






1、背景
在初始开发阶段,在查数据库频率不大的情况下,我们采取的方式去直接查库,即简单又能满足需求,在遇到查数据库频率开始频繁的情况下,我们可以使用Java中自带的集合来作为缓存,但缺点就是内存无限制的增长,显然我们无法接受的,所以出现数据淘汰算法,下面列举几种淘汰算法(FIFO、LRU、LFU)。
2、算法解析
2.1 FIFO
2.1.1 简介
First Input First Output,即先进先出。这是一种传统的按执行方法,先进入的指令先完成并引退,跟着才进行第二条指令。放在我们缓存容器中就是,最先进入的缓存最先被淘汰掉。
2.1.2 实现
用FIFO算法实现,伪代码如下:
public class FIFOCache {
private Cache cache;
private int maxCap;
private LinkedList<Object> keyOrders;
public FIFOCache(Cache cache, int maxCap) {
this.cache = cache;
this.maxCap = maxCap;
this.keyOrders = new LinkedList<>();
}
public void putObject(Object key, Object value) {
keyOrders.addLast(key);
if(orders.size() > maxCap) {
Object firstKey = keyOrders.delFirst();
caches.removeObject(firstKey);
}
cache.putObject(key, value);
}
}
FIFO算法对于访问频率高且加入时间早的数据而言,命中率会比较低。想象一下,当我们某个访问频率非常高的数据第一个进入,后续访问访问频率低的数据再来访问会将其挤出。
2.2 LRU
2.2.1 简介
Least recently used,最近最少使用算法。每次访问的数据都是放在队首,队列满了就淘汰队尾,其实就是淘汰最近最少访问的数据。
2.2.2 思想
LRU算法实现,一般使用 HashMap+doublyLinkedList,或者使用Java现成中的LinkedHashMap。所以这里引申一个问题,为什么需要这两种数据结构?
看一下LRU主要的操作:
- 首先最基本的操作就是能够从里面读数据;
- 能够加入新的数据,新进来的数据就是Least recently used;
- 如果数据已存在,则根据key更新value,并将其设置为Least recently used;
- 如果数据不存在,在新加入数据之前,判断是否空间是否已满,若是,则把旧数据找到并删除;
需要一个快速查找数据的结构,那么非HashMap莫属,时间复杂度为O(1) ,其余的数据结构也是可以达到目的,例如Array,Queue,Heap,但其时间复杂度O(n)或者O(logn),不及HashMap。而单向链表,当我们在找到节点的时候并希望能够删除该节点的时候,我们可以直接获取next节点,时间复杂度是O(1),但要求prev节点时间复杂度一样,使用的便是双向链表,所以我们使用的是HashMap+doublyLinkedList。那二者之间如何关联,如下图所示:
这里,我们可以通过哈希表的key找到对应链表的节点,如果有相应的节点,就将该节点移动到最前或最后,如果没有相应的节点,就判断是否链表长度是否已满,没有则新增节点到最前或最后与哈希表存储该节点的reference。若有,则删除该节点,并根据哈希表中Key删除reference,再新增新的节点到最前或最后以及哈希表存储该节点reference。
2.2.3 实现
以下用Java自带的LinkedHashMap实现LRU算法:

public class LRUCache {
private Cache cache;
private int maxCap;
private LinkedHashMap<Object> keyOrders;
private Object earliestKey;
public LRUCache(Cache cache, int maxCap) {
this.cache = cache;
this.maxCap = maxCap;
keyOrders = new LinkedHashMap<Object,Object>(maxCap, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<Object, Object> earliest) {
boolean fullFlag = size() > maxCap;
if(fullFlag) {
earliestKey = earliest.getKey();
}
return fullFlag;
}
};
}
public void putObject(Object key, Object value) {
cache.putObject(key, value);
keyOrders.put(key, key);
if (earliestKey != null) {
cache.removeObject(earliestKey);
earliestKey = null;
}
}
@Override
public Object getObject(Object key) {
keyOrders.get(key);
return cache.getObject(key);
}
}
LRU算法避免了FIFO的问题,每次访问都会把数据放在我们的队尾,如果需要淘汰数据的话,就淘汰队首即可。当存在热点数据的时候,LRU的效率是很高的,但这存在一个问题,会存在偶然性使命中率急剧下降的情况。举个例子,在60秒内,某个热点数据在前59秒高频率访问,但在第60秒没有被访问,而是其余大量不同低频数据来访问,当队列满的时候,就会造成该热点数据被淘汰。
