






Self Attention模块
模型结构图:
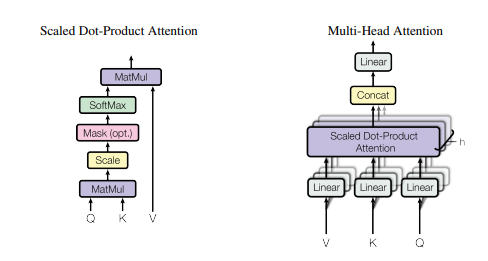
2.论文主要内容
"Attention Is All You Need" 是一篇由Google Brain团队发表于2017年的论文,提出了一种新的深度学习模型——Transformer,它不依赖于传统的循环神经网络(RNN)或卷积神经网络(CNN),而是通过自注意力机制来解决序列建模任务中存在的长程依赖和平移不变性问题,是一篇具有重要意义的论文。Transformer模型被广泛应用于自然语言处理(NLP)领域,包括机器翻译、文本生成、问答系统等任务,极大地提高了这些任务的效率和准确性。
论文的主要贡献包括:
提出了Transformer模型,使用自注意力机制来学习序列间的关系,避免了RNN和CNN中存在的长程依赖和平移不变性问题。
引入了一种新的位置编码方法,使得Transformer能够处理序列信息。
在机器翻译任务中,使用Transformer模型取得了比现有最先进方法更好的性能。
将Transformer模型与卷积神经网络(CNN)和循环神经网络(RNN)进行了比较,结果表明Transformer模型在NLP任务上表现更好。
自注意力机制解释:
Transformer模型中的自注意力机制(self-attention)是一种计算序列中各元素之间关联度的方法,用于学习序列中各元素之间的依赖关系,以此来解决序列建模任务中的长程依赖和平移不变性问题。在自注意力机制中,每个元素都可以作为查询(query)、键(key)和值(value)进行表示,并计算该元素与其他元素的相似度,得到注意力分数(attention score),再将注意力分数加权求和得到该元素的表示。具体地,自注意力机制的计算过程如下:
对于给定的输入序列,首先将每个元素通过不同的线性映射(即权重矩阵)分别表示为查询、键和值的向量。
对于每个查询向量,计算其与所有键向量之间的相似度,可以使用点积、加性(MLP)或拼接等方式进行计算。得到的相似度通常会进行缩放(除以查询向量维度的平方根)和softmax归一化,以得到每个键向量对查询向量的注意力分数。
将每个注意力分数与其对应的值向量相乘,得到加权的值向量,再将所有加权的值向量加和,得到该查询向量的表示。
重复以上过程,对所有查询向量进行计算,得到整个序列的表示矩阵。
需要注意的是,在自注意力机制中,每个元素都可以作为查询、键和值进行表示,因此可以学习到序列中各元素之间的交互关系,而且计算过程可以并行化,从而避免了传统循环神经网络(RNN)中存在的时间依赖问题,使得Transformer模型具有更高的并行性和计算效率。
3.代码案例:
#导入需要用到的库和模块
import numpy as np
import torch
from torch import nn
from torch.nn import init
#定义多尺度点乘注意力类,继承了 nn.Module 类。
class ScaledDotProductAttention(nn.Module):
'''
Scaled dot-product attention
d_model 是模型的输出维度,
d_k 是查询和键的维度,
d_v 是值的维度,
h 是头的数量
'''
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(ScaledDotProductAttention, self).__init__()
self.fc_q = nn.Linear(d_model, h * d_k) #定义线性层:fc_q
self.fc_k = nn.Linear(d_model, h * d_k) #定义线性层:fc_k
self.fc_v = nn.Linear(d_model, h * d_v) #定义线性层:fc_v
self.fc_o = nn.Linear(h * d_v, d_model) #定义线性层:fc_o
self.dropout=nn.Dropout(dropout)
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self): #定义初始化权重的函数
for m in self.modules(): #遍历网络的所有模块
if isinstance(m, nn.Conv2d): #对于卷积层使用kaiming方法进行初始化。
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d): #对于批量归一化层使用constant方法进行初始化
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear): #线性层使用正态分布进行初始化,偏置使用constant进行初始化
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
'''
Computes
:param queries: Queries (b_s, nq, d_model)
:param keys: Keys (b_s, nk, d_model)
:param values: Values (b_s, nk, d_model)
:param attention_mask: Mask over attention values (b_s, h, nq, nk). True indicates masking.
:param attention_weights: Multiplicative weights for attention values (b_s, h, nq, nk).
:return:
'''
#获取输入 queries 和 keys 的形状信息,
#分别将其第一、二维赋值给变量 b_s 和 nq,keys 的第二维赋值给 nk
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
#线性变换层 fc_q、fc_k 和 fc_v 分别将 queries、keys 和 values 进行线性变换
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
#矩阵乘法计算 q 和 k 之间的乘积,并除以 sqrt{d_k}进行缩放,得到 att 注意力分数张量,形状为 (b_s, h, nq, nk)
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1) #对att 沿着最后一个维度进行 softmax 归一化,
att=self.dropout(att) #使用 dropout 层对结果进行正则化,得到 att 张量
#经过注意力计算后得到out的结果,形状为 (b_s, nq, h * self.d_v)。
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)














 1277
1277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











