






本文使用到的 Jupyter Notebook 可在GitHub仓库002文件夹找到,别忘了给仓库点个小心心~~~
https://github.com/LFF8888/FF-Studio-Resources
在机器学习项目的开发过程中,实验跟踪和结果可视化是至关重要的环节。无论是调整超参数、优化模型架构,还是监控训练过程中的性能变化,清晰的记录和直观的可视化都能显著提升开发效率。然而,许多开发者在实际操作中往往忽视了这一点,导致实验结果难以复现,或者在项目协作中出现混乱。今天,我们将介绍如何利用 Weights & Biases 这一强大的工具,与 PyTorch 深度集成,轻松实现实验跟踪、数据版本控制和团队协作。通过本文,你将学会如何在自己的项目中快速添加这一功能,让每一次实验都清晰可溯,每一次优化都有据可依。
🔥 = W&B ➕ PyTorch
使用 Weights & Biases 进行机器学习实验跟踪、数据集版本控制和项目协作。

本笔记本涵盖的内容:
我们将向你展示如何将 Weights & Biases 与 PyTorch 代码集成,以便为你的管道添加实验跟踪功能。
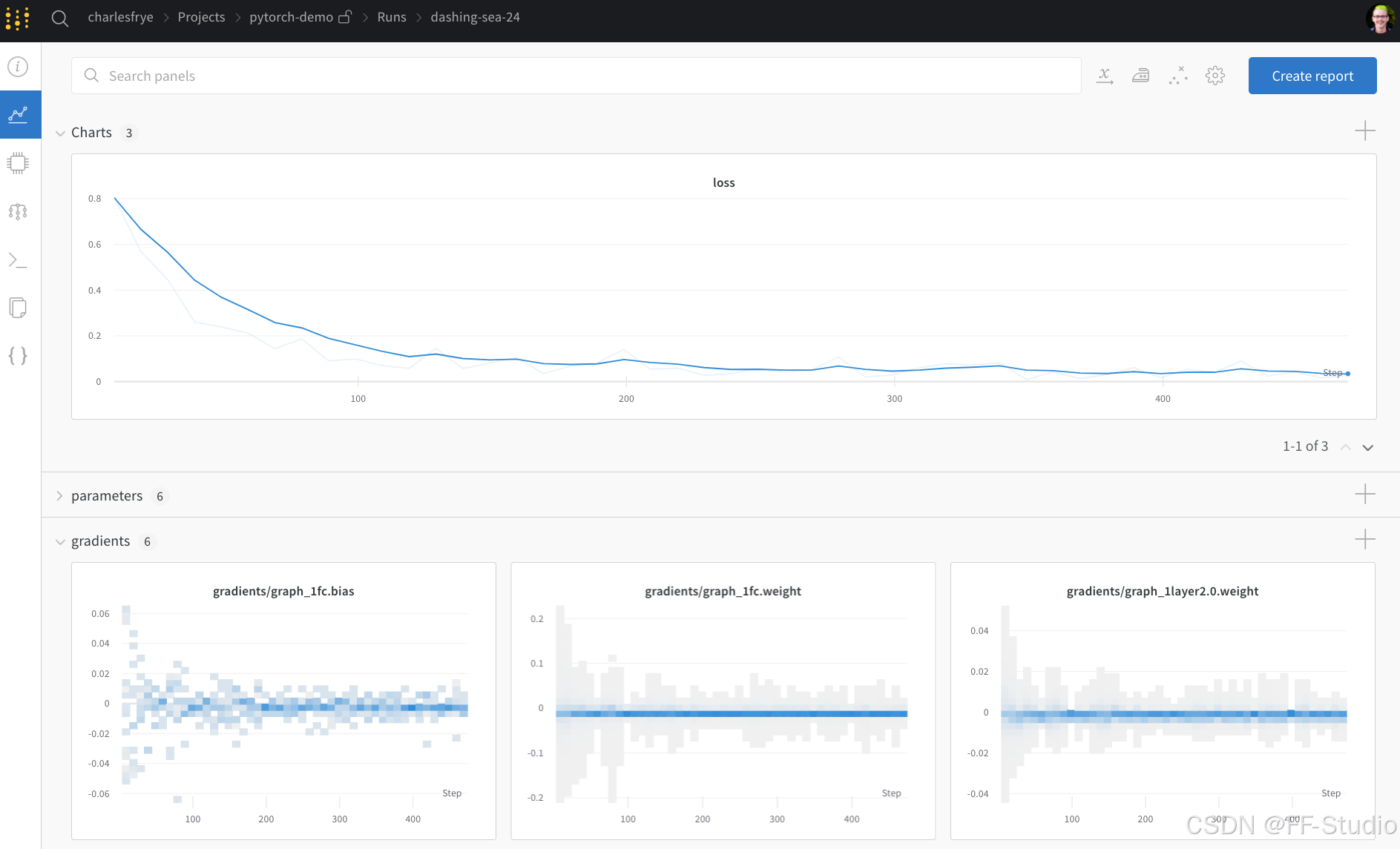
最终生成的交互式 W&B 仪表盘将如下所示:
伪代码中,我们将执行以下操作:
# 导入库
import wandb
# 启动一个新实验
wandb.init(project="new-sota-model")
# 使用 config 捕获超参数字典
wandb.config = {"learning_rate": 0.001, "epochs": 100, "batch_size": 128}
# 设置模型和数据
model, dataloader = get_model(), get_data()
# 可选:跟踪梯度
wandb.watch(model)
for batch in dataloader:
metrics = model.training_step()
# 在训练循环中记录指标以可视化模型性能
wandb.log(metrics)
# 可选:在最后保存模型
model.to_onnx()
wandb.save("model.onnx")
跟随 视频教程 一起学习!
