






- 点我观看B站教程 更直观的操作和教程!
- 本项目GitHub仓库地址:https://github.com/LFF8888/AudioSort_TFLM
- 如果这个项目对你有一点点帮助,请不要吝啬你的 Star ⭐ 和 Fork 🍴!你的支持是我持续分享的最大动力!
一、引言:那年夏天,未竟的比赛与意外的收获
故事得从我大二那会儿说起。当时满怀激情地参加了一个物联网相关的比赛,主题就是想做一个能帮助新手爸妈识别婴儿哭声的小玩意。毕竟,谁还没听过那句“娃儿一哭,全家头大”呢?我们希望通过技术,让哭声不再是“摩斯密码”。

(TensorFlow Lite Micro - 我们今天的主角之一)
遗憾的是,那次比赛我们团队并没能冲进省赛,项目也一度搁浅。但生活就是这么奇妙,前段时间整理旧代码,发现这个项目的GitHub仓库 (点我直达,求个Star呀!) 竟然陆陆续续积累了不少小星星。这让我倍感意外,也萌生了把这个项目完整复盘并写成博客分享出来的念头。
所以,今天,它来了!我将尽可能详细地把整个流程——从数据采集、模型训练到最终在ESP32-S3上跑起来——毫无保留地分享给大家。希望能帮助对嵌入式AI、TinyML感兴趣的同学少走一些弯路,也算是对我当年那个未竟梦想的一个交代。
本项目目标: 在 ESP32-S3 微控制器上部署一个 TensorFlow Lite Micro (TFLM) 模型,用于实时识别和分类婴儿的哭声。通过分析哭声,系统可以帮助父母或看护人初步判断婴儿可能的需求,例如:
discomfort(不舒服)burp(胀气/打嗝)sleepy(困了)hunger(饿了)- 以及一个
nothing(无特定声音/背景噪音) 类别和一个自定义唤醒词xiaoxin(小鑫,致敬乐鑫嘛)。
准备好了吗?让我们一起踏上这段“听懂”婴儿哭声的AI之旅吧!
二、项目亮点与技术选型
在正式开始之前,我们先来看看这个项目有哪些值得关注的特性,以及为什么选择这些技术。
主要特性
- 端侧智能 (Edge AI):所有音频处理和机器学习推理都在ESP32-S3本地完成,无需联网,保护隐私,响应迅速。
- 低成本方案:采用广受欢迎且性价比极高的ESP32-S3开发板和常见的I2S麦克风模块,硬件成本控制在百元以内。
- 实时响应:能够对实时音频流进行分析和分类,延迟在可接受范围内(后面会看到具体推理时间)。
- 可定制化:提供的框架和代码可以方便地扩展,训练模型以识别更多或不同的声音类别。
- 完整教程:从硬件连接、数据采集、模型训练到固件烧录,提供保姆级步骤和完整源码。
技术选型浅析
-
为什么是ESP32-S3?
- 性能足够:ESP32-S3拥有双核Tensilica LX7处理器,主频高达240MHz,并带有AI指令集扩展,对于运行轻量级神经网络模型来说是足够的。
- 丰富外设:内置I2S接口,方便连接数字麦克风;拥有足够的RAM和Flash。
- 生态成熟:乐鑫官方提供了强大的ESP-IDF开发框架,并且Arduino社区支持也非常好,上手门槛相对较低。
- 性价比高:开发板价格亲民,非常适合学习和原型验证。
-
为什么是TensorFlow Lite Micro (TFLM)?
- 专为微控制器设计:TFLM是TensorFlow Lite的一个版本,专门为在只有几KB内存的微控制器上运行机器学习模型而设计。
- 无操作系统依赖:它不需要操作系统支持,没有动态内存分配(大部分情况下),核心运行时只有几十KB。
- 广泛的模型支持:支持多种常见的神经网络层,可以方便地将TensorFlow训练好的模型转换过来。
- Google出品,社区活跃:有Google背书,并且有活跃的社区支持。
-
为什么是梅尔频谱图 (Mel Spectrogram)?
