







今天,我们不聊玄乎的“人工智能大爆发”,而是来挖一挖支撑起AI大厦的那些“钢筋水泥”——数学。特别是,我们要聚焦于线性代数。
“等等,线性代数?是不是大学里那门让人头秃的课?” 别怕!我知道,一提到“矩阵”、“特征值”,很多小伙伴可能就想溜了。但相信我,线性代数远比你想象的要直观和有用,尤其是在AI的世界里。它就像是AI的“通用语”,是理解数据、构建模型、优化算法的基础。我们将一起探索:
- 向量 (Vectors):AI如何“看见”世界?数据点的表示。
- 矩阵运算 (Matrix Operations):AI如何“处理”信息?批量数据与模型变换。
- 范数 (Norms):AI如何“衡量”远近?相似度与误差。
- 特征值/特征向量 (Eigenvalues/Eigenvectors):AI如何“抓住”重点?数据降维的核心。
- 奇异值分解 (SVD - Singular Value Decomposition):AI如何“化繁为简”?强大的矩阵分解术。
向量:AI眼中的世界基元
想象一下,你要向计算机描述一张图片、一段声音或者一个用户的喜好。计算机不懂“可爱的小猫”、“欢快的音乐”或“喜欢科幻电影”。它只懂数字。那么,如何把这些丰富多彩的现实信息转化成计算机能理解的数字呢?答案就是——向量!
什么是向量?
在数学上,一个向量(Vector)就是一个有序的数字列表。你可以把它想象成一个箭头,有方向,有长度。但在AI领域,我们更多地把它看作是空间中的一个点,或者更直观地,一个对象的数字化描述。
例如,我们要描述一张2x2像素的灰度图片。每个像素有一个灰度值(比如0代表黑色,255代表白色)。我们可以把这4个像素的灰度值按顺序排列起来,形成一个向量:
v
=
[
p
i
x
e
l
11
,
p
i
x
e
l
12
,
p
i
x
e
l
21
,
p
i
x
e
l
22
]
v = [pixel_{11}, pixel_{12}, pixel_{21}, pixel_{22}]
v=[pixel11,pixel12,pixel21,pixel22]
假设左上角像素灰度是100,右上角是50,左下角是200,右下角是150,那么这张图片就可以表示为向量:
v
=
[
100
,
50
,
200
,
150
]
v = [100, 50, 200, 150]
v=[100,50,200,150]
这个向量有4个元素,我们就说它是一个4维向量。
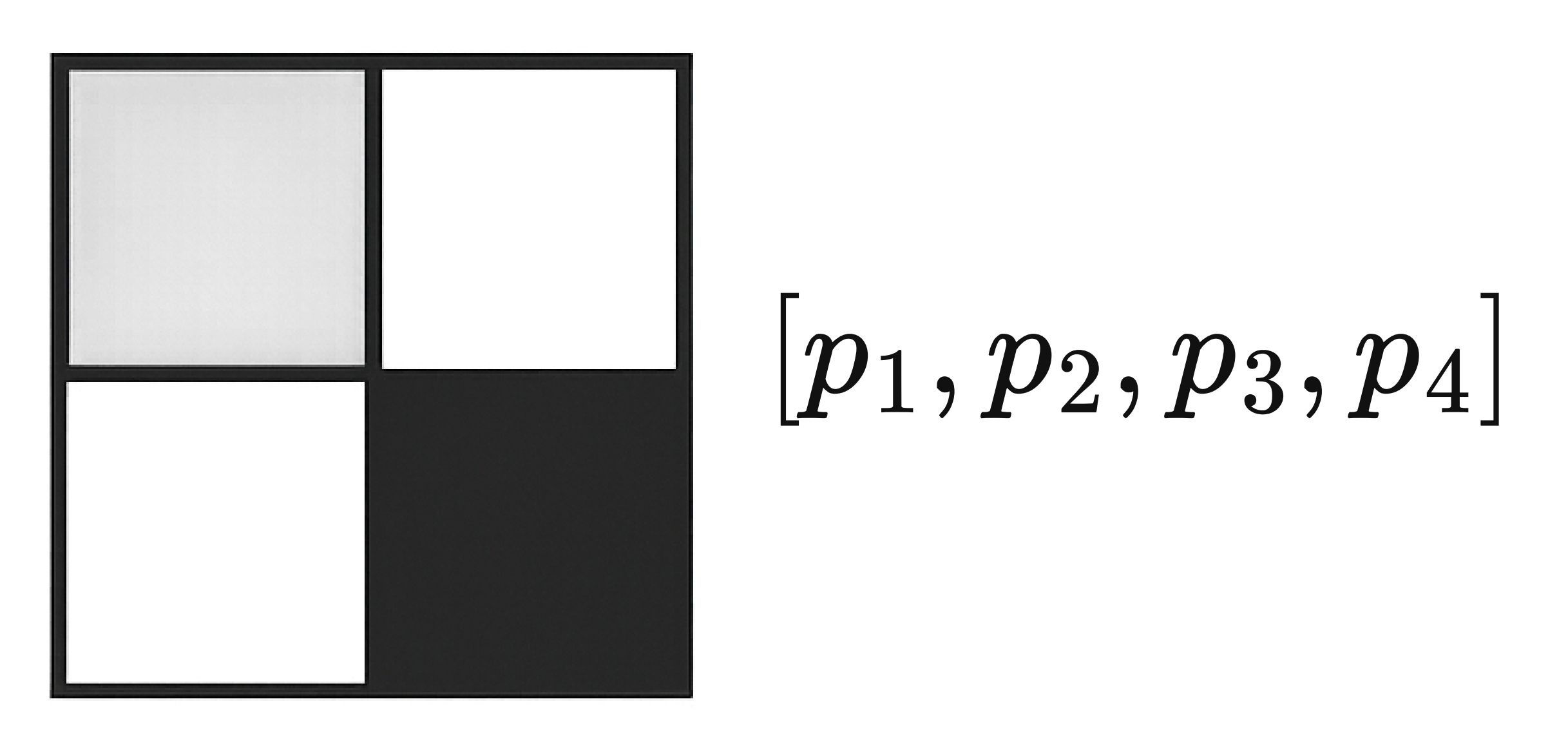
同样地:
- 描述一个用户:可以用向量表示用户的特征,比如
[年龄, 性别(0/1), 浏览商品A时长, 点击广告B次数]->[25, 1, 120.5, 3]。这是一个4维向量。 - 描述一个词语:在自然语言处理(NLP)中,我们用“词向量”(Word Embedding)来表示一个词。比如,“国王”可能被表示为
[0.5, -0.2, 1.8, ... , 0.9]这样一个几百甚至上千维的向量。向量中的每个数字捕捉了该词语的某种语义特征(虽然具体是啥特征通常难以解释)。
关键点:向量提供了一种将现实世界对象(图片、用户、词语等)结构化、数字化的方法,让计算机可以进行处理和分析。向量的“维度”就是描述一个对象所使用的数字(特征)的数量。
向量的基本运算
向量之间可以进行一些基本运算,这些运算在AI中非常有用。
-
向量加法 (Vector Addition):对应元素相加。
假设有两个用户向量,代表他们在两种商品上的偏好度(越高越喜欢):
用户A: a = [ 5 , 2 ] a = [5, 2] a=[5,2] (喜欢商品1,不太喜欢商品2)
用户B: b = [ 1 , 4 ] b = [1, 4] b=[1,4] (不太喜欢商品1,喜欢商品2)
它们的和 c = a + b = [ 5 + 1 , 2 + 4 ] = [ 6 , 6 ] c = a + b = [5+1, 2+4] = [6, 6] c=a+b=[5+1,2+4]=[6,6]。这个和向量可能代表了这两个用户合起来的“群体偏好”。或者在图像处理中,向量加法可以用来混合图片效果。 -
标量乘法 (Scalar Multiplication):一个数字(标量)乘以向量的每个元素。
假设用户A的偏好度向量是 a = [ 5 , 2 ] a = [5, 2] a=[5,2]。如果我们想将他的偏好度整体放大2倍(比如在某个推荐场景下增加权重),就可以用标量2乘以向量a:
2 × a = 2 × [ 5 , 2 ] = [ 2 × 5 , 2 × 2 ] = [ 10 , 4 ] 2 \times a = 2 \times [5, 2] = [2 \times 5, 2 \times 2] = [10, 4] 2×a=2×[5,2]=[2×5,2×2]=[10,4]
在图像处理中,标量乘法可以用来调整图片的亮度(所有像素值乘以一个大于1或小于1的数)。
这些基本运算构成了更复杂操作的基础。比如,在机器学习中,模型参数的更新(梯度下降)就涉及到向量的加法和标量乘法。