2.3 LFU
2.3.1 简介
Least frequently used,最近最少频率使用算法,该算法对LRU算法进行了优化,利用额外的空间记录每个数据的使用频率,然后选出频率最低进行淘汰。根据频率淘汰,不会出现大量进进来的挤压掉老的,如果在数据的访问的模式不随时间变化时候,LFU将会提供绝佳的命中率,这样就避免了LRU不能处理时间段的问题。
2.3.2 思想
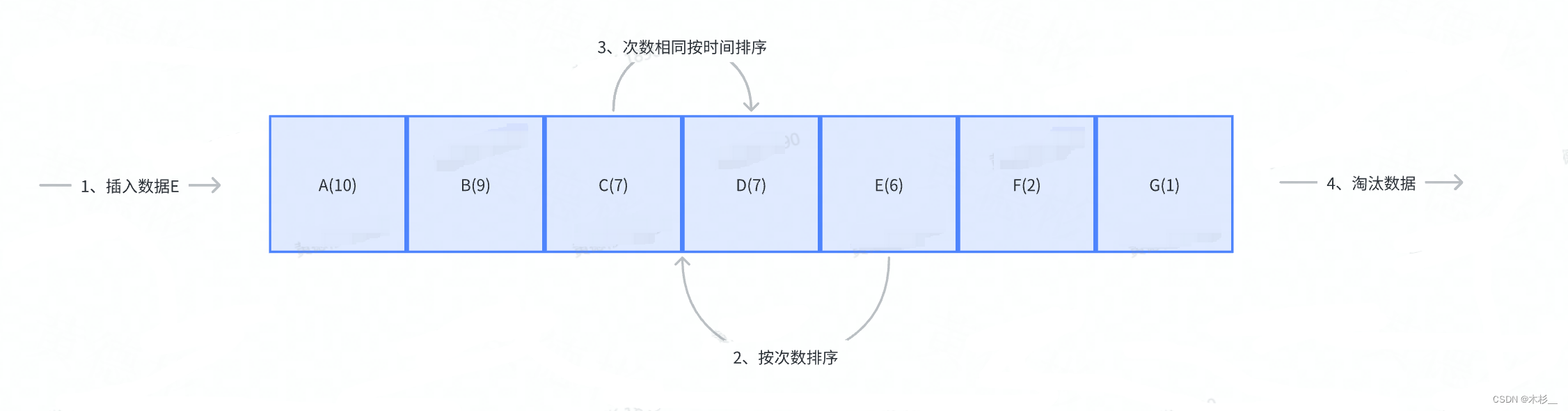
实现逻辑:
- 在链表开始插入数据,每插入一次就计数一次。
- 按照次数重新排列链表。
- 如果次数相同,那么就按照插入的时间,淘汰链表队尾数据。
2.3.3 实现
基于上面的设计思路,其实主要就是比较数据被访问次数,所以在节点我们需要维护访问时间和访问次数这两个属性,伪代码如下:
public class LFUCache {
private int maxCap;
private Map<Object, Node> caches;
@Data
public static class Node{
private Object key;
private Object value;
private long time;
private int count;
}
public LFUCache(int maxCap){
this.maxCap= maxCap;
this.map = new LinkedHashMap<>();
}
public void put(K key, V value) {
Node node = caches.get(key);
if (node == null) {
if (caches.size() >= maxCap) {
// 删除count最少的key,如果count一样,就删除最早时间的
}
// 创建新节点
} else {
// 次数+1并更新时间
}
sort();
}
public Object get(Object key) {
Node node = caches.get(key);
if (node != null) {
// 次数+1并更新时间
sort();
return node.value;
}
return null;
}
}
如果数据随着时间推移而访问次数越少的话,新进来的数据会被快速淘汰,因为刚刚进来的频率最低,之前老缓存的频率太高。并且它需要额外空间维护频率这个属性,如果建立一个HashMap维护这个属性,当数据量大的情况下,那么这个HashMap也会十分巨大。
3、缓存算法的使用
上面说了常用的淘汰算法,那么我们常用的缓存用了哪些淘汰算法及优化操作呢?
3.1 Guava Cache
3.1.1 简介
Guava是Google团队开源的一款 Java 核心增强库,包含集合、并发原语、缓存、IO、反射等工具箱,性能和稳定性上都有保障,应用十分广泛。Guava Cache是基于LRU算法实现,那它的实现原理是如何?
3.1.2 实现思想
从上面使用HashMap+doublyLinkedList可以实现LRU算法来淘汰缓存数据,而Guava也是借鉴HashMap+双向链表的思想,但这里存在线程不安全问题,所以Guava Cache也借鉴了基于JKD1.7版本实现的ConcurrentHashMap分段锁的思想,也就可以总结Guava Cache是通过ConcurrentHashMap+双向链表实现的。
3.1.3 具体实现
上面说了,Guava Cache采用类似于分段锁的思想实现,其中一共涉及到三个Queue其中包括:AccessQueue和WriteQueue,以及RecentQueue。AccessQueue和WriteQueue就是双向链表;而RecentQueue才是真正的Queue,它就是CocurrentLinkedQueue。
-
先来说一下AccessQueue和WriteQueue。
在使用的时候,可以配置concurrencyLevel这个参数,即设置分为多少Segment,而每个Segment又维护着两个队列,这两个队列都是Gauva Cache实现的双向链表,并且是线程不安全,而要操作这两个队列,就必须获取Segment的Lock的场景下才能使用。
![[图片]](https://img-blog.csdnimg.cn/b196b7905e854c9c8fed688009e968c3.png)
其中accessQueue维护读队列,用来我们进行访问时间的淘汰,如果当这个Segment超过最大容量,例如我配置concurrencyLevel为4,而size是100,那么每个Segment超过25就会将accessQueue队列的第一个元素进行淘汰。writeQueue维护写队列,队头代表着写得早的数据,队尾代表写得晚的数据,使用方法如下:
private static LoadingCache<String, RateLimiter> limitCaches = CacheBuilder.newBuilder()
.maximumSize(100)
.expireAfterWrite(12, TimeUnit.HOURS) //
.build(new CacheLoader<String, RateLimiter>() {
@Override
public RateLimiter load(String key) throws Exception {
double perSecond = LxRateLimitUtil.getCacheKeyPerSecond(key);
return RateLimiter.create(perSecond);
}
});
-
那RecencyQueue队列是什么?