音频信号直接输入神经网络,数据量太大,特征也不明显。我们需要进行特征提取。常见的音频特征有:- 时域波形:最原始的形态,信息冗余。
- 频谱图 (Spectrogram):通过短时傅里叶变换(STFT)得到,反映了信号频率随时间的变化。
- 梅尔频谱图 (Mel Spectrogram):在频谱图的基础上,将频率轴映射到梅尔标度,更符合人耳的听觉特性。它保留了较多音频细节,适合直接输入神经网络让其自行学习。
- 梅尔频率倒谱系数 (MFCC):在梅尔频谱图基础上进一步做离散余弦变换(DCT),得到更压缩的特征。信息损失较多,但计算量小。
在本项目中,我们选择了梅尔频谱图。现代深度学习研究表明,给神经网络提供更丰富原始信息的特征(如梅尔频谱图),往往能取得比高度加工的特征(如MFCC)更好的效果,因为网络可以自己学习到更优的特征表示。虽然计算量稍大,但ESP32-S3尚能应付。
三、硬件与软件准备清单
工欲善其事,必先利其器。开始之前,请确保你手头有以下装备:
硬件需求
- ESP32-S3 开发板:例如乐鑫官方的 ESP32-S3-DevKitC-1,或者其他兼容型号(比如我视频里用的带屏幕的S3,但屏幕本项目没用到)。核心是ESP32-S3芯片即可。
- I2S 麦克风模块:例如 INMP441, ICS43434, SPH0645 等。本项目视频中使用的是一个常见的 I2S MEMS 麦克风。
- 关键点:确保麦克风的
L/R(或SEL) 引脚正确配置。通常,接地选左声道,接VCC选右声道。你需要查阅你麦克风模块的手册。我们代码里默认是采集一个声道的。
- 关键点:确保麦克风的
- USB 数据线:Type-C或Micro-USB,取决于你的开发板接口,用于供电和程序下载。
- 杜邦线若干:用于连接麦克风和 ESP32-S3。
软件需求
-
Arduino IDE: 版本 1.8.19 或更高。当然,如果你更喜欢 VS Code + PlatformIO,那也是极好的。
- ESP32 Board Support Package:
- 打开 Arduino IDE,进入
文件 > 首选项。 - 在
附加开发板管理器网址中添加 ESP32 的 URL:https://raw.githubusercontent.com/espressif/arduino-esp32/gh-pages/package_esp32_index.json - 打开
工具 > 开发板 > 开发板管理器,搜索 “esp32” 并安装 “esp32 by Espressif Systems”。 - 安装后,在
工具 > 开发板中选择你的ESP32-S3型号,例如ESP32S3 Dev Module。
- 打开 Arduino IDE,进入
- 所需 Arduino 库:
TensorFlow Lite for Microcontrollers: 通过 Arduino IDE 的工具 > 管理库搜索 “TensorFlowLite_ESP32” (通常是这个名字,或者直接搜 “TensorFlow Lite”) 并安装最新版。这个库是专门为ESP32优化的TFLM版本。ArduinoFFT: 如果你打算深入研究SamplingAndMelSpectrumAndTrain.ino中FFT的实现,或者你的TFLM库版本不自带FFT实现(不太可能),可以安装它。我们的代码中直接使用了ESP32的DSP指令或等效实现,不强依赖这个库。
- ESP32 Board Support Package:
-
Python 环境: Python 3.7 或更高。推荐使用 Anaconda 或
venv创建独立的虚拟环境,避免包冲突。- 所需 Python 包: 项目的
AudioSortCode/SamplingAndMelSpectrumAndTrain/sample/requirements.txt文件中列出了依赖。主要包括:
可以直接在pip install numpy tensorflow matplotlib scikit-learn # 如果 requirements.txt 中还有其他包,也一并安装 # 例如,如果用到了 pydub 处理音频,或者 librosa 做特征提取(本项目没用,但提一下)sample目录下运行pip install -r requirements.txt。
- 所需 Python 包: 项目的
-
Git: 用于克隆本项目仓库。强烈建议你先 Fork 我的仓库到你自己的GitHub,然后再克隆你Fork后的仓库。这样方便你后续修改和管理。
# 先去GitHub页面Fork git clone https://github.com/YOUR_USERNAME/AudioSort_TFLM.git cd AudioSort_TFLM
四、项目文件结构解析
在深入代码之前,我们先来熟悉一下项目的目录结构,这有助于你理解各个部分的功能和关联。
audiosort_tflm/
├── AudioSortCode/
│ ├── SamplingAndMelSpectrumAndTrain/ # 阶段一:数据采集与特征提取代码
│ │ ├── SamplingAndMelSpectrumAndTrain.ino # Arduino Sketch: 采集音频,计算梅尔频谱图,串口打印
│ │ └── sample/ # 存放原始频谱数据(.txt)和处理后的(.npy)及训练脚本
│ │ ├── datasetSplit.py # Python脚本: 将串口输出的.txt原始数据分割成单个.npy样本
│ │ ├── melSpectrumReader.py # Python脚本: 可视化.npy梅尔频谱图,方便检查
│ │ ├── aiModuleTrain.py # Python脚本: 核心!训练CNN模型, 生成.tflite和.h模型文件
│ │ ├── requirements.txt # Python依赖包列表
│ │ ├── (示例.txt 和 .npy 文件) # 你采集的数据会放在这里
│ │ └── audio_classification_model.h (模型训练后生成)
│ │ └── audio_classification_model.tflite (模型训练后生成)
│ ├── SamplingAndRecognize/ # 阶段二:最终部署在ESP32上进行实时识别的Sketch
│ │ ├── SamplingAndRecognize.ino
│ │ └── audio_classification_model.h (从上面sample目录复制过来的模型头文件)
│ └── TFLM_TEST/ # (可选)一个简化的测试Sketch,用于验证TFLM模型推理是否正常
│ ├── TFLM_TEST.ino
│ └── audio_classification_model.h (同上,复制过来的模型头文件)
│ ├── 01-TinyML :在TensorFlow中为Arduino训练模型.md (参考资料)
│ ├── ... (其他参考资料Markdown)
├── ArduinoSineFunction/ # (可选) TFLM官方的正弦波预测演示示例,帮你理解TFLM基本流程
│ ├── ...