小结:向量是AI表示数据的基本单元,它将对象特征化为数字列表。向量的加法和标量乘法是处理这些数字表示的基础操作。
矩阵:数据的集合与变换的舞台
如果说向量是AI世界里的“单词”,那么矩阵(Matrix)就是“句子”或“段落”。矩阵是组织和处理大量数据的强大工具。
什么是矩阵?
一个矩阵就是一个二维的数字阵列,可以看作是一组向量(行向量或列向量)的集合。它有行(row)和列(column)。一个 m × n m \times n m×n 的矩阵有 m m m 行和 n n n 列。
A = ( a 11 a 12 … a 1 n a 21 a 22 … a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 … a m n ) A = \begin{pmatrix} a_{11} & a_{12} & \dots & a_{1n} \\ a_{21} & a_{22} & \dots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \dots & a_{mn} \end{pmatrix} A= a11a21⋮am1a12a22⋮am2……⋱…a1na2n⋮amn
在AI中,矩阵无处不在:
-
数据集 (Dataset):最常见的应用!通常,一个数据集会表示成一个矩阵,其中每一行代表一个样本(一个数据点,比如一个用户、一张图片),每一列代表一个特征。
例如,一个包含3个用户,每个用户有4个特征的数据集,可以表示为一个 3 × 4 3 \times 4 3×4 的矩阵:
Data = ( 年龄 1 性别 1 时长 1 点击 1 年龄 2 性别 2 时长 2 点击 2 年龄 3 性别 3 时长 3 点击 3 ) = ( 25 1 120.5 3 40 0 80.0 1 18 1 250.2 5 ) \text{Data} = \begin{pmatrix} \text{年龄}_1 & \text{性别}_1 & \text{时长}_1 & \text{点击}_1 \\ \text{年龄}_2 & \text{性别}_2 & \text{时长}_2 & \text{点击}_2 \\ \text{年龄}_3 & \text{性别}_3 & \text{时长}_3 & \text{点击}_3 \end{pmatrix} = \begin{pmatrix} 25 & 1 & 120.5 & 3 \\ 40 & 0 & 80.0 & 1 \\ 18 & 1 & 250.2 & 5 \end{pmatrix} Data= 年龄1年龄2年龄3性别1性别2性别3时长1时长2时长3点击1点击2点击3 = 254018101120.580.0250.2315
这里的每一行[25, 1, 120.5, 3]就是我们之前说的用户向量。整个矩阵就是这些用户向量的集合。 -
灰度图像 (Grayscale Image):一张 H × W H \times W H×W 像素的灰度图像可以直接看作是一个 H × W H \times W H×W 的矩阵,矩阵中的每个元素 A i j A_{ij} Aij 就是对应位置 ( i , j ) (i, j) (i,j) 像素的灰度值。
-
模型参数 (Model Parameters):在深度学习中,神经网络的权重(weights)通常组织成矩阵。一个网络层对输入数据的变换,很大程度上就是通过与权重矩阵进行运算来实现的。
矩阵运算:处理数据与实现变换
矩阵运算是线性代数的核心,也是AI算法运转的关键。
-
矩阵加法 (Matrix Addition):与向量加法类似,两个相同尺寸的矩阵相加,就是对应位置的元素相加。在AI中不那么常用,但在某些图像处理(如混合图片)或特定模型操作中可能用到。
-
标量乘法 (Scalar Multiplication):一个数字乘以矩阵的每个元素。用途类似向量的标量乘法,如调整整个数据集的数值范围,或在优化算法中缩放梯度。
-
矩阵乘法 (Matrix Multiplication):这是最重要的矩阵运算之一!两个矩阵 A A A ( m × n m \times n m×n) 和 B B B ( n × p n \times p n×p) 可以相乘得到一个新矩阵 C C C ( m × p m \times p m×p)。注意:第一个矩阵的列数必须等于第二个矩阵的行数。
C = A × B C = A \times B C=A×B
计算 C C C 中第 i i i 行第 j j j 列的元素 C i j C_{ij} Cij 的方法是:取 A A A 的第 i i i 行(一个行向量)和 B B B 的第 j j j 列(一个列向量),将它们的对应元素相乘,然后求和。
C i j = ∑ k = 1 n A i k B k j C_{ij} = \sum_{k=1}^{n} A_{ik} B_{kj} Cij=∑k=1nAikBkj为什么矩阵乘法在AI中如此重要?