上面我们已经提到到过,AccessQueue被设计成了线程不安全,每次访问的时候都需要获取Segment中的Lock,然后才能够安全地将数据移动AccessQueue的前面去,显然不可取,会导致性能低下。因此Guava Cache为了确保性能,引入RecencyQueue这个同步队列,在读取数据的时候,将所有被访问的数据都添加到RecencyQueue中,接着在能获取锁的情况下,再把RecencyQueue中的数据移动到AccessQueue中。
![[图片]](https://img-blog.csdnimg.cn/fd7447c8354d43ae9f9aa589aae78671.png)
所以Guava Cache通过RecentQueue和AccessQueue的结合就实现了在确保get的高性能的场景下还能记录对数据的访问,从而实现LRU算法。
3.2.2 实现思想
上面算法解析说了,LFU算法能带来最佳的缓存命中率,但有两个缺点,其一是需要给每条记录维护频率信息,每次访问都要更新,这是一笔开销。其二是最先频繁访问的数据可能会一直占用着缓存,后期访问频繁的数据则无法被命中。相比之下,LRU并不需要维护昂贵的缓存频率信息,同时数据能够随时间变化的反应出来。所以集两家之长的W-TinyLFU算法就被发明了,TinyLFU维护了近期访问记录的频率信息,作为一个过滤器,当新数据来访问时,只有满足TinyLFU要求的记录才可以被插入缓存。那它是如何解决上面两个问题呢?
3.2.3 具体实现
W-TinyLFU主要干了两件事:
1、采用 Count–Min Sketch 算法降低频率信息带来的内存消耗;
2、维护一个PK机制保障新上的热点数据能够缓存。
在W-TinyLFU中使用Count-Min Sketch(布隆过滤器的一种变种)记录数据的访问频率,如下图:
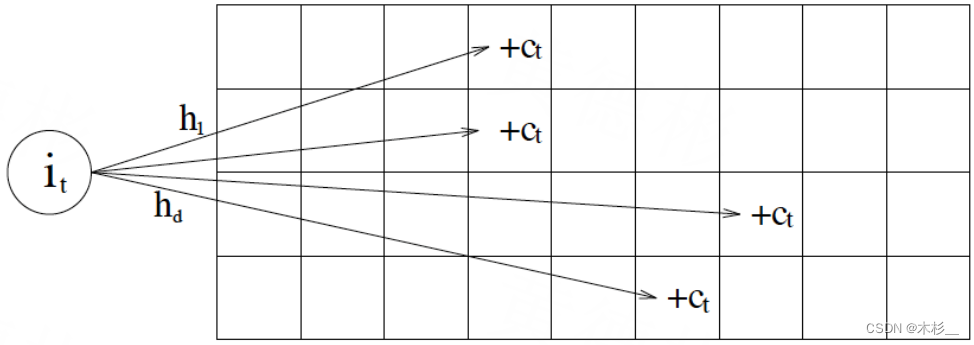
存储数据时,对key进行多次 hash 函数运算后,二维数组不同位置存储频率,读取某个key的访问次数时,会比较所有位置上的频率值,取最小值返回。对于所有key的访问频率之和有个最大值,当达到最大值时,会进行reset即对各个缓存key的频率除以2,这个算法可以较好的适应时间段的访问频率。