└── README.md # 项目说明文件 (中英文)
核心流程将围绕 AudioSortCode 目录下的三个子目录展开:
SamplingAndMelSpectrumAndTrain: 这是起点。我们用这里的 Arduino Sketch (.ino) 在 ESP32 上采集真实音频,并直接在 ESP32 上计算出梅尔频谱图,然后通过串口打印出来。配套的 Python 脚本 (.py) 则负责处理这些串口数据、训练模型。- 为什么要在ESP32上计算梅尔频谱图再打印出来,而不是直接打印原始音频数据,然后在PC上用Python计算? 关键在于保证训练时特征提取的方式和最终设备端推理时完全一致!如果在PC上用
librosa等库提取,其内部参数、窗口函数、插值方法等可能与我们在ESP32上用C++实现的版本有细微差别,这些差别可能导致模型性能下降。
- 为什么要在ESP32上计算梅尔频谱图再打印出来,而不是直接打印原始音频数据,然后在PC上用Python计算? 关键在于保证训练时特征提取的方式和最终设备端推理时完全一致!如果在PC上用
TFLM_TEST: 一个可选的中间步骤。当你用上面的 Python 脚本训练出模型 (.h文件) 后,可以用这个简单的 Sketch 来快速验证模型在 ESP32 上能否被正确加载和执行一次推理。它通常使用一个硬编码的输入样本。SamplingAndRecognize: 最终的应用程序。它结合了SamplingAndMelSpectrumAndTrain的音频采集、梅尔频谱计算逻辑,以及TFLM_TEST的模型加载、推理逻辑,实现了完整的实时音频分类功能。
五、手把手带你实践:从数据到智能
好了,理论和准备工作都差不多了,卷起袖子,我们开干!
第零步:环境确认与硬件连接
-
Arduino IDE 配置:确保 ESP32 开发板支持已安装,库已安装。在
工具菜单中选择正确的开发板型号 (如ESP32S3 Dev Module) 和对应的串口号。 -
Python 环境:确保 Python 和
requirements.txt中的包已安装。 -
I2S 麦克风连接到 ESP32-S3:
- 你需要查阅你的 ESP32-S3 开发板引脚图和你所用 I2S 麦克风模块的说明书。
- 通常的连接方式如下 (以
SamplingAndMelSpectrumAndTrain.ino中的默认引脚为例,你很可能需要修改它们):- 麦克风
SCK(BCLK, Bit Clock) -> ESP32GPIO4 - 麦克风
WS(LRCK, Word Select / Left-Right Clock) -> ESP32GPIO41 - 麦克风
SD(DOUT, Serial Data Out) -> ESP32GPIO5 - 麦克风
GND-> ESP32GND - 麦克风
VDD(电源) -> ESP323.3V - 麦克风
L/R或SEL引脚:根据手册,通常接地选择左声道,接VCC选择右声道。我们的代码默认只处理一个声道的数据。
- 麦克风
非常重要:打开
AudioSortCode/SamplingAndMelSpectrumAndTrain/SamplingAndMelSpectrumAndTrain.ino,找到以下几行,并根据你的实际接线修改引脚号!// I2S PINS - !!! 根据你的实际接线修改这里 !!! #define I2S_SCLK_PIN 4 // 时钟信号 #define I2S_LRCK_PIN 41 // 字时钟 (左右声道选择) #define I2S_SDIN_PIN 5 // 数据输入
第一步:数据采集与梅尔频谱图特征提取 (在 ESP32 上)
这一步的目标是利用 ESP32 自身来采集音频并计算梅尔频谱图,然后通过串口将这些特征数据发送到电脑保存。
-
上传数据采集 Sketch:
- 在 Arduino IDE 中打开
AudioSortCode/SamplingAndMelSpectrumAndTrain/SamplingAndMelSpectrumAndTrain.ino。 - 确认引脚配置正确无误。
- 点击 “上传” 按钮,将程序烧录到 ESP32-S3。
- 在 Arduino IDE 中打开
-
打开串口监视器并设置波特率:
- 上传成功后,打开 Arduino IDE 的
工具 > 串口监视器。 - 关键:在串口监视器的右下角,将波特率设置为
2000000(两百万)。代码中Serial.begin(2000000);定义了这个高速率,以确保大量频谱数据能快速传输。如果波特率不匹配,你会看到乱码。
- 上传成功后,打开 Arduino IDE 的
-
录制并保存梅尔频谱数据:
现在,ESP32 正在持续不断地监听麦克风,每隔一小段时间(代码中AUDIO_DURATION定义为1000ms,即1秒,SLIDE_DURATION定义了滑动窗口的步长,这里是250ms,意味着每250ms会基于过去1s的音频计算一次频谱图)就会计算一次梅尔频谱图,并将结果打印到串口。- 串口输出格式:你会看到类似这样的输出:
