






1.安装
github网址https://github.com/FudanNLP/fnlp/wiki/quicktutorial
安装过程在github网站上有详细介绍,请耐心观看。
不要下载后直接解压就导入项目按照要求一步一步来
简单介绍一下安装过程
1.下载FNLP直接下载从FNLP下载地址点击
git进行下载
git clone https://github.com/xpqiu/fnlp.git
********这个必须有******************************************************************
除了源码文件,还需要下载FNLP语言模型文件。由于模型文件交大,不便于存放在源码库之中,请至https://github.com/FudanNLP/fnlp/releases页面下载,并将模型文件放在“models”目录。
- seg.m 分词模型
- pos.m 词性标注模型
- dep.m 依存句法分析模型***********************************************************************************
2.首先使用FNLP需要进行JDK的安装(版本需要jdk1.6以上,本人使用的1.8表示好用),环境变量等配置不过多介绍。
配置完成后可在cmd中输入
java -version
javac -version进行检验
3.安装和配置maven。(自己百度不过多介绍)
配置完成后可以使用
mvn -version进行检验
4.编译FNLP
在命令行中进入FNLP的源码目录(即“README.md”)
cd +文件夹地址
举例
>cd C:\Users\hyjx\Desktop\fnlp-master在命令行输入如下命令进行编译
mvn install -Dmaven.test.skip=true此时编译后会显示编译结果
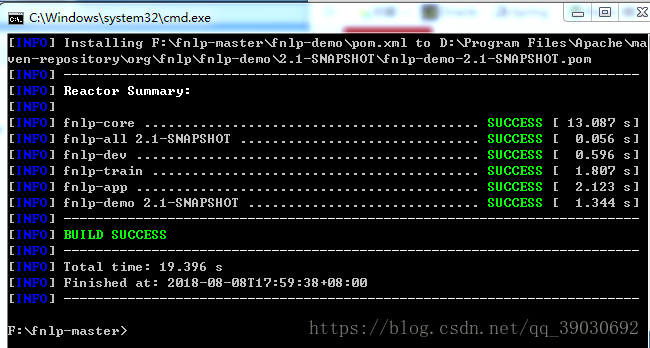
执行maven命令
mvn dependency:copy-dependencies -DoutputDirectory=libs该命令会将jar包copy到工程目录的libs里面。
2.在eclipse项目中引用FNLP
本人习惯用eclipse所以只使用了eclipse进行了项目的引用实践
在你想要使用FNLP的项目名称上选择项目名称右键点击,在菜单中选择Build Path,Add External Archives ...

