







2019.3.23 整理一下项目 准备写简历,第一个项目基于开源数据预测京东用户购买意向




数据挖掘流程:
(一).数据清洗
1. 数据集完整性验证
2. 数据集中是否存在缺失值
3. 数据集中各特征数值应该如何处理
4. 哪些数据是我们想要的,哪些是可以过滤掉的
5. 将有价值数据信息做成新的数据源
6. 去除无行为交互的商品和用户
7. 去掉浏览量很大而购买量很少的用户(惰性用户或爬虫用户)
(二).数据理解与分析
1. 掌握各个特征的含义
2. 观察数据有哪些特点,是否可利用来建模
3. 可视化展示便于分析
4. 用户的购买意向是否随着时间等因素变化
(三).特征提取
1. 基于清洗后的数据集哪些特征是有价值
2. 分别对用户与商品以及其之间构成的行为进行特征提取
3. 行为因素中哪些是核心?如何提取?
4. 瞬时行为特征or累计行为特征?
(四).模型建立
1. 使用机器学习算法进行预测
2. 参数设置与调节
3. 数据集切分?
数据集验证
首先检查JData_User中的用户和JData_Action中的用户是否一致
保证行为数据中的所产生的行为均由用户数据中的用户产生(但是可能存在用户在行为数据中无行为)
思路:利用pd.Merge连接sku 和 Action中的sku, 观察Action中的数据是否减少 Example:
def user_action_check():
df_user = pd.read_csv('data/JData_User.csv',encoding='gbk')
df_sku = df_user.loc[:,'user_id'].to_frame()
df_month2 = pd.read_csv('data/JData_Action_201602.csv',encoding='gbk')
print ('Is action of Feb. from User file? ', len(df_month2) == len(pd.merge(df_sku,df_month2)))
df_month3 = pd.read_csv('data/JData_Action_201603.csv',encoding='gbk')
print ('Is action of Mar. from User file? ', len(df_month3) == len(pd.merge(df_sku,df_month3)))
df_month4 = pd.read_csv('data/JData_Action_201604.csv',encoding='gbk')
print ('Is action of Apr. from User file? ', len(df_month4) == len(pd.merge(df_sku,df_month4)))
user_action_check()
结论: User数据集中的用户和交互行为数据集中的用户完全一致
根据merge前后的数据量比对,能保证Action中的用户ID是User中的ID的子集
检查是否有重复记录
除去各个数据文件中完全重复的记录,可能解释是重复数据是有意义的,比如用户同时购买多件商品,同时添加多个数量的商品到购物车等...
def deduplicate(filepath, filename, newpath):
df_file = pd.read_csv(filepath,encoding='gbk')
before = df_file.shape[0] #取出矩阵的第一维长度
df_file.drop_duplicates(inplace=True) #去除重复项
after = df_file.shape[0]
n_dup = before - after
print ('No. of duplicate records for ' + filename + ' is: ' + str(n_dup))
if n_dup != 0:
df_file.to_csv(newpath, index=None)
else:
print ('no duplicate records in ' + filename)
# deduplicate('data/JData_Action_201602.csv', 'Feb. action', 'data/JData_Action_201602_dedup.csv')
deduplicate('data/JData_Action_201603.csv', 'Mar. action', 'data/JData_Action_201603_dedup.csv')
deduplicate('data/JData_Action_201604.csv', 'Feb. action', 'data/JData_Action_201604_dedup.csv')
deduplicate('data/JData_Comment.csv', 'Comment', 'data/JData_Comment_dedup.csv')
deduplicate('data/JData_Product.csv', 'Product', 'data/JData_Product_dedup.csv')
deduplicate('data/JData_User.csv', 'User', 'data/JData_User_dedup.csv')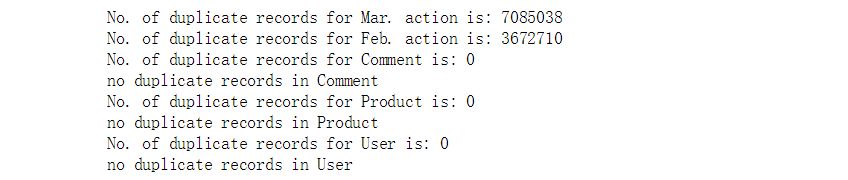
结论:商品评论,属性,用户没有重复记录。但是鼠标点击量重复很大,需要思考如何处理,去掉还是不去掉,可以分布进行,但是任务量太大,选择不去掉。
df_month2 = pd.read_csv('data/JData_Action_201602.csv',encoding='gbk')
IsDuplicated = df_month2.duplicated()
df_d = df_month2[IsDuplicated]
df_d.groupby('type').count()