-
应用线性变换 (Applying Linear Transformations):一个 m × n m \times n m×n 的矩阵 A A A 可以看作是一个函数或变换,它能将一个 n n n 维向量 x x x 转换成一个 m m m 维向量 y y y。这个变换就是通过矩阵乘法实现的:
y = A x y = A x y=Ax
在神经网络中,每一层对输入数据的处理,核心就是一次或多次这样的矩阵乘法(加上偏置向量和激活函数)。矩阵 A A A 就是这一层的权重矩阵,它定义了如何将输入特征组合、变换成新的特征。 -
处理数据批次 (Processing Data Batches):假设我们有一个 N × D N \times D N×D 的数据矩阵 X X X( N N N 个样本,每个样本 D D D 个特征),和一个 D × K D \times K D×K 的权重矩阵 W W W(将 D D D 维输入映射到 K K K 维输出)。它们的乘积 Y = X W Y = X W Y=XW 将得到一个 N × K N \times K N×K 的矩阵 Y Y Y。
( … x 1 … … x 2 … ⋮ ⋮ ⋮ … x N … ) ⏟ N × D × ( … w 1 … … w 2 … ⋮ ⋮ ⋮ … w D … ) ⏟ D × K = ( … y 1 … … y 2 … ⋮ ⋮ ⋮ … y N … ) ⏟ N × K \underbrace{ \begin{pmatrix} \dots & x_{1} & \dots \\ \dots & x_{2} & \dots \\ \vdots & \vdots & \vdots \\ \dots & x_{N} & \dots \end{pmatrix} }_{N \times D} \times \underbrace{ \begin{pmatrix} \dots & w_1 & \dots \\ \dots & w_2 & \dots \\ \vdots & \vdots & \vdots \\ \dots & w_D & \dots \end{pmatrix} }_{D \times K} = \underbrace{ \begin{pmatrix} \dots & y_{1} & \dots \\ \dots & y_{2} & \dots \\ \vdots & \vdots & \vdots \\ \dots & y_{N} & \dots \end{pmatrix} }_{N \times K} N×D ……⋮…x1x2⋮xN……⋮… ×D×K ……⋮…w1w2⋮wD……⋮… =N×K ……⋮…y1y2⋮yN……⋮…
这一个矩阵乘法操作,就同时对 N N N 个输入样本 x 1 , . . . , x N x_1, ..., x_N x1,...,xN 应用了由 W W W 定义的线性变换,得到了 N N N 个输出 y 1 , . . . , y N y_1, ..., y_N y1,...,yN。这就是为什么现代AI框架(如TensorFlow, PyTorch)都基于高效的矩阵运算库构建,因为这样可以利用GPU并行计算的优势,极大地加速模型训练和推理。 -
线性回归 (Linear Regression):最简单的机器学习模型之一,试图找到一条直线(或超平面)来拟合数据。其数学形式可以简洁地用矩阵表示。如果 X X X 是包含所有样本特征的数据矩阵(通常加一列全1用于表示截距), w w w 是包含模型权重(斜率和截距)的向量,那么预测值 y p r e d y_{pred} ypred 就是:
y p r e d = X w y_{pred} = X w ypred=Xw
找到最优的 w w w 涉及求解一个基于矩阵运算的方程。
-
-
矩阵转置 (Matrix Transpose):将矩阵的行和列互换,记作 A T A^T AT。如果 A A A 是 m × n m \times n m×n 矩阵,那么 A T A^T AT 是 n × m n \times m n×m 矩阵,且 ( A T ) i j = A j i (A^T)_{ij} = A_{ji} (AT)ij=Aji。转置在很多数学推导和算法实现中非常有用,比如在计算协方差矩阵时。
小结:矩阵是组织数据(如数据集、图像)和模型参数(如神经网络权重)的二维结构。矩阵乘法是核心操作,它代表了线性变换和批量数据处理,是现代AI算法高效运行的基础。
范数:衡量向量的“长度”与数据的“距离”
我们已经知道如何用向量表示数据点,用矩阵处理数据。但有时,我们需要知道一个向量有多“大”,或者两个向量有多“相似”或“接近”。这时,范数 (Norm) 就派上用场了。
什么是范数?