注意:以 Step 开头的部分是你在现有管道中集成 W&B 所需的全部内容。其余部分只是加载数据并定义模型。
🚀 安装、导入和登录
0️⃣ 步骤 0:安装 W&B
首先,我们需要获取库。
wandb 可以通过 pip 轻松安装。
!pip install wandb onnx -Uq
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from tqdm.auto import tqdm
# 确保确定性行为
torch.backends.cudnn.deterministic = True
random.seed(hash("setting random seeds") % 2**32 - 1)
np.random.seed(hash("improves reproducibility") % 2**32 - 1)
torch.manual_seed(hash("by removing stochasticity") % 2**32 - 1)
torch.cuda.manual_seed_all(hash("so runs are repeatable") % 2**32 - 1)
# 设备配置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 从 MNIST 镜像列表中移除慢速镜像
torchvision.datasets.MNIST.mirrors = [mirror for mirror in torchvision.datasets.MNIST.mirrors
if not mirror.startswith("http://yann.lecun.com")]
1️⃣ 步骤 1:导入 W&B 并登录
为了将数据记录到我们的 Web 服务,你需要登录。
如果你是第一次使用 W&B,你需要在出现的链接中注册一个免费账户。
import wandb
wandb.login()
👩🔬 定义实验和管道
2️⃣ 步骤 2:使用 wandb.init 跟踪元数据和超参数
在编程中,我们首先定义实验:超参数是什么?与此运行相关的元数据是什么?
通常,我们会将这些信息存储在 config 字典(或类似对象)中,然后根据需要访问它。
在这个例子中,我们只让少数超参数变化,其余部分手动编码。但你的模型的任何部分都可以成为 config 的一部分!