而Caffeine 实际实现的时候是用一维 long 型数组,每个 long 型数字切分成16份,每份4bit,默认15次为最高访问频率,每个key实际 hash 了四次,落在不同 long 型数字的16份中某个位置。
那Caffeine是如何淘汰数据的?在Caffeine中有三个记录引用的LRU队列:
- Eden队列:这个队列中记录的是新到的数据,防止突发流量由于之前没有访问频率,而导致被淘汰。比如有一部新剧上线,在最开始其实是没有访问频率的,防止上线之后被其他缓存淘汰出去。
- Probation队列:如果该队列满了,取队首和队尾进行 PK,队首数据是最先进入队列的,称为受害者,队尾的数据称为攻击者,比较两者频率大小,大胜小汰。
- Protected队列:在这个队列中,暂时不会被淘汰,但如果Probation队列没有数据了或者Protected数据满了,你也将会被面临淘汰的尴尬局面。当然想要变成这个队列,需要在Probation访问一次之后,就会提升为Protected队列。
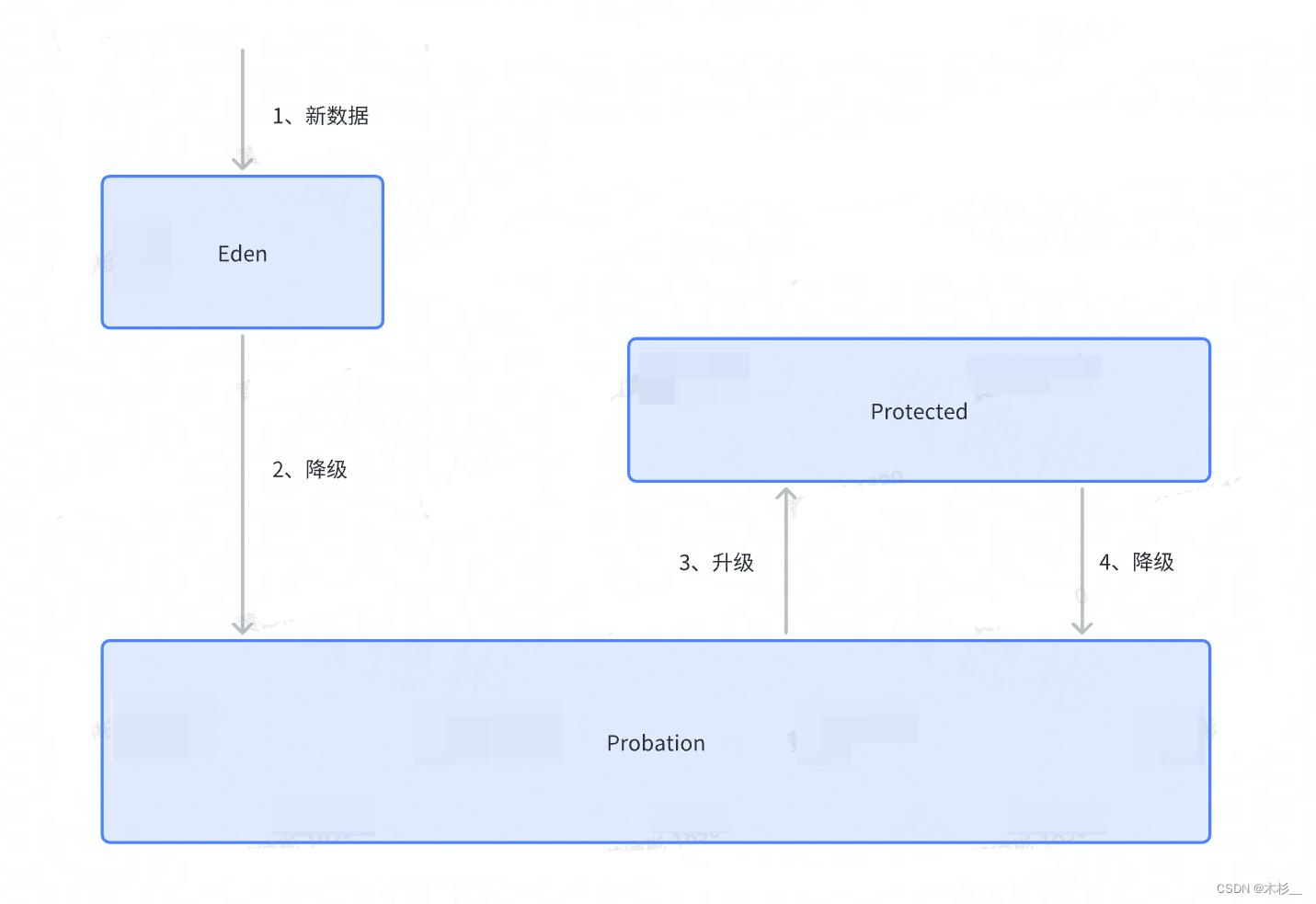
总的来说,通过 reset 衰减,避免历史热点数据由于频率值比较高一直淘汰不掉,并且通过对访问队列分成三段,这样避免了新加入的热点数据早早地被淘汰掉。
3.3 Redis
众所周知,Redis作为知名内存型NOSQL,极大提升了程序访问数据的性能,高性能互联网应用里,几乎都能看到Redis的身影。同本地Cache一样,也有着其相应的淘汰策略。
3.3.1 删除策略
在介绍淘汰策略之前,先介绍下Redis的过期删除策略,Redis对于过期的Key,有两种删除策略:
- 定期删除
将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定期遍历这个字典来删除到期的 key。默认是每隔 100ms就随机抽取N(N可通过配置设置)个过期时间的key,检查其是否过期,如果过期就删除。 - 惰性删除
在访问这个key的时候,redis对key的过期时间进行检查,如果过期了就立即删除,不返回任何数据。
定期删除可能会导致很多过期key到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,即当你主动去查过期的key时,如果发现key过期了,就立即进行删除,不返回任何东西。