范数是一个函数,它赋予向量一个非负的“长度”或“大小”的概念。对于一个向量 v v v,它的范数记作 ∣ ∣ v ∣ ∣ ||v|| ∣∣v∣∣。范数需要满足一些基本性质(非负性、齐次性、三角不等式),但对初学者来说,关键是理解它的直观意义和常用类型。
最常用的范数有两种:L1范数和L2范数。
-
L2范数 (Euclidean Norm):这是我们最熟悉的“距离”概念,即向量在空间中的欧几里得长度(勾股定理在高维的推广)。
对于 n n n 维向量 v = [ v 1 , v 2 , . . . , v n ] v = [v_1, v_2, ..., v_n] v=[v1,v2,...,vn],其L2范数为:
∣ ∣ v ∣ ∣ 2 = v 1 2 + v 2 2 + . . . + v n 2 = ∑ i = 1 n v i 2 ||v||_2 = \sqrt{v_1^2 + v_2^2 + ... + v_n^2} = \sqrt{\sum_{i=1}^{n} v_i^2} ∣∣v∣∣2=v12+v22+...+vn2=∑i=1nvi2
例如,向量 a = [ 3 , 4 ] a = [3, 4] a=[3,4] 的L2范数是 3 2 + 4 2 = 9 + 16 = 25 = 5 \sqrt{3^2 + 4^2} = \sqrt{9 + 16} = \sqrt{25} = 5 32+42=9+16=25=5。这正好是二维平面上从原点(0,0)到点(3,4)的直线距离。在AI中的应用:
- 计算距离/相似度:两个向量 u u u 和 v v v 之间的欧几里得距离,就是它们差向量的L2范数: d ( u , v ) = ∣ ∣ u − v ∣ ∣ 2 d(u, v) = ||u - v||_2 d(u,v)=∣∣u−v∣∣2。这在K近邻 (KNN) 算法、聚类 (Clustering) 算法中广泛用于衡量样本之间的相似性。距离越小,样本越相似。
- 衡量误差 (Measuring Error):在回归问题中,模型的预测值
y
p
r
e
d
y_{pred}
ypred 和真实值
y
t
r
u
e
y_{true}
ytrue 通常都是向量(或标量)。均方误差 (Mean Squared Error, MSE) 是最常用的损失函数之一,它本质上就是预测误差向量
(
y
p
r
e
d
−
y
t
r
u
e
)
(y_{pred} - y_{true})
(ypred−ytrue) 的L2范数的平方(再取平均)。
MSE = 1 N ∑ i = 1 N ( y p r e d , i − y t r u e , i ) 2 = 1 N ∣ ∣ y p r e d − y t r u e ∣ ∣ 2 2 \text{MSE} = \frac{1}{N} \sum_{i=1}^{N} (y_{pred, i} - y_{true, i})^2 = \frac{1}{N} ||y_{pred} - y_{true}||_2^2 MSE=N1∑i=1N(ypred,i−ytrue,i)2=N1∣∣ypred−ytrue∣∣22
机器学习的目标就是调整模型参数,最小化这个L2范数(的平方)。 - 权重衰减 (Weight Decay) / L2正则化:为了防止模型过拟合(在训练数据上表现很好,但在新数据上表现差),常常在损失函数中加入一个惩罚项,限制模型权重 w w w 的L2范数的大小: Loss = Original Loss + λ ∣ ∣ w ∣ ∣ 2 2 \text{Loss} = \text{Original Loss} + \lambda ||w||_2^2 Loss=Original Loss+λ∣∣w∣∣22。这会鼓励模型学习到更小、更平滑的权重,提高泛化能力。
-
L1范数 (Manhattan Norm):也叫“曼哈顿距离”或“出租车距离”。它计算的是向量各元素绝对值之和。
对于 n n n 维向量 v = [ v 1 , v 2 , . . . , v n ] v = [v_1, v_2, ..., v_n] v=[v1,v2,...,vn],其L1范数为:
∣ ∣ v ∣ ∣ 1 = ∣ v 1 ∣ + ∣ v 2 ∣ + . . . + ∣ v n ∣ = ∑ i = 1 n ∣ v i ∣ ||v||_1 = |v_1| + |v_2| + ... + |v_n| = \sum_{i=1}^{n} |v_i| ∣∣v∣∣1=∣v1∣+∣v2∣+...+∣vn∣=∑i=1n∣vi∣
例如,向量 a = [ 3 , − 4 ] a = [3, -4] a=[3,−4] 的L1范数是 ∣ 3 ∣ + ∣ − 4 ∣ = 3 + 4 = 7 |3| + |-4| = 3 + 4 = 7 ∣3∣+∣−4∣=3+4=7。想象在像曼哈顿这样的网格状城市里,从一个点到另一个点只能沿着街道走(不能斜穿),L1范数就是最短的路径长度。在AI中的应用:
- 衡量误差 (Measuring Error):平均绝对误差 (Mean Absolute Error, MAE) 是另一种常用的损失函数,它基于L1范数:
