导我们需要优化的方向,笔者在初学机器学习时分不清验证集与测试集的区别,因为两者都需要测试模型性能,而在实际中也确实有很多人将验证集与测试集混用。严格来说,在我们的训练过程中是不应当接触测试集的,只能通过验证集去测试我们模型的精度并通过模型在验证集上面的表现进行优化,因为测试集的用途是测试我们模型的泛化能力,如果我们接触了测试集并通过一些方法提升了在测试集上面的准确率,那就相当于我们专门为测试集做了优化,此时测试集就不能很好地反映我们模型的泛化能力。
def validate(val_loader, model, criterion):
# 切换模型为预测模型
model.eval()
val_loss = []
# 不记录模型梯度信息
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
if use_cuda:
input = input.cuda()
target = target.cuda()
c0, c1, c2, c3, c4 = model(input)
loss = criterion(c0, target[:, 0]) + \
criterion(c1, target[:, 1]) + \
criterion(c2, target[:, 2]) + \
criterion(c3, target[:, 3]) + \
criterion(c4, target[:, 4])
# loss /= 6
val_loss.append(loss.item())
return np.mean(val_loss)
这段代码与训练函数大同小异,需要注意两点,一是通过model.eval()将模型切换到预测模式,二是通过with torch.no_grad():来进行加速,因为在验证过程中我们并不需要优化参数因此使用这行语句使得程序不记录梯度信息从而加快速度。
推断函数
def predict(test_loader, model, tta=10):
model.eval()
test_pred_tta = None
# TTA 次数
for _ in range(tta):
test_pred = []
with torch.no_grad():
for i, (input, target) in enumerate(test_loader):
if use_cuda:
input = input.cuda()
c0, c1, c2, c3, c4 = model(input)
output = np.concatenate([
c0.data.numpy(),
c1.data.numpy(),
c2.data.numpy(),
c3.data.numpy(),
c4.data.numpy()], axis=1)
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
这里需要好好说说了,首先我们需要了解这两个函数的用法:
- np.concatenate()
- np.vstack()
大家先看这篇博客了解一下基础知识:numpy中数据合并
下面我们聚焦于得到模型结果之后的代码:
首先我们通过c0.data.numpy等类似的操作来将tensor转为numpy,之后我们通过np.concatenate来对一个批次内得到的不同位置的字符预测结果按照列的方向进行聚合,并最终将所有的结果通过append放入一个列表中。
思考一下,为什么我们需要按照列的方向进行聚合,实际上还是因为我们得到的结果是按行堆叠的,每一行对应一个样本得到的结果,这在前面我们搭建CNN网络模型时就已经确定了,这样我们按照列的方向进行聚合,每一行对应一个样本所有位置的字符预测结果。
随后,通过np.hstack操作将所有样本的预测结果按行聚合,得到了我们的返回值,这将便于我们在后面通过预测结果得到最终预测的字符串。 最终返回的图示如下:
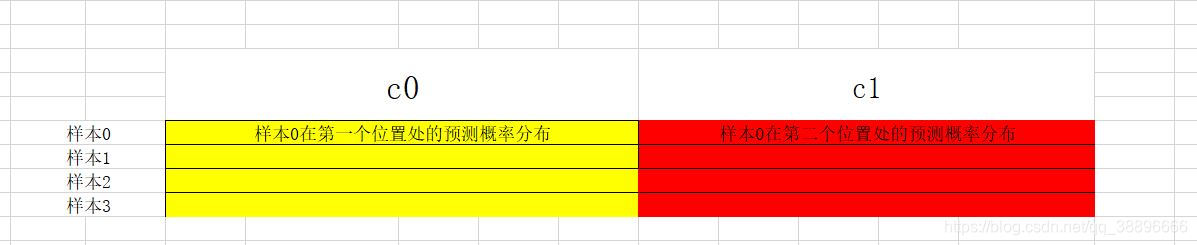
训练
for epoch in range(2):
train_loss = train(train_loader, model, criterion, optimizer, epoch)
val_loss = validate(val_loader, model, criterion)
val_label = [''.join(map(str, x)) for x in val_loader.dataset.img_label]
#这里用的是imglabel,因此是未添加信息的label
val_predict_label = predict(val_loader, model, 1)
#每十一个作为一个字符的概率分布,求最大值对应的索引作为结果
val_predict_label = np.vstack([
val_predict_label[:, :11].argmax(1),
val_predict_label[:, 11:22].argmax(1),
val_predict_label[:, 22:33].argmax(1),
val_predict_label[:, 33:44].argmax(1),
val_predict_label[:, 44:55].argmax(1),
]).T #这里的转置一定要注意,因为图片的label信息是按行堆叠的
val_label_pred = []
for x in val_predict_label:
val_label_pred.append(''.join(map(str, x[x!=10])))
val_char_acc = np.mean(np.array(val_label_pred) == np.array(val_label)) #accuracy,dim should coincident
print('Epoch: {0}, Train loss: {1} \t Val loss: {2}'.format(epoch, train_loss, val_loss))
print(val_char_acc)
# 记录下验证集精度
if val_loss < best_loss:
best_loss = val_loss
torch.save(model.state_dict(), './model.pt')
val_predict_label = np.vstack([
val_predict_label[:, :11].argmax(1),
val_predict_label[:, 11:22].argmax(1),
val_predict_label[:, 22:33].argmax(1),
val_predict_label[:, 33:44].argmax(1),
val_predict_label[:, 44:55].argmax(1),
]).T #这里的转置一定要注意,因为图片的label信息是按行堆叠的
这一段也要拿出来说,通过argmax我们得到最大分值对应的索引也就是我们最终预测的数值,简单画了个图如下:

其中第i列的所有数值组合起来就是第i个样本的预测数值。
由于在label中所有样本的字符串信息按行堆叠,所以我们最后进行了转置使得每一行对应一个样本的最终预测结果。
最后插几句,图都是在excel弄的,实在想不到怎么样去表示了,这一块确实有点绕,我自己可能有的地方也没有表达到位(我真的已经尽我的最大能力把我自己的理解去表达出来了。。。),还是要自己多思考思考 。

















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









