







语义分割系列(一)
何为语义分割
我们在基于深度学习的计算机视觉领域所进行的任务大致可以分为三类:图像分类、目标检测以及图像分割。
图像分割还能进一步分为语义分割和实例分割,我们这里只讨论语义分割。
- 图像分类
The origin could be located at classification, which consists
of making a prediction for a whole input, i.e., predicting
which is the object in an image or even providing a ranked
list if there are many of them.
大部分人较为熟悉的是图像分类任务:对一幅给定的图像,我们希望模型能告诉我们图像中的物体是什么,我们所熟知的AlexNet、VGG16等都是图像分类模型,图像分类属于高级任务并且得到的结果较为粗糙,我们只能知道图像中的物体是什么,除此以外也再得不到任何其它信息。


- 目标检测
Localization or detection is the next step towards fine-grained inference, providing not only the classes but also additional information regarding the spatial location of those classes, e.g., centroids or bounding boxes.
也有很多人比较熟悉目标检测任务:对图像中的多个物体进行定位和分类。首先我们在物体的外部画出边界框,随后判断边界框中的物体属于哪一类。 目标检测相当于中级任务,它可以为我们提供更多的细节信息,但我们只是得到了物体的边界框而不是其精确的形状,因此目标检测仍然较为粗糙。

-图像语义分割
Providing that, it is obvious that semantic segmentation is the natural step to achieve fine-grained inference,its goal: make dense predictions inferring labels for every pixel; this way, each pixel is labeled with the class of its enclosing object or region.
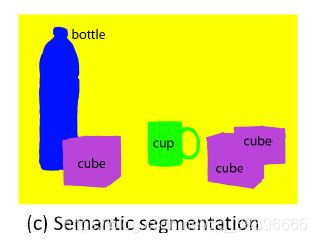
图像语义分割是是三者中包含信息最多的任务,它将图像的高级语义标签分配给每一个像素,也就是给每一个像素作分类,高级语义标签指图像中各种各样的物体类别(如:人、动物、汽车等)以及背景类别(如:天空)。语义分割任务对于分类精度以及定位精度都提出了很高的要求:一方面,我们需要将物体的轮廓边界准确定位,一方面我们需要对轮廓内的区域进行精准分类,这样才能很好的将特定物体从背景中分割出来。 因此,如何保持定位精度与分类精度的平衡称为语义分割中的重要问题,一般来说,要想提高分类精度,我们需要提高深层网络的感受野,这样才能融合更多的信息,但是扩大深层网络的感受野会导致图像的细节大量丢失不利于我们对边界的定位,因此在语义分割的方向的一个改进目标就是在不丢失图像局部细节的情况下融合更多的全局信息。

参考资料:
semantic segmentation with deep learning
A Review on Deep Learning Techniques Applied to Semantic Segmentation

















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