3.3.2 淘汰策略
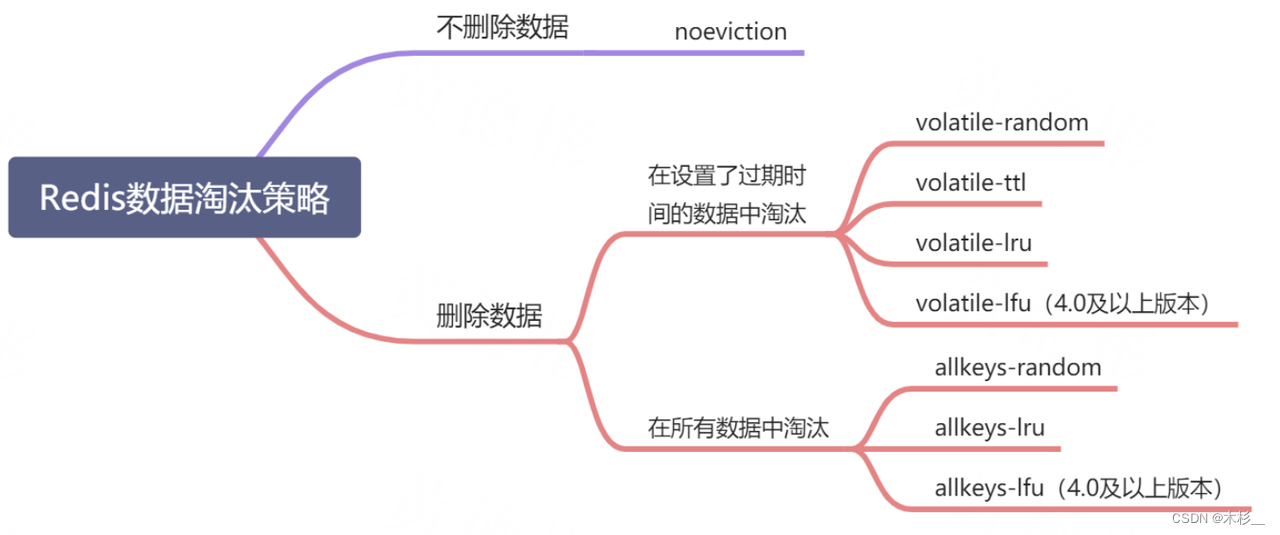
从Redis 4.0开始,共有以下8种数据淘汰机制,通过在Redis配置文件中设置 Redis 最大使用内存大小,当数据超过设置的内存大小时,就会执行相应的淘汰策略。
- noeviction:默认策略,不淘汰数据;大部分写命令都将返回错误。
- volatile-lru:从设置了过期时间的数据中根据 LRU 算法挑选数据淘汰。
- volatile-random:从设置了过期时间的数据中随机挑选数据淘汰。
- volatile-ttl:从设置了过期时间的数据中,挑选越早过期的数据进行删除。
- volatile-lfu:从设置了过期时间的数据中根据 LFU 算法挑选数据淘汰(4.0及以上版本可用)。
- allkeys-random:从所有数据中随机挑选数据淘汰。
- allkeys-lru:从所有数据中根据 LRU 算法挑选数据淘汰。
- allkeys-lfu:从所有数据中根据 LFU 算法挑选数据淘汰(4.0及以上版本可用)。
我们可以看到,除 noeviction 比较特殊外,allkeys 开头的将从所有数据中进行淘汰,volatile 开头的将从设置了过期时间的数据中进行淘汰,用一张图概括就是:
如何配置相应的淘汰策略呢?
1、优先使用allkeys-lru策略,充分发挥LRU算法的优势。
2、有明显冷热数据区分,就用allkeys-lru,否则建议使用allkeys-random。
3、如果存在某些业务配置数据,可以使用 volatile-lru策略,并且不给这些数据设置过期时间,这样数据就一直不会被删除。
总体来说策略的选择需要考虑的是,在筛选数据的时候,是否会筛选出被再次访问的数据,这直接决定了缓存效率的高低。
3.3.3 淘汰算法
Redis算法有多种:lru、random、ttl、lfu ,其中Redis采用的是近似LRU算法,被做了简化。
- 近似LRU算法实现
Redis维护一个全局24位时钟(每个一段时间会更新),每个Key对象内部也维护着一个24位时钟,这是用来对比该Key过期与否。与常规的LRU实现并不相同,常规LRU会准确的淘汰掉队头的元素,但是Redis的LRU并不维护队列,只是根据配置的策略要么从所有的key中随机选择N个(N可以配置)要么从所有的设置了过期时间的key中选出N个键,然后再从这N个键中选出最久没有使用的一个key进行淘汰。 - 近似LRU算法优势
