







序言
距离YOLOv3的发布已经快两年了,虽然在这两年里面虽然涌现了很多优秀的框架,但是毫无疑问的是,在工业界目标检测中,YOLOv3仍然很受CV爱好者们的喜爱,尽管新框架检测精度和速度不断提高,但是多数情况下是为了刷榜,并没有像YOLOv3一样普遍受众,这也是为什么距离发布已经快过去两年了,YOLOv3还是这么受爱好者们青睐的原因,不过近日作者在推特上宣布不再从事深度学习视觉领域的研究,这也意味着也许YOLO就此绝代,不会在有YOLOv4出现了,说实话还是很令人痛心的。
本篇文章主要是给出了一些YOLOv3的优化策略,当然不一定很全面,只是提供一下优化思路而已。
才说到yolo要绝版,结果v4又出来了,直接去看v4吧。。。各种tricks满天飞,大型优化调参现场,这篇文章随便看看就好了…
一、YOLOv3的不足之处
要优化改进一个模型,就必须要了解到它不足的地方,YOLOv3虽然说是一款速度兼精度已经非常优秀的框架,但是还是免不了存在以下问题:
- 召回率不足;
- 定位不够准确;
- 模型在实际应用场景中的达不到实时性要求。
针对以上存在的问题,提出以下优化思路:更轻量级更快和更高的准确率和recall
二、优化策略
1. 更轻量级更快:
1.1 更换YOLOv3的backbone
YOLOv3默认的backbone是darknet53,虽然darknet53在精度和速度上相比于ResNet-101和ResNet-152要好,但是在一些特定的场景下,对于精度要求没这么高的、目标数目少等情况下,我们可以更换更轻量级的网络来作为它的backbone,可以尝试使用V2版本的darknet19或者Mobilenet系列和ShuffleNet系列的轻量级网络来满足模型的实时性要求。
1.2 提升训练速度
在训练YOLOv3时,通常我们会选择使用预训练好的模型进行迁移学习,这在微调的时候就存在一个问题,训练一开始就结束了。因为预训练模型在Imagenet上训练过了,设置的迭代次数应该是远大于cfg中的max_batch或者其他参数,所以刚开始训练就达到了截停的条件。如果不做fine-tuning,没有好的初始化又很难训练出好的模型。这时候可以选择只提取前面固定层的参数作为初始化权重,例如使用darknet19作为backbone,只提取darknet19的前面的1~39层参数;得到的darkent19.conv.40可以作为修改的yolov3-darknet19网络的初始化模型。
/darknet partial cfg/darknet19.cfg darknet19.weights darknet19.conv.40 40
如果想对要对模型进一步调整的话还可以尝试模型压缩、剪枝、蒸馏等技术。
2. 提升准确率和召回率:
2.1 对anchor进行重新聚类
在YOLOv3中,默认的anchor是从COCO数据集上聚类而来,然而在实际需求中,不一定适用,可以针对任务的不同,重新聚类新的anchor;
2.2 调整损失函数
YOLO是作为单阶段的检测器,免不了要面对类别不不平衡的问题,在V3的原文中说到作者使用了focal loss后mAP反而下降了两个百分点,但是并不证明focal loss在YOLOv3中是无用的,也很有可能是作者用错了地方,参考知乎上大神们的讨论关于YOLOv3使用focal loss mAP反而下降,还可以尝试其他的平衡类别不平衡的函数GHM(focal loss的改进版)等;
2.3 加入Gaussian loss
其实就是Gaussian YOLOv3这篇文章,文章的大致思路是对预测框的不确定性加入了Gaussian模型进行建模。在通过置信度筛选完目标区域后,对预测框进行回归,这时候只能通过NMS来筛选预测框,并没有确切的指标来衡量筛选后的预测框是否准确,作者通过引入Gaussian模型,可以对预测框的不确定性指进行衡量,在精度上有着非常不错的提升;
2.4 使用GIOU、DIOU代替IOU
这个就不再阐述了,感兴趣的可以去了解三者的差别,网上有很多文章;
2.5 可以使用效率更优的网络作为backbone
例如EfficientNet、HRNet、Res2Net等。
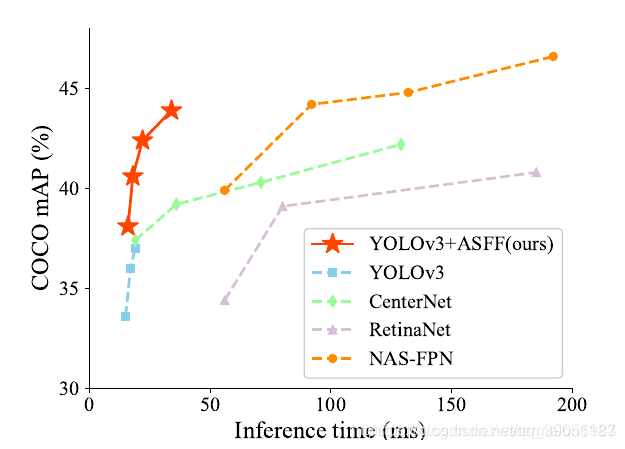
2.6 新的特征融合方式ASFF:
这篇论文才采用了新的特征融合方式,取得了非常大的效果,链接跳转 一种新的特征融合的方式ASFF 直接贴出效果图,可以说是全方面的提升,训练技巧集大成者,论文思想很简单,实现效果好。
如果有更好的优化方向,可以在评论区留言,一起探讨,有错误的地方,也希望能够指正。

















 4770
4770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