我们还包括一些元数据:我们使用的是 MNIST 数据集和卷积架构。如果我们以后在同一项目中使用全连接架构处理 CIFAR,这将帮助我们区分运行。
config = dict(
epochs=5,
classes=10,
kernels=[16, 32],
batch_size=128,
learning_rate=0.005,
dataset="MNIST",
architecture="CNN")
现在,让我们定义整个管道,这对于模型训练来说非常典型:
- 首先,我们
make一个模型,以及相关的数据和优化器,然后 - 我们
train模型,最后 test它,看看训练效果如何。
我们将在下面实现这些函数。
def model_pipeline(hyperparameters):
# 告诉 wandb 开始
with wandb.init(project="pytorch-demo", config=hyperparameters):
# 通过 wandb.config 访问所有超参数,确保日志与执行一致!
config = wandb.config
# 创建模型、数据和优化问题
model, train_loader, test_loader, criterion, optimizer = make(config)
print(model)
# 使用它们训练模型
train(model, train_loader, criterion, optimizer, config)
# 测试其最终性能
test(model, test_loader)
return model
与标准管道的唯一区别是,所有操作都在 wandb.init 的上下文中进行。调用此函数会在你的代码和我们的服务器之间建立通信线路。
将 config 字典传递给 wandb.init 会立即将所有信息记录到我们这里,因此你始终知道为实验设置了哪些超参数值。
为了确保你选择并记录的值始终是模型中使用的值,我们建议使用 wandb.config 的副本。查看下面的 make 定义以了解一些示例。
注意:我们确保在不同的进程中运行代码,因此我们这边的任何问题(例如,巨型海怪攻击我们的数据中心)都不会导致你的代码崩溃。一旦问题解决(例如,海怪返回深海),你可以使用
wandb sync记录数据。
def make(config):
# 创建数据
train, test = get_data(train=True), get_data(train=False)
train_loader = make_loader(train, batch_size=config.batch_size)
test_loader = make_loader(test, batch_size=config.batch_size)
# 创建模型
model = ConvNet(config.kernels, config.classes).to(device)
# 创建损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
model.parameters(), lr=config.learning_rate)
return model, train_loader, test_loader, criterion, optimizer
📡 定义数据加载和模型
现在,我们需要指定如何加载数据以及模型的外观。
这部分非常重要,但它与没有 wandb 时没有什么不同,因此我们不会过多讨论。
def get_data(slice=5, train=True):
full_dataset = torchvision.datasets.MNIST(root=".",
train=train,
transform=transforms.ToTensor(),
download=True)
# 等同于使用 [::slice] 切片
sub_dataset = torch.utils.data.Subset(
full_dataset, indices=range(0, len(full_dataset), slice))
return sub_dataset
def make_loader(dataset, batch_size):
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True, num_workers=2)
return loader
定义模型通常是乐趣所在!
但使用 wandb 时没有任何变化,因此我们将坚持使用标准的 ConvNet 架构。
不要害怕尝试一些实验——你所有的结果都会记录在 wandb.ai 上!
# 传统卷积神经网络
class ConvNet(nn.Module):
def __init__(self, kernels, classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, kernels[0], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, kernels[1], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * kernels[-1], classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
👟 定义训练逻辑
继续我们的 model_pipeline,现在是时候指定如何 train 了。
这里有两个 wandb 函数发挥作用:watch 和 log。
3️⃣ 步骤 3. 使用 wandb.watch 跟踪梯度,使用 wandb.log 跟踪其他内容
wandb.watch 会记录模型的梯度和参数,每 log_freq 步训练一次。
你只需要在开始训练之前调用它。
其余的训练代码保持不变:我们遍历 epoch 和 batch,运行前向和后向传播,并应用我们的 optimizer。
def train(model, loader, criterion, optimizer, config):