每个由-0.87,1.23,...,5.43 // 一行有很多浮点数,代表一个梅尔频谱图帧 -0.99,1.55,...,4.98 ... (共 NUM_MEL_FRAMES 行,本项目中是20行) --- // 分隔符,表示一个完整的1秒梅尔频谱图结束 -0.85,1.33,...,5.22 // 下一个1秒梅尔频谱图开始 ...---分隔的数据块,代表一个NUM_MEL_FILTERS(16) xNUM_MEL_FRAMES(20) 的梅尔频谱图。 - 采集过程:
- 准备好你的声音源。可以是真实的婴儿哭声录音(注意来源的授权和隐私),或者你自己模仿(如果你有这个天赋的话😂)。也可以是你自己的声音作为唤醒词或其他类别。
- 针对每个类别进行采集:
- 例如,你要采集 “hunger” (饥饿) 类别的哭声。播放饥饿哭声音频。
- 同时,在串口监视器中,选中并复制 对应时间段内输出的所有梅尔频谱数据(包括
---分隔符)。尽量多复制一些样本,比如连续的10-30秒的输出(即10-30个由---分隔的数据块)。 - 在
AudioSortCode/SamplingAndMelSpectrumAndTrain/sample/目录下创建一个文本文件,例如hunger.txt。 - 将复制的数据粘贴到
hunger.txt中并保存。
- 对你想要识别的所有声音类别重复此过程。例如,创建
sleepy.txt,discomfort.txt,burp.txt,nothing.txt(录制一些背景噪音或安静环境),xiaoxin.txt(录制你的唤醒词)。 - 数据量建议:每个类别至少采集 20-30 个有效样本(即 20-30 个由 “—” 分隔的数据块)。越多越好,数据是AI的食粮!
SamplingAndMelSpectrumAndTrain.ino核心参数解读:#define SAMPLE_RATE 8000 // 音频采样率 (Hz) - 8kHz对于语音足够 #define AUDIO_DURATION 1000 // 每次分析的音频时长 (ms) - 1秒 #define SLIDE_DURATION 250 // 滑动窗口步长 (ms) - 每250ms输出一次结果 #define NUM_MEL_FILTERS 16 // Mel滤波器数量 - 频谱图的高度 #define NUM_MEL_FRAMES 20 // Mel帧数量 (1秒音频内的帧数) - 频谱图的宽度 // FRAME_SIZE, HOP_SIZE, FFT_SIZE 等是根据以上参数计算得出的这些参数决定了梅尔频谱图的维度,即
(NUM_MEL_FILTERS, NUM_MEL_FRAMES),也就是(16, 20)。这个维度将是神经网络的输入形状。 - 串口输出格式:你会看到类似这样的输出:
第二步:数据集预处理 (使用 Python 脚本)
上一步我们得到了几个 .txt 文件,每个文件里包含了很多个梅尔频谱图数据块。现在需要用 Python 脚本把它们处理成模型训练能直接使用的格式。
-
运行
datasetSplit.py:- 确保你的所有
.txt数据文件 (如hunger.txt,sleepy.txt等) 都已经保存在AudioSortCode/SamplingAndMelSpectrumAndTrain/sample/目录下。 - 打开终端 (命令行),导航到
AudioSortCode/SamplingAndMelSpectrumAndTrain/sample/目录。 - 运行脚本:
python datasetSplit.py - 这个脚本会做以下事情:
- 遍历当前目录下所有的
.txt文件。 - 对于每个
.txt文件(比如hunger.txt):- 它会以文件名(不含扩展名)创建一个子文件夹(例如
hunger/)。如果文件夹已存在,它会先清空里面的.npy文件。 - 然后,它会读取
.txt文件内容,按---分割符将每个梅尔频谱图数据块提出来。 - 每个数据块被转换成一个 NumPy 数组,并塑形为
(NUM_MEL_FILTERS, NUM_MEL_FRAMES),然后保存为一个独立的.npy文件在对应的子文件夹中(例如hunger/hunger0000.npy,hunger/hunger0001.npy…)。
- 它会以文件名(不含扩展名)创建一个子文件夹(例如
- 遍历当前目录下所有的
执行完毕后,你的
sample/目录结构应该类似:sample/ ├── hunger.txt ├── sleepy.txt ├── ... (其他原始txt文件) ├── hunger/ │ ├── hunger0000.npy │ ├── hunger0001.npy │ └── ... ├── sleepy/ │ ├── sleepy0000.npy │ └── ... ├── (其他类别的子文件夹和npy文件) ├── datasetSplit.py ├── melSpectrumReader.py └── aiModuleTrain.py - 确保你的所有
-
(可选但推荐) 可视化检查梅尔频谱图:
数据质量至关重要!我们可以用melSpectrumReader.py来抽查几个生成的.npy文件,看看频谱图长什么样,是否符合预期。- 在
sample/目录下运行:python melSpectrumReader.py - 会弹出一个简单的GUI界面。点击 “Load Directory”,选择
