







HashMap是Map的典型实现类,也是HashSet的底层实现
HashMap的特点
-
非线程安全
-
性能高
-
key和value都可以允许为null(可存在一个key为null,多个value为null)
-
不允许重复元素(这里针对key值)
-
底层采用数组+链表+红黑树
-
存储为key的对象必须重写equals和hashCode方法
与Hashset一样,尽量不要使用可变对象作为key值,如果非要使用,尽量不要在程序中修改可变对象
元素重复的判断机制
HashSet类判断添加的元素是否重复的标准:
-
两个对象通过hashCode()方法比较hash值是否相等
-
两个对象的equals()方法返回值也相等
对于存放在set容器中的对象,对应的类一定要重写hashCode()方法和equals()方法,以实现对象相等规则 对象相等规则:相等的对象必须具有相等的hash散列码
源码分析
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
为什么对象调用了hashCode方法,还要和本身无符号右移16位后的数异或?
例1:String str="123"
str.hashCode()=48690二进制表示为1011 1110 0011 0010
右移16位二进制表示为0000 0000 0000 0000=0
h=key.hashCode())^(h>>>16)结果为48690
例2:String str="123566987"
str.hashCode()=-1837824043二进制表示为1001 0010 0111 0101 0000 0111 1101 0101
右移16位二进制表示为1001 0010 0111 0101
h=key.hashCode())^(h>>>16)异或后结果为1001 0010 0111 0101 1001 0101 1010 0000=-1837787744
原因:
-
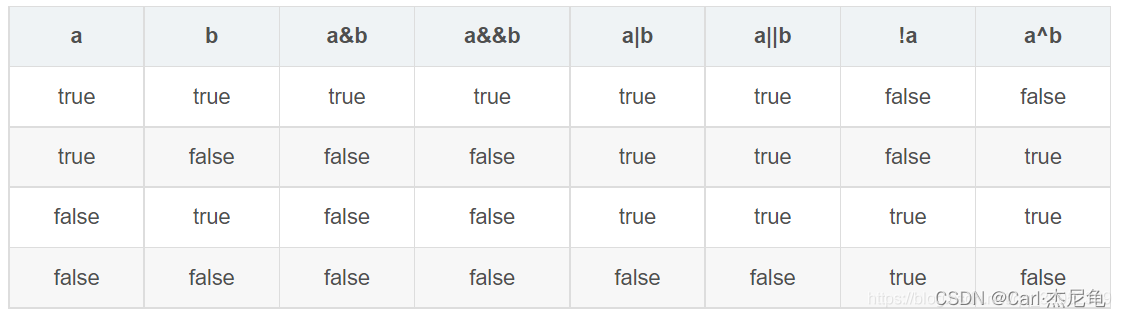
异或的原因是
&、|逻辑运算结果都偏向于true或false,只有^才能让hash值更加均匀的散列
-
hashCode无符号右移16位的原因是
hashCode是用于作为数组的下标,下标值很少会大于低16位的值
添加元素的过程
-
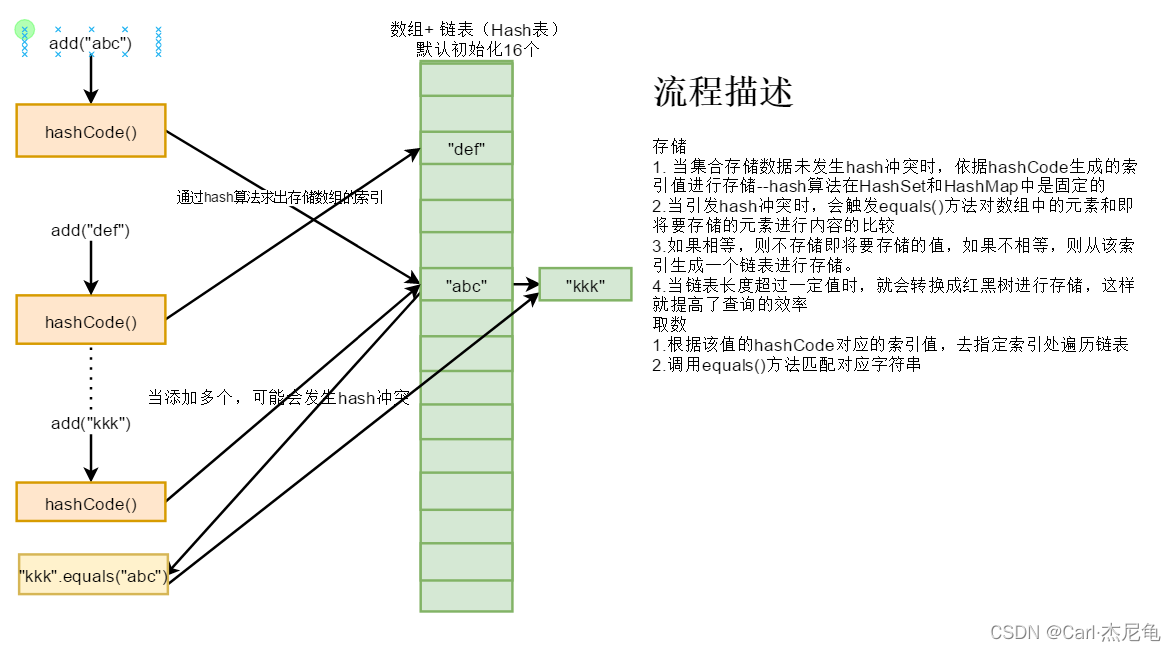
向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值
-
此哈希值相继通过计算获取到HashSet底层Hash表存放的索引位置,判断在hash表上是否已经存在元素
-
如果此位置上无其他元素,则元素a直接添加
-
如果此位置上有其他元素b(或多个元素),则比较元素a和元素b的hash值
-
如果hash值相同,则进一步调用元素a所在类的equals()方法
-
如果equals()方法返回true,则元素a无法添加
-
如果equals()方法返回false,则元素a成功添加