- 性能问题,随机采样N个Key,不用为所有数据维护一个大链表。
- 内存占用问题,抽样排序可以有效降低内存的占用。
- 实际效果基本相等。
- 在近似情况下提供可自配置的取样率来提升精准(配置参数 maxmemory-samples),设置的越大,越接近真实的LRU算法。
4、缓存设计和使用
缓存分为进程内缓存和分布式缓存两种。
4.1 解决的问题
- CPU占用。
- 数据库IO占用。
4.2 进程内缓存
4.2.1 简介
进程内缓存有很多种,例如ConcurrentHashMap,LRUMap,Ehcache,Guava Cache,Caffeine等,通过上下比较可知,Caffeine不管在命中率还是读写性能都比较好的,所以这里推荐使用Caffeine,而且也有丰富的API。
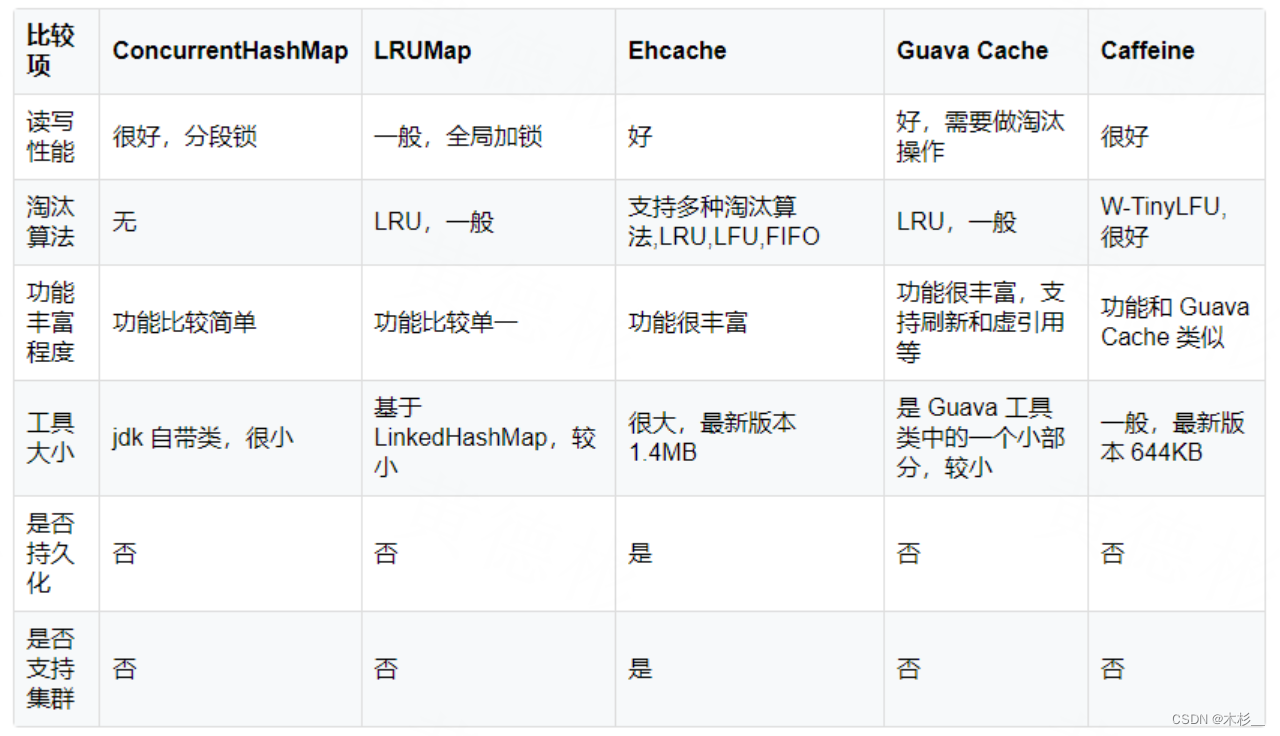
4.2.2 使用
首先我们知道,进程内缓存受内存大小的限制,并且如果是多服务的话,某个服务本地缓存更新,其它服务更是无法知道其更新了,所以进程内缓存一般使用在什么地方:
- 数据量不大且更新频率低。
- 如果数据有一定的更新频率,可以将进程内缓存的过期时间/刷新时间设置为较短。
用法如下:
- 引入依赖。
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
- 开启缓存支持。
@EnableCaching // 使用@EnableCaching注解让Spring Boot开启对缓存的支持
@SpringBootApplication
public class BootstrapApplication {
public static void main(String[] args) {
SpringApplication.run(BootstrapApplication.class, args);
}
}
- 新建Caffeine。
private static final Cache<String, PagingResponse<TopicsVo>> INDEX_CACHE = Caffeine.newBuilder()