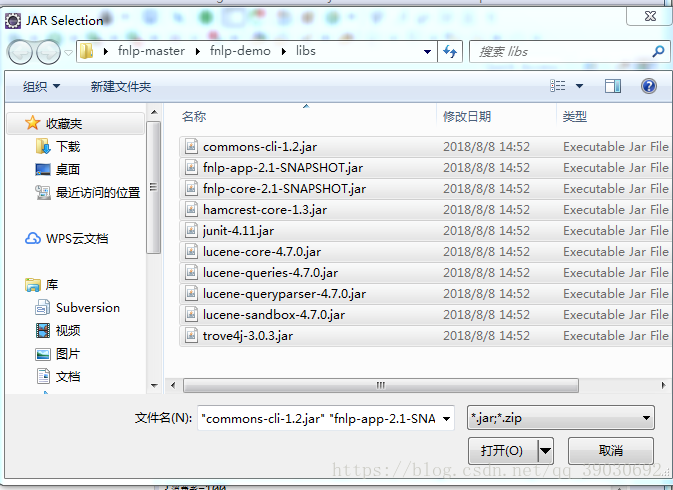
我在这里全都导入了项目里。
添加模型文件
模型文件指词典、训练后的中文分词器、POS标注器等,它们位于FNLP源码目录下的“models”目录之中。将此目录复制到Eclipse项目目录之下即可。最终显示为
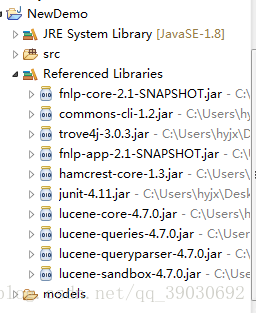
此时就可以进行FNLP功能的应用了,在应用之前最好对jvm进行设置
修改最大内存量
接下来修改程序的可用内存大小。由于FNLP的语言模型加载需要较大内存,Java默认的内存量通常不足,因此尽量设为1024MB或更大。
在Package Explorer中选择项目名称,右击,在菜单中选择Properties。在弹出的属性窗口左侧选择Run/Debug Settings,则会呈现项目所有的启动配置。选择当前的启动配置,并点击右侧Edit...,出现Edit Configuration窗口。选择Arguments栏,找到VM arguments输入框,并添加如下参数:
-Xmx2048m
一定要设置 字符串数据量比较大时很容易OOM,我处理了1个g的数据最后将内存设置为-Xmx8000m,之前一直报OOM。
3.功能
1.普通的中文分词功能
package com.xxx.forfnlp;
import org.fnlp.nlp.cn.CNFactory;
public class Demo {
public static void main(String[] args) throws Exception {
// 创建中文处理工厂对象,并使用“models”目录下的模型文件初始化
CNFactory factory = CNFactory.getInstance("models");
// 使用分词器对中文句子进行分词,得到分词结果
String[] words = factory.seg("关注自然语言处理、语音识别、深度学习等方向的前沿技术和业界动态。");
// 打印分词结果
for(String word : words) {
System.out.print(word + " ");
}
System.out.println();
}
}
关注 自然 语言 处理 、 语音 识别 、 深度 学习 等 方向 的 前沿 技术 和 业界 动态 。
2.中文词性标注 可以进行分词的同时,还会对词语进行词性标注
package com.xxx.forfnlp;
import org.fnlp.nlp.cn.CNFactory;
public class Demo1 {
public static void main(String[] args) throws Exception {
//创建中文处理工厂对象,并使用“models”目录下的模型文件初始化
CNFactory factory = CNFactory.getInstance("models");
//使用标注器对中文句子进行标注,等到标注结果
String result = factory.tag2String("你好,你喜欢喝矿泉水么");
//显示标注结果
System.out.println(result);
}
}
显示结果:
你/人称代词 好/形谓词 ,/标点 你/人称代词 喜欢/动词 喝/动词 矿泉水/名词 么/语气词3.关键词提取,此代码提取了5个关键字。
package com.xxx.forfnlp;
import org.fnlp.app.keyword.AbstractExtractor;
import org.fnlp.app.keyword.WordExtract;
import org.fnlp.nlp.cn.tag.CWSTagger;
import org.fnlp.nlp.corpus.StopWords;
public class Demo2 {
public static void main(String[] args) throws Exception {
StopWords sw= new StopWords("models/stopwords");
CWSTagger seg = new CWSTagger("models/seg.m");
AbstractExtractor key = new WordExtract(seg,sw);
String info="花谢花飞花满天,红消香断有谁怜?游丝软系飘春榭1,落絮轻沾扑绣帘。闺中女儿惜春暮,愁绪满怀无释处。手把花锄出绣帘,忍踏落花来复去。柳丝榆荚自芳菲,不管桃飘与李飞;桃李明年能再发,明年闺中知有谁?三月香巢已垒成,梁间燕子太无情!明年花发虽可啄,却不道人去梁空巢也倾。一年三百六十日,风刀霜剑严相逼;明媚鲜妍能几时,一朝漂泊难寻觅。花开易见落难寻,阶前愁杀葬花人,独倚花锄泪暗洒,洒上空枝见血痕。杜鹃无语正黄昏,荷锄归去掩重门;青灯照壁人初睡,冷雨敲窗被未温。怪奴底事倍伤神?半为怜春半恼春。怜春忽至恼忽去,至又无言去未闻。昨宵庭外悲歌发,知是花魂与鸟魂?花魂鸟魂总难留,鸟自无言花自羞;愿侬此日生双翼,随花飞到天尽头。天尽头,何处有香丘2?未若锦囊收艳骨,一抔净土掩风流.质本洁来还洁去,强于污淖陷渠沟。尔今死去侬收葬,未卜侬身何日丧?侬今葬花人笑痴,他年葬侬知是谁?试看春残花渐落,便是红颜老死时;一朝春尽红颜老,花落人亡两不知!";
info=info.replace("\n","");
System.out.println(key.extract(info,5, true));
}
}
输出结果:
{明年=100, 怜春=90, 花魂=85, 知=85, 鸟魂=84}4.以上功能可以组合使用例如提取一段字符串中的前100个关键词(只提取名词)
package com.xxx.forfnlp;
import org.fnlp.app.keyword.AbstractExtractor;
import org.fnlp.app.keyword.WordExtract;
import org.fnlp.nlp.cn.CNFactory;
import org.fnlp.nlp.cn.tag.CWSTagger;
import org.fnlp.nlp.corpus.StopWords;
public class Demo3 {
public static void main(String[] args) throws Exception {
//创建中文处理工厂对象,使用“models”目录下的模型文件初始化
CNFactory factory = CNFactory.getInstance("models");
//使用标注器对中文句子进行标注,得到标注结果
String result = factory.tag2String(Str.str);
System.gc();
String [] strs;
strs = result.split(" ");
StringBuilder sb = new StringBuilder();
for(int i = 0; i < strs.length ;i++) {
if (strs[i].contains("名词")) {
sb.append(strs[i]);
}
}
System.gc();
String str =sb.toString().replaceAll("/名词", "");
StopWords sw= new StopWords("models/stopwords");
CWSTagger seg = new CWSTagger("models/seg.m");
AbstractExtractor key = new WordExtract(seg,sw);
String info=str;
System.gc();
info=info.replace("\n","");
System.gc();
System.out.println(key.extract(info,100, true));
}
}
输出结果














 182
182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