-
-
-
模拟HashSet存储的代码:
package com.carl.javaadvanced.collection_demo;
import org.junit.Test;
import java.util.HashSet;
public class SetTest {
@Test
public void SetTest(){
//模拟HashMap的底层
//Node数组也叫做表
Node[] table=new Node[16];
//创建节点
Node john=new Node("john",null);
table[2]=john;
Node jack = new Node("jack", null);
john.next=jack;
System.out.println("table=" + table);
}
}
class Node{
Object item;//存放数据
Node next;//指向下一个节点
public Node(Object item, Node next) {
this.item = item;
this.next = next;
}
}
注意事项:
-
如果要把某个类保存到HashSet集合中,必须重写hashCode()和equals()方法
-
hashCode()方法和equals()方法应该尽量保证存储内容相同的两个对象,通过equals()返回true,hashCode()返回值相等–用作equals比较标准的实例变量应该也要用于hash值的计算
-
尽量避免hash冲突,因为一旦Hash值存在两个以上,就会遍历链表或红黑树,一旦发生的是遍历,性能就会急剧下降
-
hashCode()是计算的值,不是随机的,一个对象多次调用hashCode返回的hash值应该是一致的
下表是不同变量类型的hashCode计算方式,深度理解为什么hashCode()方法在IDEA或Eclipse中重写后是这样的
| 实例变量类型 | hashCode计算方式 |
|---|---|
| boolean | f?0:1 |
| 整数类型(byte、short、int) | (int)f |
| char | (int)f |
| long | int(f^f>>>32) |
| float | Float.floatToIntBits(f) |
| double | long l=Double.doubleToLongBits(f) (int)(l^l>>>32) |
| 引用类型 | f.hashCode()//一般是地址值 |
为了避免偶然相等性:
-
第一步是扩大误差范围,将误差范围扩大,误差可能性也就降低了
-
第二步是仅仅相加并不能降低偶然相等的可能性,采用乘以质数的方式,因为质数分解因子只有本身和1,乘以质数直接就降低了偶然性
源码分析:

















 43万+
43万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