# 告诉 wandb 监视模型的梯度、权重等!
wandb.watch(model, criterion, log="all", log_freq=10)
# 运行训练并使用 wandb 跟踪
total_batches = len(loader) * config.epochs
example_ct = 0 # 已看到的样本数
batch_ct = 0
for epoch in tqdm(range(config.epochs)):
for _, (images, labels) in enumerate(loader):
loss = train_batch(images, labels, model, optimizer, criterion)
example_ct += len(images)
batch_ct += 1
# 每 25 个 batch 报告一次指标
if ((batch_ct + 1) % 25) == 0:
train_log(loss, example_ct, epoch)
def train_batch(images, labels, model, optimizer, criterion):
images, labels = images.to(device), labels.to(device)
# 前向传播 ➡
outputs = model(images)
loss = criterion(outputs, labels)
# 后向传播 ⬅
optimizer.zero_grad()
loss.backward()
# 使用优化器更新
optimizer.step()
return loss
唯一的区别在于日志代码:以前你可能通过打印到终端来报告指标,现在你将相同的信息传递给 wandb.log。
wandb.log 期望一个以字符串为键的字典。这些字符串标识被记录的对象,它们构成了值。你还可以选择记录你处于训练的哪个 step。
注意:我喜欢使用模型看到的样本数,因为这使得跨 batch 大小的比较更容易,但你可以使用原始步骤或 batch 计数。对于较长的训练运行,按
epoch记录也是有意义的。
def train_log(loss, example_ct, epoch):
# 魔法发生的地方
wandb.log({"epoch": epoch, "loss": loss}, step=example_ct)
print(f"Loss after {str(example_ct).zfill(5)} examples: {loss:.3f}")
🧪 定义测试逻辑
一旦模型完成训练,我们想要测试它:
可能是针对生产中的一些新数据运行它,或者将其应用于一些手工挑选的“困难样本”。
4️⃣ 可选步骤 4:调用 wandb.save
这也是将模型的架构和最终参数保存到磁盘的好时机。
为了最大兼容性,我们将以 Open Neural Network eXchange (ONNX) 格式 export 我们的模型。
将该文件名传递给 wandb.save 可确保模型参数保存到 W&B 的服务器:不再丢失哪个 .h5 或 .pb 对应哪个训练运行!