sample/目录。 - 然后你就可以选择类别,并通过 “Previous” / “Next” 按钮或直接输入页码来查看每个样本的梅尔频谱图了。观察不同类别的频谱图是否在视觉上有一些区分度。如果某个类别的图看起来都差不多或者很奇怪,可能数据采集时出了问题。
- 在
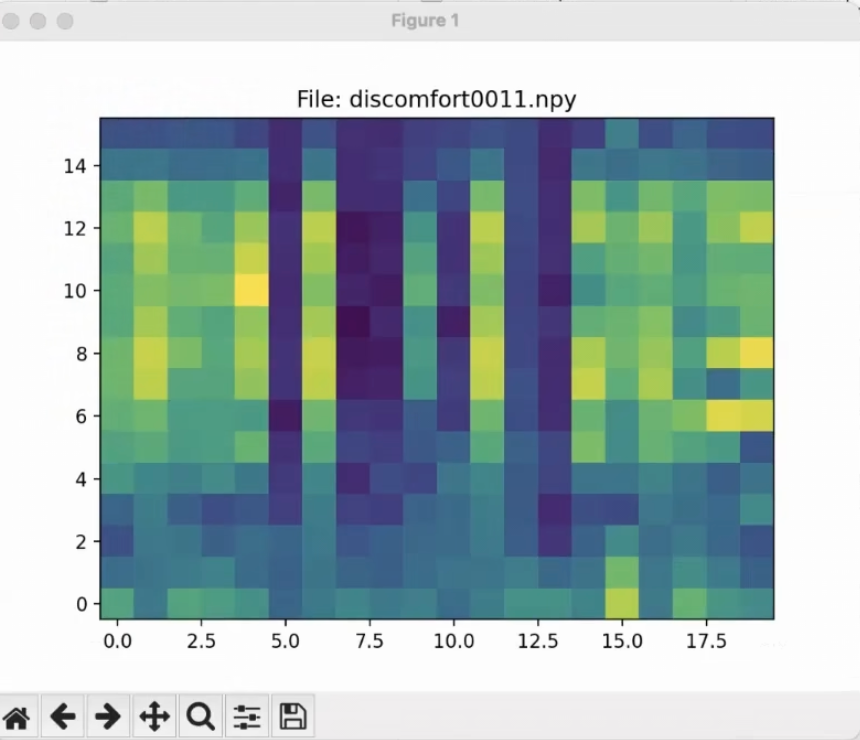
(这是一个梅尔频谱图的示例,你的图可能长得不一样)
第三步:模型训练 (使用 Python 脚本)
激动人心的时刻到了!我们要用处理好的数据来训练我们的主角——一个卷积神经网络 (CNN) 模型。
-
理解
aiModuleTrain.py脚本:
这个脚本是项目的核心AI部分。它会:- 自动扫描
sample/目录下的子文件夹,每个子文件夹名被视为一个类别标签。 - 加载所有子文件夹中的
.npy文件作为训练数据 (X) 和对应的标签 (y)。 - 将数据集划分为训练集和验证集。
- 构建一个简单的CNN模型。模型结构在代码中定义,你可以根据需要调整。本项目用了一个非常小的CNN,以适应微控制器的资源限制。
这个模型的参数量非常小 (视频中提到约318个参数,1.24KB),非常适合TinyML场景。# aiModuleTrain.py 中的模型结构示例 (简化版) model = Sequential([ Conv2D(4, (3, 3), activation='relu', input_shape=(NUM_MEL_FILTERS, NUM_MEL_FRAMES, 1)), # 输入形状是 (16, 20, 1) 1代表单通道 MaxPooling2D((2, 2)), Conv2D(4, (3, 3), activation='relu'), MaxPooling2D((2, 2)), Flatten(), Dense(4, activation='relu'), Dense(NUM_CLASSES, activation='softmax') # NUM_CLASSES 是你的类别数量 ]) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) - 训练模型,并在过程中打印每个epoch的准确率和损失。
- 绘制训练过程的准确率/损失曲线图。
- 训练完成后,将训练好的Keras模型转换为TensorFlow Lite模型 (
.tflite文件)。 - 进一步将
.tflite模型转换为C语言的头文件 (.h文件),其中包含一个unsigned char数组,这个数组就是模型在内存中的二进制表示。这个.h文件将直接被包含到我们的Arduino Sketch中。
- 自动扫描
-
运行训练脚本:
- 确保你仍然在
AudioSortCode/SamplingAndMelSpectrumAndTrain/sample/目录下。 - 运行脚本:
python aiModuleTrain.py - 训练过程会开始,终端会输出类似:
Epoch 1/100 xx/xx [==============================] - ...s xxms/step - loss: X.XXX - accuracy: Y.YYY - val_loss: A.AAA - val_accuracy: B.BBB ... - 耐心等待训练完成。训练结束后,会显示准确率和损失曲线图。
- 关键输出:在
sample/目录下会生成两个至关重要的文件:audio_classification_model.tflite: TensorFlow Lite 格式的模型文件。audio_classification_model.h: C 语言头文件,包含了模型数据数组。这个是我们最终要用到ESP32上的。
参数调整与训练技巧:
- 在
aiModuleTrain.py中,你可以调整EPOCHS(训练轮数) 和BATCH_SIZE(批处理大小)。视频中提到EPOCHS = 500,BATCH_SIZE = 300时效果较好,达到了92%左右的验证集准确率。初次尝试可以先用较小的EPOCHS(如50-100) 快速验证流程。 - 如果你的准确率很低,检查:
- 数据量是否足够?每个类别太少样本很难学好。
- 数据质量是否有问题?(用
melSpectrumReader.py检查) - 不同类别的样本是否均衡?某个类别样本过多或过少都可能影响。
- 模型是否过于简单或复杂?(可以尝试增减CNN的层数或滤波器数量,但要注意模型大小)
nothing类别非常重要,它帮助模型区分有效声音和背景噪音。务必采集一些典型的环境噪音作为nothing类的样本。- 对于唤醒词
xiaoxin,如果只用你自己的声音录制,它可能只对你的声音敏感。要提高泛化能力,需要更多不同人的语音数据,或者将普通说话声也加入nothing类别。
- 确保你仍然在
第四步:模型部署与推理验证 (在 ESP32 上)
模型训练好了,现在是骡子是马,拉到ESP32上遛遛!
-
准备模型头文件:
- 将上一步在
sample/目录下生成的audio_classification_model.h文件,复制到以下两个位置:AudioSortCode/TFLM_TEST/目录下 (用于简化测试)AudioSortCode/SamplingAndRecognize/目录下 (用于最终应用)
- 注意:如果你重新训练了模型,记得要用新生成的