.expireAfterAccess(3, TimeUnit.SECONDS)
.initialCapacity(10)
.maximumSize(1000)
.build();
- Caffeine使用。
// 缓存存储
INDEX_CACHE.put(key, value);
// 缓存获取
INDEX_CACHE.getIfPresent(key);
- 如需使用refreshAfterWrite配置还必须指定一个CacheLoader,如下:
// 在配置文件中,配置refreshAfterWrite=10s
@Bean
public CacheLoader<Object, Object> cacheLoader() {
CacheLoader<Object, Object> cacheLoader = new CacheLoader<Object, Object>() {
@Override
public Object load(Object key) throws Exception {
return null;
}
@Override
public Object reload(Object key, Object oldValue) throws Exception {
// dosomething
return oldValue;
}
};
return cacheLoader;
}
Caffeine配置说明:
- initialCapacity=[integer]: 初始的缓存空间大小
- maximumSize=[long]: 缓存的最大条数
- maximumWeight=[long]: 缓存的最大权重
- expireAfterAccess=[duration]: 最后一次写入或访问后经过固定时间过期
- expireAfterWrite=[duration]: 最后一次写入后经过固定时间过期
- refreshAfterWrite=[duration]: 创建缓存或者最近一次更新缓存后经过固定的时间间隔,刷新缓存
- weakKeys: 打开key的弱引用
- weakValues:打开value的弱引用
- softValues:打开value的软引用
- recordStats:开发统计功能