有关存储、版本控制和分发模型的更高级 wandb 功能,请查看我们的 Artifacts 工具。
def test(model, test_loader):
model.eval()
# 在测试样本上运行模型
with torch.no_grad():
correct, total = 0, 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy of the model on the {total} " +
f"test images: {correct / total:%}")
wandb.log({"test_accuracy": correct / total})
# 以可交换的 ONNX 格式保存模型
torch.onnx.export(model, images, "model.onnx")
wandb.save("model.onnx")
🏃♀️ 运行训练并在 wandb.ai 上实时查看你的指标!
现在我们已经定义了整个管道并插入了那几行 W&B 代码,我们准备运行完全跟踪的实验。
我们会向你报告一些链接:
我们的文档、项目页面(组织项目中的所有运行)和运行页面(存储此运行的结果)。
导航到运行页面并查看这些选项卡:
- 图表,其中记录了模型梯度、参数值和训练期间的损失
- 系统,其中包含各种系统指标,包括磁盘 I/O 利用率、CPU 和 GPU 指标(观察温度飙升 🔥)等
- 日志,其中包含训练期间推送到标准输出的任何内容的副本
- 文件,在训练完成后,你可以点击
model.onnx使用 Netron 模型查看器 查看我们的网络。
一旦运行完成(即退出 with wandb.init 块),我们还会在单元格输出中打印结果的摘要。
# 使用管道构建、训练和分析模型
model = model_pipeline(config)
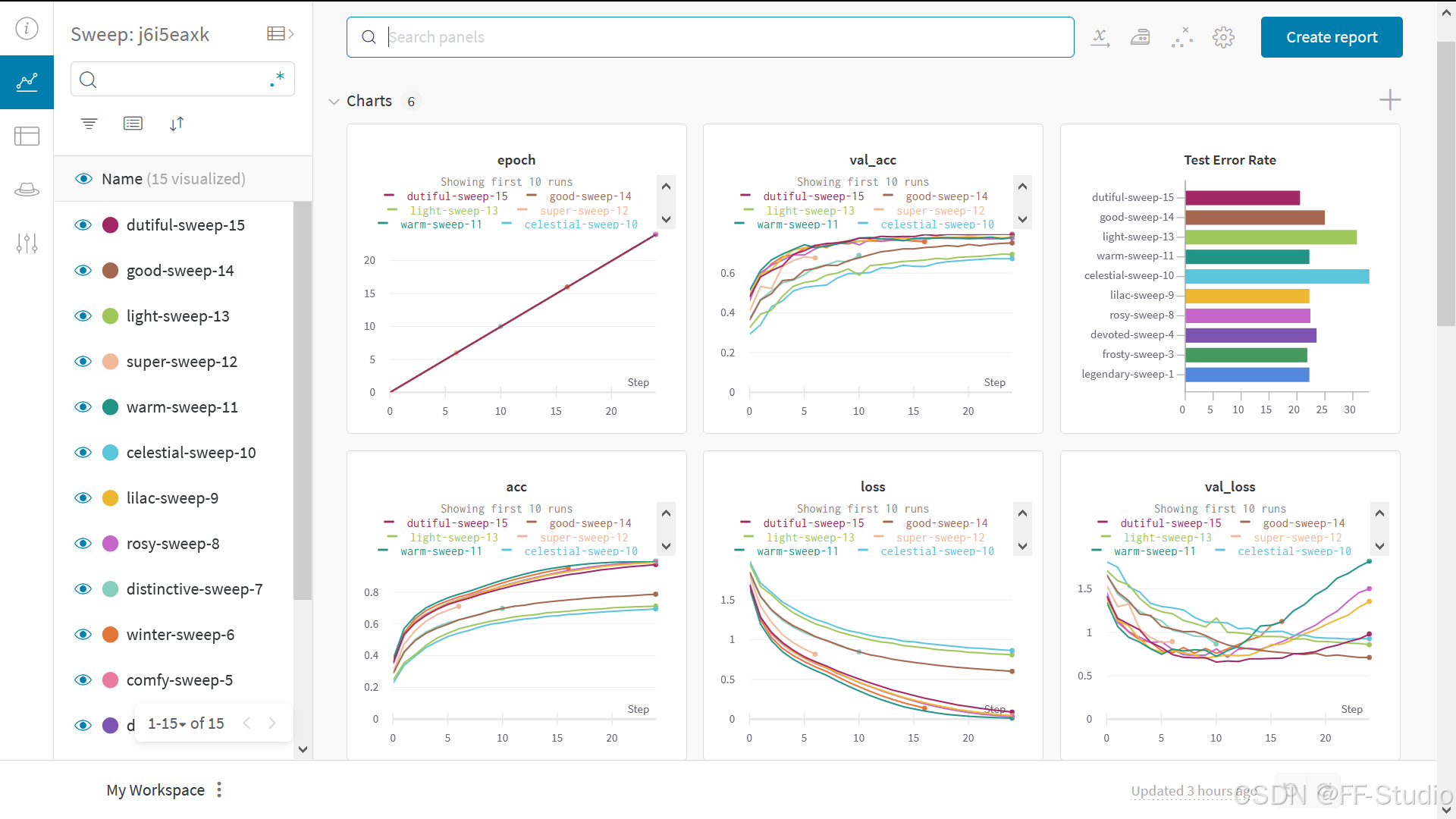
🧹 使用 Sweeps 测试超参数
在这个例子中,我们只查看了一组超参数。
但大多数 ML 工作流程的一个重要部分是迭代多个超参数。
你可以使用 Weights & Biases Sweeps 自动化超参数测试,并探索可能的模型和优化策略的空间。
查看使用 W&B Sweeps 在 PyTorch 中进行超参数优化 → → →
使用 Weights & Biases 运行超参数扫描非常简单。只需 3 个简单步骤:
- 定义扫描:我们通过创建字典或 YAML 文件 来指定要搜索的参数、搜索策略、优化指标等。
- 初始化扫描:
sweep_id = wandb.sweep(sweep_config) - 运行扫描代理:
wandb.agent(sweep_id, function=train)
就这样!这就是运行超参数扫描的全部内容!
🖼️ 示例画廊
查看使用 W&B 跟踪和可视化的项目示例,请访问我们的 画廊 →



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