.h文件替换掉这两个目录下的旧文件。
- 将上一步在
-
选项 A: 使用
TFLM_TEST.ino进行基本推理测试 (推荐先做这一步):
这个Sketch的目的是用一个硬编码在代码中的梅尔频谱图样本来测试模型推理流程是否通畅。- 在 Arduino IDE 中打开
AudioSortCode/TFLM_TEST/TFLM_TEST.ino。 - 代码解读:
- 它会
#include "audio_classification_model.h"。 - 包含TFLM所需的核心头文件,如
TensorFlowLite.h。 - 定义
kTensorArenaSize:这是为TFLM运行时分配的内存区域大小。如果模型较大或中间张量较多,可能需要增大此值。如果太小,会在interpreter->AllocateTensors()时报错。本项目中16 * 1024(16KB) 应该是足够的。 InitializeModel()函数:加载模型、创建算子解析器 (MicroMutableOpResolver)、创建解释器 (MicroInterpreter)、分配张量内存。- 算子解析器:你需要在这里添加模型中用到的所有类型的层(算子)。例如,如果模型用了卷积 (
Conv2D)、池化 (MaxPool2D)、全连接 (FullyConnected)、Softmax,就需要resolver.AddConv2D(); resolver.AddMaxPool2D(); ...。如果漏了某个算子,加载时会报错。aiModuleTrain.py在转换模型后会打印出模型中用到的算子,可以参考。
- 算子解析器:你需要在这里添加模型中用到的所有类型的层(算子)。例如,如果模型用了卷积 (
RunInference()函数:将硬编码的输入数据填入输入张量,调用interpreter->Invoke()执行推理,然后从输出张量读取结果。setup()中调用InitializeModel()。loop()中反复调用RunInference()并打印结果和推理时间。
- 它会
- 编译并上传到 ESP32-S3。
- 打开串口监视器 (波特率
2000000)。 - 你应该能看到类似输出:
如果能看到这样的输出,并且推理时间在几毫秒到几十毫秒之间,说明你的模型转换、加载和基本推理流程是OK的!类别名称的顺序取决于你在Model Initialized. Inference time: 4 ms Category 0 (burp): 0.01 Category 1 (discomfort): 0.05 Category 2 (hunger): 0.85 <-- 假设硬编码的样本是hunger Category 3 (nothing): 0.03 Category 4 (sleepy): 0.04 Category 5 (xiaoxin): 0.02 -------------------aiModuleTrain.py中加载数据时文件夹的字母顺序,或者你在代码中定义的类别数组。
- 在 Arduino IDE 中打开
-
选项 B: 使用
SamplingAndRecognize.ino进行实时识别 (最终应用):
这是集大成者,结合了音频实时采集、梅尔频谱计算和TFLM模型推理。- 在 Arduino IDE 中打开
AudioSortCode/SamplingAndRecognize/SamplingAndRecognize.ino。 - 重要: 再次检查并确保此 Sketch 中的 I2S 引脚定义与你的硬件连接一致 (应与第一步中
SamplingAndMelSpectrumAndTrain.ino的引脚配置相同)。// I2S PINS - !!! 再次确认你的接线 !!! #define I2S_SCLK_PIN 4 #define I2S_LRCK_PIN 41 #define I2S_SDIN_PIN 5 - 代码逻辑:
setup(): 初始化串口、麦克风I2S、计算Mel滤波器系数(这些与SamplingAndMelSpectrumAndTrain.ino类似),然后初始化TFLM模型(与TFLM_TEST.ino类似)。loop():- 通过
readNonBlockingI2S()非阻塞地读取I2S音频数据到环形缓冲区。 - 使用滑动窗口机制,当收集到足够数据(1秒音频)时,调用
computeMelSpectrogram()计算梅尔频谱图。 - 将计算得到的梅尔频谱图数据填入TFLM模型的输入张量。
- 调用
interpreter->Invoke()执行推理。 - 从输出张量获取每个类别的概率。
- 通过串口打印各类别及其概率。
- 通过
- 编译并上传到 ESP32-S3。
- 打开串口监视器 (波特率
2000000)。 - 现在,对着麦克风发出声音(比如播放之前用于训练的婴儿哭声音频,或者说出你的唤醒词)。你应该能在串口监视器中看到实时的分类结果,显示每个类别的概率。
- 在 Arduino IDE 中打开
六、预期效果与演示
当运行 SamplingAndRecognize.ino 时,串口监视器会实时输出类似以下格式的信息:
I (350) I2S: DMA Malloc info, datalen=1024, dma_buf_count=2
Model Initialized.