MAE = 1 N ∑ i = 1 N ∣ y p r e d , i − y t r u e , i ∣ = 1 N ∣ ∣ y p r e d − y t r u e ∣ ∣ 1 \text{MAE} = \frac{1}{N} \sum_{i=1}^{N} |y_{pred, i} - y_{true, i}| = \frac{1}{N} ||y_{pred} - y_{true}||_1 MAE=N1∑i=1N∣ypred,i−ytrue,i∣=N1∣∣ypred−ytrue∣∣1
MAE对异常值(outliers)没有MSE那么敏感。 - 特征选择 (Feature Selection) / L1正则化 (Lasso):类似L2正则化,L1正则化在损失函数中加入权重向量的L1范数惩罚项: Loss = Original Loss + λ ∣ ∣ w ∣ ∣ 1 \text{Loss} = \text{Original Loss} + \lambda ||w||_1 Loss=Original Loss+λ∣∣w∣∣1。L1正则化有一个非常有趣的特性:它倾向于产生稀疏解 (sparse solutions),即让很多权重 w i w_i wi 变成精确的零。这意味着对应的特征对模型预测没有贡献,从而达到了自动特征选择的效果。这在特征数量很多时特别有用。
- 衡量误差 (Measuring Error):平均绝对误差 (Mean Absolute Error, MAE) 是另一种常用的损失函数,它基于L1范数:
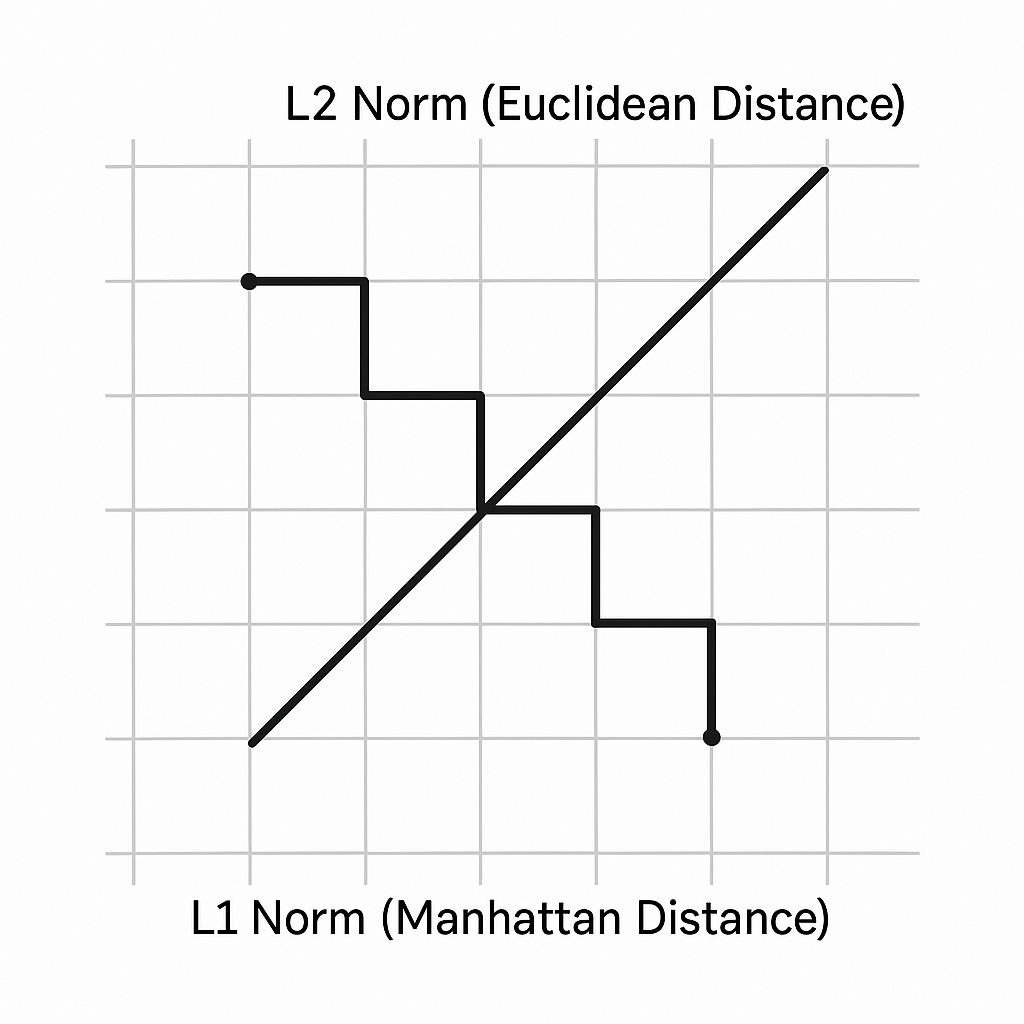
小结:范数衡量向量的大小或长度。L2范数(欧氏距离)常用于计算相似度、MSE损失和L2正则化。L1范数(曼哈顿距离)常用于MAE损失和L1正则化(Lasso),后者能带来稀疏性,实现特征选择。
特征值与特征向量:抓住数据的主要方向
想象一下,你对一块橡皮泥(代表一个数据集)进行拉伸或挤压(代表一个线性变换,比如乘以一个矩阵)。橡皮泥的形状和大小都可能改变。但是,通常会有一些特殊的方向:在这些方向上,橡皮泥只是被拉长或缩短了,方向本身并没有改变。这些特殊的方向,就是特征向量 (Eigenvectors),而拉伸或缩短的比例,就是对应的特征值 (Eigenvalues)。
数学定义
对于一个方阵
A
A
A (必须是方阵,即
n
×
n
n \times n
n×n 矩阵),如果存在一个非零向量
v
v
v 和一个标量
λ
\lambda
λ,使得:
A
v
=
λ
v
A v = \lambda v
Av=λv
那么,我们称
v
v
v 是矩阵
A
A
A 的一个特征向量,
λ
\lambda
λ 是对应的特征值。
这个公式的意义是:当矩阵 A A A 作用(变换)在向量 v v v 上时,其效果等同于仅仅用标量 λ \lambda λ 对 v v v 进行缩放。向量 v v v 的方向没有被 A A A 改变(或者只是反向,如果 λ < 0 \lambda < 0 λ<0)。
一个 n × n n \times n n×n 矩阵最多可以有 n n n 个不同的特征值,每个特征值对应至少一个特征向量(特征向量乘以任何非零常数仍然是特征向量)。
AI中的核心应用:主成分分析 (PCA)
特征值和特征向量最著名的应用之一是主成分分析 (Principal Component Analysis, PCA),这是一种非常流行的降维 (Dimensionality Reduction) 技术。
为什么需要降维?
- 可视化 (Visualization):高维数据(比如超过3维)很难直接画出来。降维到2维或3维可以帮助我们直观地理解数据的结构。
- 去除冗余 (Removing Redundancy):数据中的特征可能高度相关(比如“房屋面积”和“房间数量”),包含重复信息。降维可以去除这种冗余,保留最重要的信息。
- 提高效率 (Improving Efficiency):减少特征数量可以降低后续机器学习模型的计算复杂度和存储需求。
- 缓解过拟合 (Reducing Overfitting):过多的特征有时会导致模型学习到数据中的噪声,降维有助于提高模型的泛化能力。
PCA如何利用特征值/向量?
PCA的目标是找到数据中方差最大的方向。方差越大,通常意味着这个方向上包含了越多的信息。PCA的步骤大致如下:
- 数据中心化 (Centering):将每个特征减去其均值,使得数据的中心在原点。
- 计算协方差矩阵 (Covariance Matrix):协方差矩阵
C
C
C 描述了数据中不同特征之间的线性相关性。它是一个对称方阵。
C = 1 N − 1 X c e n t e r e d T X c e n t e r e d C = \frac{1}{N-1} X_{centered}^T X_{centered} C=N−11XcenteredTXcentered (其中 X c e n t e r e d X_{centered} Xcentered 是中心化后的数据矩阵) - 计算协方差矩阵的特征值和特征向量:求解 C v = λ v C v = \lambda v Cv=λv。