结论:大部分重复数据都是由于浏览(1)和点击(6)产生
检查是否存在注册时间在2016年-4月-15号之后的用户
开源数据给的数据是2016.4.15之前的,行为之后的数据行为默认无效
import pandas as pd
df_user = pd.read_csv('data\JData_User.csv',encoding='gbk')
df_user['user_reg_tm'] = pd.to_datetime(df_user['user_reg_tm'])
#.loc[]中括号里面是先行后列,以逗号分割,行和列分别是行标签和列标签
df_user.loc[df_user.user_reg_tm >= '2016-4-15']
由于注册时间是京东系统错误造成,如果行为数据中没有在4月15号之后的数据的话,那么说明这些用户还是正常用户,并不需要删除。
再次开始判断是否存在行为
df_month = pd.read_csv('data\JData_Action_201604.csv')
df_month['time'] = pd.to_datetime(df_month['time'])
df_month.loc[df_month.time >= '2016-4-16']
![]()
结论:说明用户没有异常操作数据,所以这一批用户不删除
行为数据中的user_id为浮点型,进行INT类型转换
单纯为了方便查看数据,为float也行,比较的时候注意类型一致
import pandas as pd
df_month = pd.read_csv('data\JData_Action_201602.csv',encoding='gbk')
#apply函数把dataframe的每一列做类型转换
df_month['user_id'] = df_month['user_id'].apply(lambda x:int(x))
print (df_month['user_id'].dtype)
df_month.to_csv('data\JData_Action_201602.csv',index=None)
df_month = pd.read_csv('data\JData_Action_201603.csv',encoding='gbk')
df_month['user_id'] = df_month['user_id'].apply(lambda x:int(x))
print (df_month['user_id'].dtype)
df_month.to_csv('data\JData_Action_201603.csv',index=None)
df_month = pd.read_csv('data\JData_Action_201604.csv',encoding='gbk')
df_month['user_id'] = df_month['user_id'].apply(lambda x:int(x))
print (df_month['user_id'].dtype)
df_month.to_csv('data\JData_Action_201604.csv',index=None)
年龄区间的处理
特征之一
把年龄映射为区间
import pandas as pd
df_user = pd.read_csv('data\JData_User.csv',encoding='gbk')
def tranAge(x):
if x == u'15岁以下':
x='1'
elif x==u'16-25岁':
x='2'
elif x==u'26-35岁':
x='3'
elif x==u'36-45岁':
x='4'
elif x==u'46-55岁':
x='5'
elif x==u'56岁以上':
x='6'
return x
df_user['age'] = df_user['age'].apply(tranAge)
print (df_user.groupby(df_user['age']).count())
df_user.to_csv('data\JData_User.csv',index=None)
为了能够进行上述清洗,在此首先构造了简单的用户(user)行为特征和商品(item)行为特征,对应于两张表user_table和
user_table
- user_table特征包括:
- user_id(用户id),age(年龄),sex(性别),
- user_lv_cd(用户级别),browse_num(浏览数),
- addcart_num(加购数),delcart_num(删购数),
- buy_num(购买数),favor_num(收藏数),
- click_num(点击数),buy_addcart_ratio(购买加购转化率),
- buy_browse_ratio(购买浏览转化率),
- buy_click_ratio(购买点击转化率),
- buy_favor_ratio(购买收藏转化率)
item_table特征包括:
- sku_id(商品id),attr1,attr2,
- attr3,cate,brand,browse_num,
- addcart_num,delcart_num,
- buy_num,favor_num,click_num,
- buy_addcart_ratio,buy_browse_ratio,
- buy_click_ratio,buy_favor_ratio,
- comment_num(评论数),
- has_bad_comment(是否有差评),
- bad_comment_rate(差评率)
构建user_table
#定义文件名
ACTION_201602_FILE = "data/JData_Action_201602.csv"
ACTION_201603_FILE = "data/JData_Action_201603.csv"
ACTION_201604_FILE = "data/JData_Action_201604.csv"
COMMENT_FILE = "data/JData_Comment.csv"
PRODUCT_FILE = "data/JData_Product.csv"
USER_FILE = "data/JData_User.csv"
USER_TABLE_FILE = "data/User_table.csv"
ITEM_TABLE_FILE = "data/Item_table.csv"
# 导入相关包
import pandas as pd
import numpy as np
from collections import Counter
# 功能函数: 对每一个user分组的数据进行统计
def add_type_count(group):
behavior_type = group.type.astype(int)
# 用户行为类别
type_cnt = Counter(behavior_type)
# 1: 浏览 2: 加购 3: 删除
# 4: 购买 5: 收藏 6: 点击
group['browse_num'] = type_cnt[1]
group['addcart_num'] = type_cnt[2]
group['delcart_num'] = type_cnt[3]
group['buy_num'] = type_cnt[4]
group['favor_num'] = type_cnt[5]
group['click_num'] = type_cnt[6]
return group[['user_id', 'browse_num', 'addcart_num',
'delcart_num', 'buy_num', 'favor_num',
'click_num']]由于用户行为数据量较大,一次性读入可能造成内存错误(Memory Error),因而使用pandas的分块(chunk)读取.
#对action数据进行统计
#根据自己调节chunk_size大小
def get_from_action_data(fname, chunk_size=50000):
reader = pd.read_csv(fname, header=0, iterator=True,encoding='gbk')
chunks = []
loop = True
while loop:
try:
# 只读取user_id和type两个字段
chunk = reader.get_chunk(chunk_si 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1629
1629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