Mel filter coefficients computed.
Microphone Initialized. Setup complete.
discomfort: 0.01 nothing: 0.85 burp: 0.02 xiaoxin: 0.01 sleepy: 0.05 hunger: 0.06
discomfort: 0.02 nothing: 0.88 burp: 0.01 xiaoxin: 0.00 sleepy: 0.03 hunger: 0.06
... (持续输出)
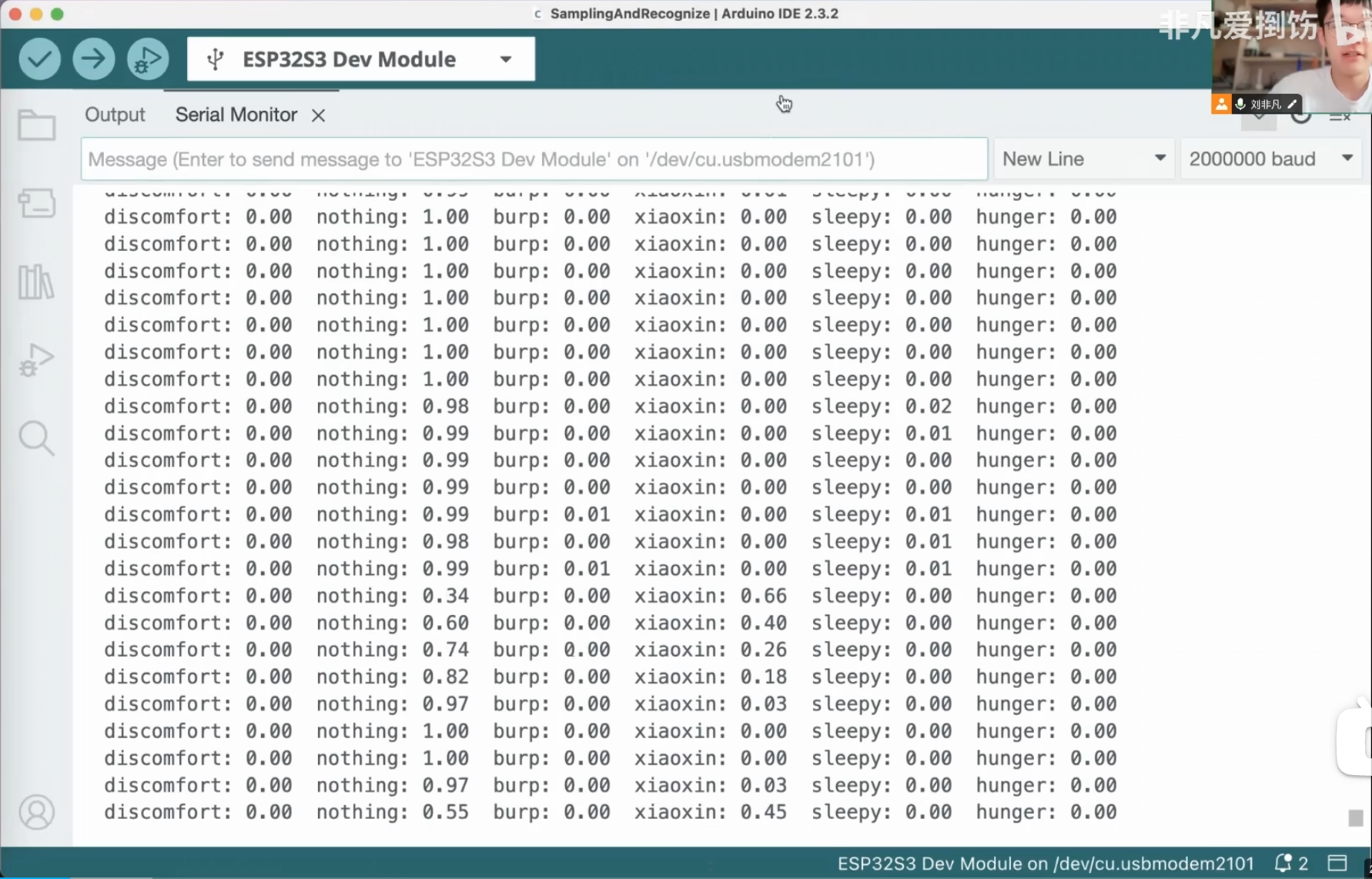
当你播放特定类型的婴儿哭声时,对应类别的概率应该会显著升高。例如,播放“饥饿”的哭声,hunger 的概率会接近1.0。说出唤醒词“小鑫”,xiaoxin 的概率会升高。
B站演示视频: 点我观看B站的实际演示效果 (视频中可能包含更直观的操作和结果展示)
七、注意事项、优化与展望
- 波特率一致性:再次强调,所有 Arduino Sketch 的串口通信波特率均设置为
2000000,请确保串口监视器也使用此波特率,否则乱码会让你怀疑人生。 - I2S 引脚准确性:务必根据您的实际硬件连接修改 Sketch 中的 I2S 引脚定义。接错了麦克风不工作,或者采集到噪声。
- 数据永远是王道:模型性能高度依赖于训练数据的质量和数量。
- 多样性:尽量采集不同场景、不同强度、略带背景音的样本。
- 数量:每个类别至少20-30个清晰样本,越多通常越好。
- 平衡性:各类别样本数量尽量均衡。
kTensorArenaSize的调整:如果遇到Failed to allocate tensors!错误,通常是kTensorArenaSize太小了。- 可以尝试在 Arduino Sketch 中逐步增大
kTensorArenaSize的值 (例如从16 * 1024增加到20 * 1024或32 * 1024),但这受限于 ESP32 的可用 RAM。ESP32-S3的RAM比普通ESP32多一些,有一定调整空间。 - 根本的解决办法是在
aiModuleTrain.py中构建更小的模型(减少层数、滤波器数量、神经元数量)。
- 可以尝试在 Arduino Sketch 中逐步增大
- 结果平滑/后处理:单次推理结果可能跳变。为了提高识别的稳定性,可以在设备端代码中加入简单的后处理逻辑,例如:
- 滑动平均:对最近几次的概率输出进行平均。
- 投票机制/计数器:连续N次识别结果一致才最终确认该类别。例如,连续3次检测到