- 选择主成分 (Principal Components):
- 特征向量 v v v 代表了数据变化的方向。
- 特征值 λ \lambda λ 代表了数据在对应特征向量方向上的方差大小。
- 特征值越大的特征向量,对应的方向(主成分)就越重要,因为它解释了数据中更多的变异性。
- 投影降维 (Projection):选择前
k
k
k 个最大特征值对应的特征向量,构成一个
n
×
k
n \times k
n×k 的投影矩阵
W
W
W(假设原始数据是
n
n
n 维)。将原始数据(中心化后)乘以这个投影矩阵,就得到了降维后的
k
k
k 维数据
Z
Z
Z:
Z = X c e n t e r e d W Z = X_{centered} W Z=XcenteredW
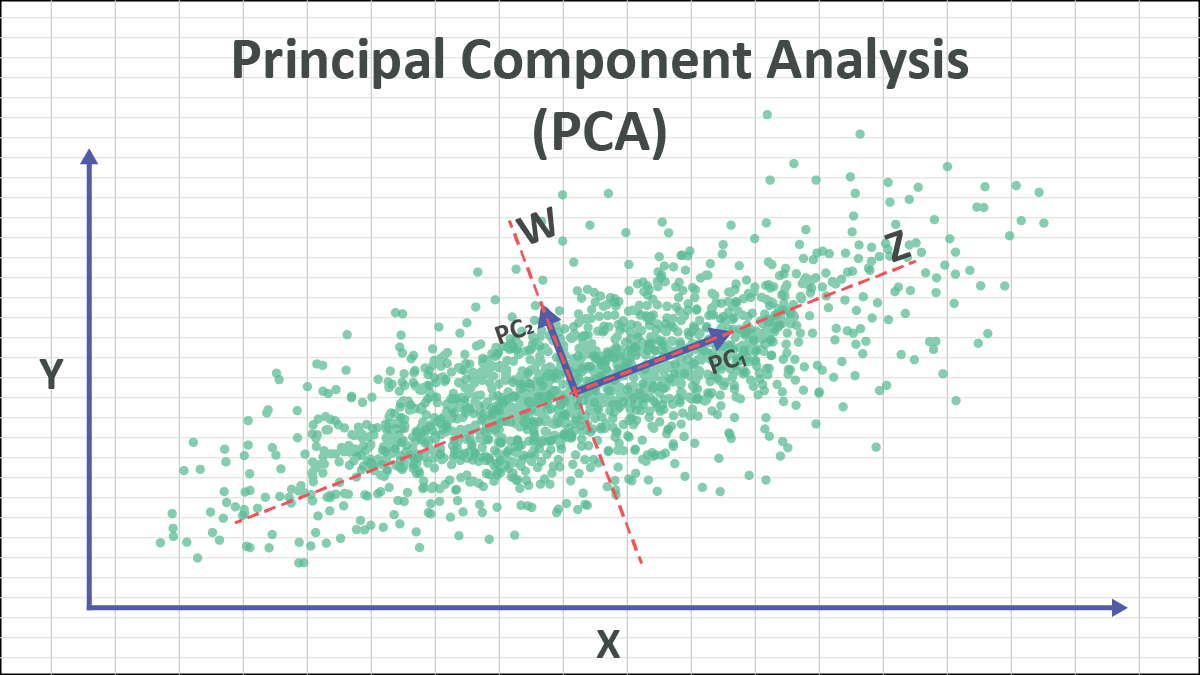
直观理解:PCA通过特征值分解,找到了数据分布的“主轴”(特征向量),这些主轴是相互正交(垂直)的。特征值告诉我们每个主轴方向上的数据“散布”程度(方差)。我们保留那些方差最大的主轴(对应最大特征值的特征向量),丢弃方差较小的主轴,从而在尽可能保留信息的前提下,降低了数据的维度。
小结:特征向量是矩阵变换下方向不变的向量,特征值是对应的缩放比例。在AI中,它们是PCA等降维技术的核心,通过找到数据方差最大的方向(对应最大特征值的特征向量),保留关键信息,去除冗余和噪声。
奇异值分解 (SVD):矩阵分解的“瑞士军刀”
特征值分解很强大,但它只适用于方阵。对于更普遍的任意 m × n m \times n m×n 矩阵 A A A,有没有类似的分解方法呢?答案是肯定的,这就是奇异值分解 (Singular Value Decomposition, SVD)。SVD是线性代数中极其重要和强大的工具,在AI和数据科学中有广泛应用。
什么是SVD?
SVD将任意一个
m
×
n
m \times n
m×n 的矩阵
A
A
A 分解为三个特殊矩阵的乘积:
A
=
U
Σ
V
T
A = U \Sigma V^T
A=UΣVT
其中:
- U: 一个 m × m m \times m m×m 的正交矩阵 (Orthogonal Matrix)。正交矩阵的列向量(称为左奇异向量)两两正交(点积为0),且每个向量的L2范数为1。 U T U = U U T = I U^T U = U U^T = I UTU=UUT=I (单位矩阵)。可以理解为定义了行空间的一组标准正交基。
- Σ (Sigma): 一个 m × n m \times n m×n 的对角矩阵。它的对角线上的元素 σ 1 , σ 2 , . . . , σ r \sigma_1, \sigma_2, ..., \sigma_r σ1,σ2,...,σr (其中 r = rank ( A ) r = \text{rank}(A) r=rank(A) 是矩阵A的秩) 称为奇异值 (Singular Values),并且它们是非负的,通常按降序排列 ( σ 1 ≥ σ 2 ≥ . . . ≥ σ r > 0 \sigma_1 \ge \sigma_2 \ge ... \ge \sigma_r > 0 σ1≥σ2≥...≥σr>0)。其余所有元素都是0。奇异值衡量了数据在各个“奇异方向”上的“能量”或“重要性”。
- V T V^T VT: 一个 n × n n \times n n×n 的正交矩阵 V V V 的转置。 V V V 的列向量(称为右奇异向量)也构成一组标准正交基,定义了列空间(或输入空间)的一组标准正交基。 V T V = V V T = I V^T V = V V^T = I VTV=VVT=I。
与特征值分解的关系:
- 对于对称正定矩阵(如协方差矩阵),其SVD与特征值分解密切相关。奇异值就是特征值的绝对值(或平方根,取决于具体定义),左奇异向量和右奇异向量就是特征向量。
- 更一般地, A T A A^T A ATA 的特征向量构成了 V V V, A A T A A^T AAT 的特征向量构成了 U U U。 A T A A^T A ATA 和 A A T A A^T AAT 的非零特征值都等于对应奇异值的平方 ( λ = σ 2 \lambda = \sigma^2 λ=σ2)。
SVD的直观理解:
SVD可以看作是将一个复杂的线性变换 A A A 分解为三个基本操作的组合:
- 旋转/反射 (Rotation/Reflection):由 V T V^T VT 实现,它将输入空间的基向量旋转到一组新的标准正交基(右奇异向量)。
- 缩放 (Scaling):由 Σ \Sigma Σ 实现,它沿着新的基向量方向对数据进行拉伸或压缩,缩放比例由奇异值 σ i \sigma_i σi 决定。
- 旋转/反射 (Rotation/Reflection):由 U U U 实现,它将缩放后的结果旋转到输出空间的标准正交基(左奇异向量)。