PS: - expireAfterWrite和expireAfterAccess同事存在时,以expireAfterWrite为准。
- maximumSize和maximumWeight不可以同时使用
- weakValues和softValues不可以同时使用
4.2.3 实践效果
4.3 分布式缓存
4.3.1 简介
分布式缓存也有以下几种:MemCache,Redis,Tair。
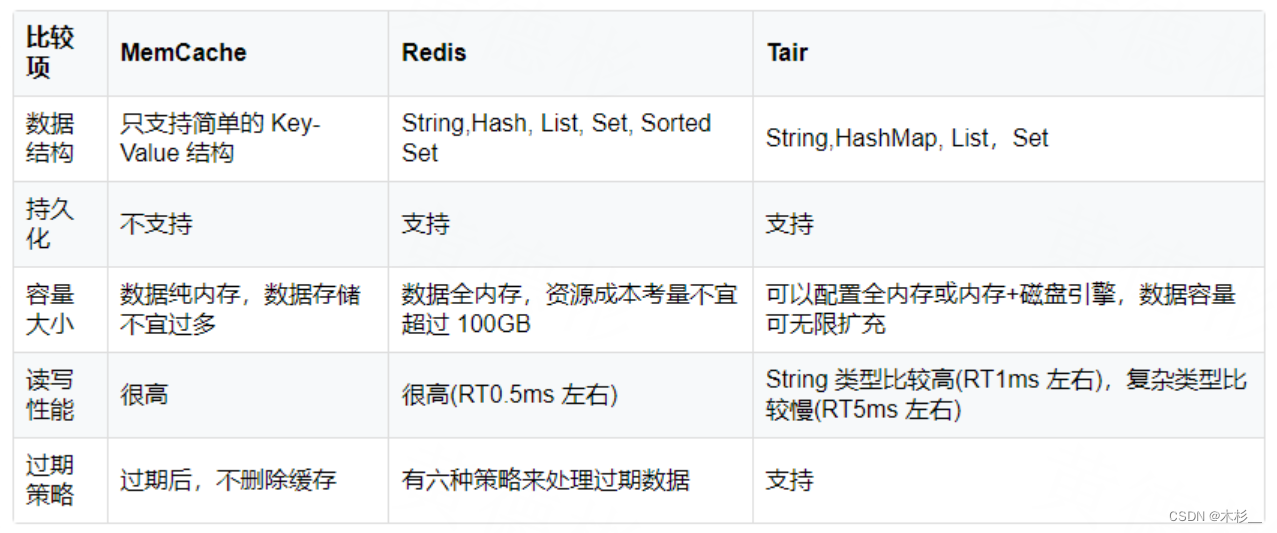
如果服务对延迟比较敏感,Map/Set数据也比较多的话,比较适合Redis,其支持丰富的数据结构,读写性能很高,但是数据全内存,要考虑资源成本,支持持久化。所以一般我们使用Redis。
Redis缓存的做法、效果与Caffeine类似。
4.4 多级缓存
既然有了Redis缓存,为何还会需要Caffeine、Guava这些的进程内缓存呢?有两个原因:
- Redis服务如果挂了,那么请求就会直接打到DB上,很容易造成缓存雪崩。
- 访问Redis会有一定的网络I/O以及序列化反序列化,虽然性能很高但是不会比本地方法快,可以将最热的数据存放在本地,以便进一步加快访问速度。
如下图所示,即是我们最常见的做法。
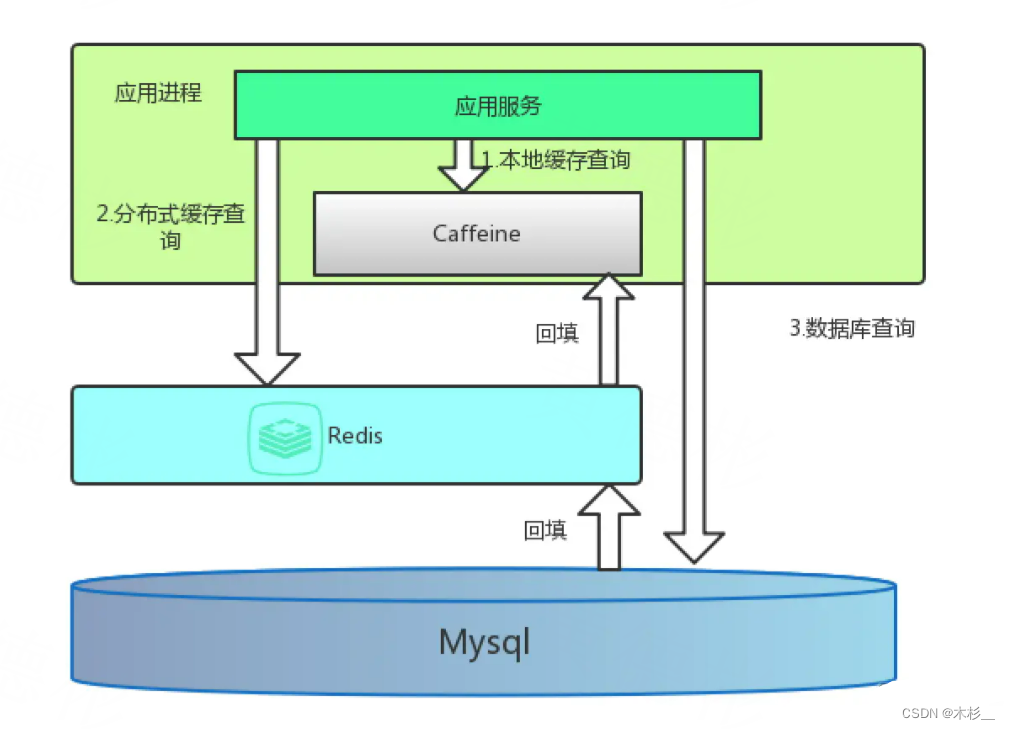
用Caffeine作为一级缓存,Redis作为二级缓存。
但是,如果部署多台机器,对于Caffeine的缓存,有数据更新,只能删除更新数据的那台机器上的缓存,其他机器只能通过超时来过期缓存,对于Redis的缓存更新,其他机器立马可见,但是也必须要设置超时时间,其时间比Caffeine的过期长。如果对数据实时性有很高要求,那么就需要在上图进一步优化:
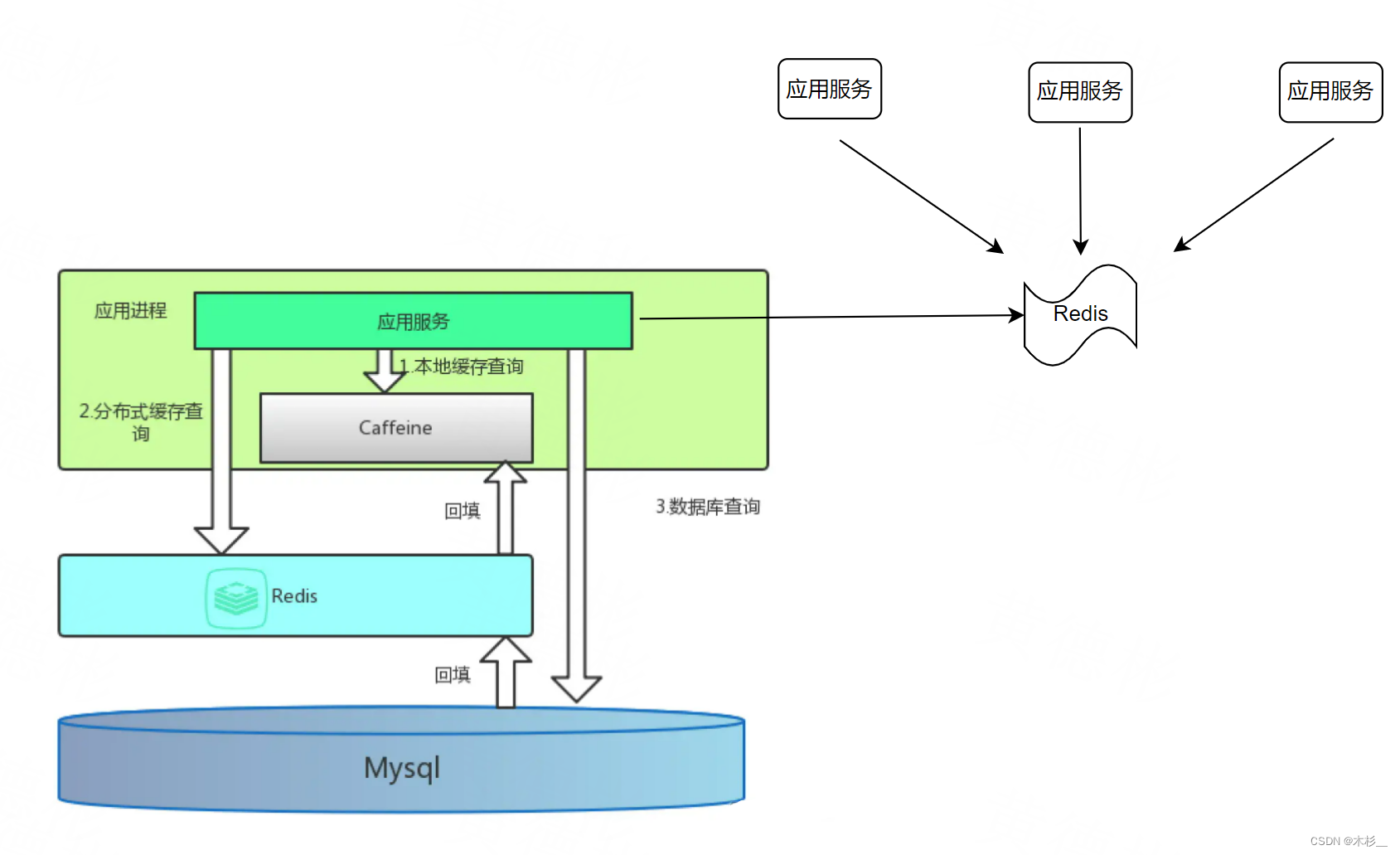
通过Redis的pub/sub,可以通知其他进程缓存对此缓存进行删除。如果Redis挂了或者订阅机制不靠谱,依靠超时设定,依然可以做兜底处理。
5、总结
每一需求的实现,有时候并不是使用的思路、技术不对,而是因为有其它更好的。多对比,就多收获。
















 521
521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