hunger概率最高,才真正判断为hunger。
- 功耗优化:对于电池供电场景,需要考虑功耗。可以结合ESP32的Light Sleep模式,例如通过声音强度检测(VAD - Voice Activity Detection)来唤醒系统进行精细分类,而不是一直运行高频采样和推理。
- 模型优化:
- 量化 (Quantization):
aiModuleTrain.py中默认使用了tf.lite.Optimize.DEFAULT,这通常包含了权重量化。可以研究更深入的量化技术,如整型量化 (full integer quantization),以进一步减小模型大小和加速推理,但这可能需要代表性的校准数据集。 - 剪枝 (Pruning) 和 知识蒸馏 (Knowledge Distillation):更高级的模型压缩技术,可以得到更极致的模型。
- 量化 (Quantization):
- 未来展望:
- 更多哭声细分:比如区分疼痛、害怕等更具体的哭声。
- 集成其他传感器:结合温度、湿度、甚至摄像头(ESP32-S3有带摄像头的型号)信息,做多模态的婴儿状态判断。
- 个性化定制:允许用户录制自己宝宝的特定声音进行微调训练。
八、结语与致谢
从一个大二时未竟的比赛项目,到今天能把这份相对完整的教程分享出来,我内心还是挺感慨的。这个过程不仅是对当年技术细节的回顾,更是一次知识的梳理和沉淀。
希望这个“婴儿哭声识别”项目能为你打开一扇通往嵌入式AI和TinyML世界的小窗。它或许不完美,但贵在完整和开源。如果你在实践过程中遇到任何问题,或者有任何改进建议,非常欢迎在GitHub仓库中提Issue,或者在本文评论区交流。
最后,也是最重要的:
- 本项目GitHub仓库地址:https://github.com/LFF8888/AudioSort_TFLM
- 如果这个项目对你有一点点帮助,请不要吝啬你的 Star ⭐ 和 Fork 🍴!你的支持是我持续分享的最大动力!
感谢你的阅读,我们下一个项目再见!
参考资料与鸣谢:
- TensorFlow Lite for Microcontrollers 官方文档
- Shawn Hymel 的 TinyML 教程 (Digi-Key Electronics)
- 乐鑫 ESP-IDF 文档
- 以及所有在学习路上给予我帮助的开源社区和前辈们!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