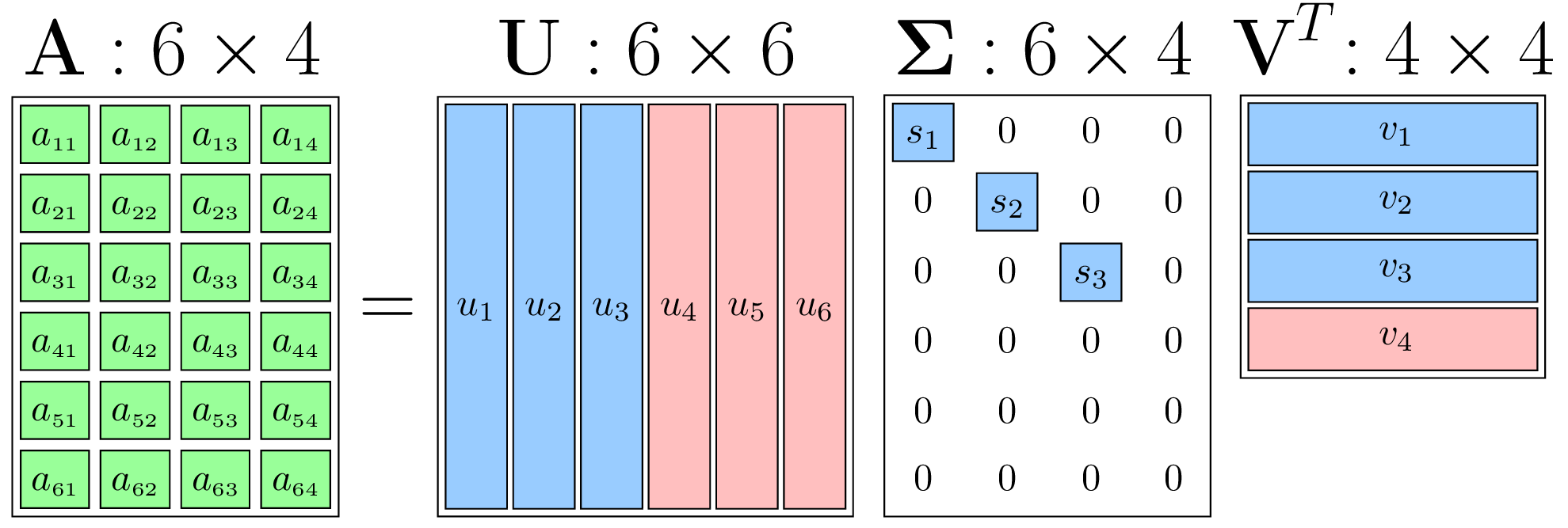
SVD在AI中的应用
SVD的应用非常广泛,因为它提供了一种分析和简化矩阵的通用方法。
-
降维 (Dimensionality Reduction):类似于PCA,SVD也可以用于降维。PCA实际上可以通过对数据矩阵(中心化后)进行SVD来计算。截断SVD (Truncated SVD) 是一个常用技巧:
A ≈ U k Σ k V k T A \approx U_k \Sigma_k V_k^T A≈UkΣkVkT
这里,我们只保留 U U U 的前 k k k 列 ( U k U_k Uk), Σ \Sigma Σ 的前 k k k 个最大的奇异值(构成 k × k k \times k k×k 对角矩阵 Σ k \Sigma_k Σk),以及 V T V^T VT 的前 k k k 行 ( V k T V_k^T VkT)。 k k k 通常远小于原始的维度。这个近似矩阵 A k = U k Σ k V k T A_k = U_k \Sigma_k V_k^T Ak=UkΣkVkT 是在所有秩为 k k k 的矩阵中,与原矩阵 A A A 最接近(在Frobenius范数或L2范数意义下)的矩阵。这被称为Eckart-Young定理。
这种降维方法直接作用于原始数据矩阵,不一定需要计算协方差矩阵,有时更数值稳定。它被用于图像压缩、文本数据分析(如潜在语义分析 LSA/LSI)等。 -
推荐系统 (Recommender Systems):在基于协同过滤的推荐系统中,我们常常有一个巨大的、稀疏的“用户-物品”评分矩阵 A A A,其中 A i j A_{ij} Aij 是用户 i i i 对物品 j j j 的评分(很多是未知的)。SVD(及其变种,如针对稀疏矩阵优化的算法)可以用来填充这个矩阵,预测用户可能对未评分物品的喜好。
基本思想是:SVD能发现用户和物品的潜在特征 (Latent Factors)。 U U U 的行向量可以看作是用户的潜在特征向量, V V V 的行向量( V T V^T VT的列向量)可以看作是物品的潜在特征向量。奇异值 Σ \Sigma Σ 则衡量了这些潜在特征的重要性。通过低秩近似 U k Σ k V k T U_k \Sigma_k V_k^T UkΣkVkT,我们可以用较少的潜在特征来重建评分矩阵,并对未评分项进行预测。 -
数据去噪 (Noise Reduction):通常认为,数据中的主要信息(信号)与较大的奇异值相关联,而噪声与较小的奇异值相关联。通过截断SVD,保留较大的奇异值及其对应的奇异向量,重建矩阵,可以在一定程度上滤除噪声。
-
计算伪逆 (Pseudoinverse):对于非方阵或者奇异矩阵(行列式为0),它们没有逆矩阵。SVD可以用来计算伪逆 (Moore-Penrose Pseudoinverse) A + A^+ A+,这在解决线性最小二乘问题(如线性回归的解析解)中非常有用。
A + = V Σ + U T A^+ = V \Sigma^+ U^T A+=VΣ+UT
其中 Σ + \Sigma^+ Σ+ 是将 Σ \Sigma Σ 中非零奇异值 σ i \sigma_i σi 取倒数 1 / σ i 1/\sigma_i 1/σi 得到(零保持不变,并进行转置以匹配维度)。
小结:SVD是一种强大的矩阵分解技术,适用于任何矩阵。它将矩阵分解为旋转、缩放、再旋转三步。奇异值代表了数据在各个奇异方向上的重要性。SVD在降维(截断SVD)、推荐系统(发现潜在特征)、去噪和计算伪逆等方面有广泛应用,是AI工具箱中的一把“瑞士军刀”。
总结:线性代数,AI的坚实地基
我们一起走过了向量、矩阵、范数、特征值/向量和SVD这些线性代数的核心概念。希望你现在能体会到,它们并非枯燥的数学符号,而是:
- 描述数据的语言:向量和矩阵让我们能结构化地表示现实世界的信息(样本、特征、图像、文本)。
- 处理数据的工具:矩阵运算(尤其是矩阵乘法)是实现模型变换、批量处理数据的基石,驱动着神经网络等算法的高效运行。
- 衡量数据的标尺:范数提供了测量向量大小、样本间距离以及模型误差的标准。
- 洞察数据的钥匙:特征值/向量和SVD帮助我们抓住数据的主要变化方向(PCA),发现潜在结构(推荐系统),并实现降维、去噪等关键任务。
线性代数就像是AI世界的物理定律,它简洁、普适,支撑着上层各种复杂算法和模型的构建。虽然我们今天只触及了皮毛,很多细节和更深层的应用(如张量分解、流形学习等)等待着进一步探索,但掌握这些基本概念,无疑为你理解和学习AI打下了坚实的基础。
不要害怕数学!把它看作是你解锁AI奥秘的工具。当你下次看到AI模型处理数据时,试着想象背后那些向量的流动、矩阵的变换、范数的计算、特征的提取……你会发现,AI的“魔法”背后,是数学赋予的逻辑与力量。
继续保持好奇,不断学习!线性代数只是开始,未来还有微积分、概率论等更多数学基石等待我们一起探索。
习题
来几道简单的练习题,巩固一下今天学到的知识吧!
1. 向量表示
假设我们用一个3维向量 [天气(1晴/0阴), 温度(摄氏度), 湿度(%)] 来描述某一天的天气状况。请用向量表示“晴天,25摄氏度,湿度60%”这一天。
2. 矩阵与数据
一个小型在线课程平台有4门课程(C1, C2, C3, C4),收集了3位学生(S1, S2, S3)的学习时长(小时)。数据如下:
S1: C1(10h), C2(5h), C3(0h), C4(8h)
S2: C1(2h), C2(15h), C3(7h), C4(1h)
S3: C1(8h), C2(0h), C3(12h), C4(3h)
请将这些数据表示成一个
3
×
4
3 \times 4
3×4 的矩阵
L
L
L,其中行代表学生,列代表课程。
3. 范数计算
给定两个二维向量(代表两个用户对两部电影的评分,范围-5到5):
用户A:
a
=
[
4
,
−
1
]
a = [4, -1]
a=[4,−1]
用户B:
b
=
[
2
,
3
]
b = [2, 3]
b=[2,3]
计算这两个用户向量之间的L2距离(欧氏距离)
∣
∣
a
−
b
∣
∣
2
||a - b||_2
∣∣a−b∣∣2 和 L1距离(曼哈顿距离)
∣
∣
a
−
b
∣
∣
1
||a - b||_1
∣∣a−b∣∣1。哪个距离更大?
4. 特征值与PCA
在一个简单的二维数据集上进行PCA分析,计算得到协方差矩阵的两个特征值分别是 λ 1 = 10 \lambda_1 = 10 λ1=10 和 λ 2 = 0.5 \lambda_2 = 0.5 λ2=0.5。哪个特征值对应的主成分(方向)更重要?为什么?
5. SVD与应用
SVD将矩阵 A A A 分解为 U Σ V T U \Sigma V^T UΣVT。在图像压缩应用中,我们通常使用截断SVD A k = U k Σ k V k T A_k = U_k \Sigma_k V_k^T Ak=UkΣkVkT 来近似原图像。这里的 k k k 与原始奇异值的数量相比,是更大、更小还是相等?为什么选择较小的 k k k 可以实现压缩?
答案
-
向量表示为: [ 1 , 25 , 60 ] [1, 25, 60] [1,25,60]
-
矩阵 L L L 为:
L = ( 10 5 0 8 2 15 7 1 8 0 12 3 ) L = \begin{pmatrix} 10 & 5 & 0 & 8 \\ 2 & 15 & 7 & 1 \\ 8 & 0 & 12 & 3 \end{pmatrix} L= 102851500712813 -
差向量 d = a − b = [ 4 − 2 , − 1 − 3 ] = [ 2 , − 4 ] d = a - b = [4-2, -1-3] = [2, -4] d=a−b=[4−2,−1−3]=[2,−4]
L2距离: ∣ ∣ d ∣ ∣ 2 = 2 2 + ( − 4 ) 2 = 4 + 16 = 20 ≈ 4.47 ||d||_2 = \sqrt{2^2 + (-4)^2} = \sqrt{4 + 16} = \sqrt{20} \approx 4.47 ∣∣d∣∣2=22+(−4)2=4+16=20≈4.47
L1距离: ∣ ∣ d ∣ ∣ 1 = ∣ 2 ∣ + ∣ − 4 ∣ = 2 + 4 = 6 ||d||_1 = |2| + |-4| = 2 + 4 = 6 ∣∣d∣∣1=∣2∣+∣−4∣=2+4=6
L1距离(6)大于L2距离(约4.47)。 -
λ 1 = 10 \lambda_1 = 10 λ1=10 对应的特征向量(主成分)更重要。因为特征值代表了数据在对应特征向量方向上的方差大小。更大的特征值意味着数据在该方向上散布得更开,包含了更多的信息或变异性。PCA的目标就是保留方差最大的方向。
-
k k k 通常远小于原始奇异值的数量(即矩阵的秩 r r r)。选择较小的 k k k 是因为SVD的奇异值通常是按降序排列的 ( σ 1 ≥ σ 2 ≥ . . . \sigma_1 \ge \sigma_2 \ge ... σ1≥σ2≥...),并且很多奇异值非常小,接近于零。这些小的奇异值对应的成分主要代表了数据中的噪声或次要细节。通过只保留前 k k k 个最大的奇异值及其对应的奇异向量(即 U k , Σ k , V k T U_k, \Sigma_k, V_k^T Uk,Σk,VkT),我们用一个秩为 k k k 的低秩矩阵 A k A_k Ak 来近似原始矩阵 A A A。存储 U k , Σ k , V k T U_k, \Sigma_k, V_k^T Uk,Σk,VkT 所需的数据量远小于存储原始矩阵 A A A 所需的数据量(尤其是当 k ≪ min ( m , n ) k \ll \min(m, n) k≪min(m,n) 时),从而实现了数据压缩。同时,由于丢弃的是贡献较小的奇异值成分,能在很大程度上保留原图像的主要信息。


















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









