







前言
系列文章传送门:.
【数据结构系列 1】数组入门详解
【数据结构系列 2】栈入门详解
【数据结构系列 3】队列入门详解
【数据结构系列 4】链表入门详解
【数据结构系列 5】哈希表入门详解
【数据结构系列 6】树入门详解
一、链表简介
1、链表基础概念
链表的定义
逻辑结构上一个挨一个的数据,在实际存储时,并没有像顺序表那样也相互紧挨着。恰恰相反,数据随机分布在内存中的各个位置,这种存储结构称为线性表的链式存储。
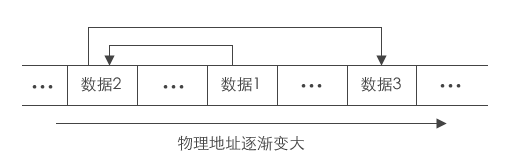
由于分散存储,为了能够体现出数据元素之间的逻辑关系,每个数据元素在存储的同时,要配备一个指针,用于指向它的直接后继元素,即每一个数据元素都指向下一个数据元素(最后一个指向NULL(空))。

链表中数据元素的构成
每个元素本身由两部分组成:
- 本身的信息,称为“数据域”;
- 指向直接后继的指针,称为“指针域”。

这两部分信息组成数据元素的存储结构,称之为“结点”。n个结点通过指针域相互链接,组成一个链表。
typedef struct List{
int elem;//代表数据域
struct List* next;//代表指针域,指向直接后继元素
}List;
头结点、首元结点和头指针
| 概念 | 描述 |
|---|---|
| 头结点 | 有时,在链表的第一个结点之前会额外增设一个结点,此结点被称为头结点 |
| 首元结点 | 链表中第一个元素所在的结点,它是头结点后边的第一个结点 |
| 头指针 | 永远指向链表中第一个结点的位置 |
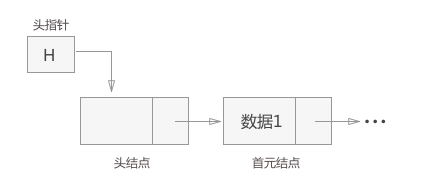
头结点和头指针的区别:头指针是一个指针,头指针指向链表的头结点或者首元结点;头结点是一个实际存在的结点,它包含有数据域和指针域。两者在程序中的直接体现就是:头指针只声明而没有分配存储空间,头结点进行了声明并分配了一个结点的实际物理内存
2、链表的分类
| 链表类型 | 定义 |
|---|---|
| 单链表 | 最基础的链表,每个节点含有数据域和指向下一个节点的指针两个元素 |
| 双链表 | 每个节点含有数据域、指向上一个节点的指针和指向下一个节点的指针三个元素,可以双向遍历 |
| 循环链表 | 首尾相接形成一个环的链表 |
根据有无头结点、是否循环、是否双链表可以组合得到2^3=8种类型的链表。
3、链表的操作(增删改查)
单链表的创建
//节点结构定义
typedef struct List{
int elem;//代表数据域
struct List* next;//代表指针域,指向直接后继元素
}list;
//创建一个链表
list* InitList() {
list* p = new list;//创建一个头结点
list* temp = p;//声明一个指针指向头结点,用于遍历链表
//生成链表
for (int i = 0; i < 5; i++) {
list *q = new list;
q->elem = i;
q->next = NULL;
temp->next = q;
temp = temp->next;
}
return p;
}
单链表的插入
链表中插入头结点,根据插入位置的不同,分为3种:
- 插入到链表的首部,也就是头结点和首元结点中间;
- 插入到链表中间的某个位置;
- 插入到链表最末端;
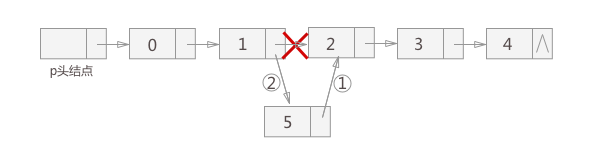
虽然插入位置有区别,都使用相同的插入手法。分为两步,如图所示:
- 将新结点的next指针指向插入位置后的结点;
- 将插入位置前的结点的next指针指向插入结点
/*
* @brief 链表头指针、插入元素以及插入位置
* @return 链表头指针
*/
list * InsertElem(list * p, int elem, int add) {
list * temp = p;
//首先找到要插入位置的上一个结点
for (int i = 1; i < add; i++) {
if (temp == NULL) {
cout << "插入位置无效" << endl;
return p;
}
temp = temp->next;
}
//创建插入结点c
list * c = new list;
c->elem = elem;
//向链表中插入结点
c->next = temp->next;
temp->next = c;
return p;
}
单链表的删除
当需要从链表中删除某个结点时,需要进行两步操作:
- 将结点从链表中摘下来;
- 手动释放掉结点,回收被结点占用的内存空间;
- 注意:一定要将节点占用的空间释放,不然在堆区申请的空间将会造成内存泄漏
/*
* @brief 链表头指针、删除位置
* @return 链表头指针
*/
list * DelElem(list * p, int add) {
list * temp = p;
//temp指向被删除结点的上一个结点
for (int i = 1; i < add; i++) {
temp = temp->next;
}
list * del = temp->next;//单独设置一个指针指向被删除结点,以防丢失
temp->next = temp->next->next;//删除某个结点的方法就是更改前一个结点的指针域
delete del;//手动释放该结点,防止内存泄漏
return p;
}
单链表的修改
/*
* @brief 链表头指针、修改位置
* @return 链表头指针
*/
list * ModifyElem(list * p, int elem, int mod) {
list * temp = p;
//temp指向被修改结点
for (int i = 0; i < mod; i++) {
temp = temp->next;
}
temp->elem = elem;
return p;
}
单链表的查找
/*
* @brief 链表头指针、查找元素
* @return 查找结果
*/
list * FindElem(list * p, int elem) {
list * temp = p;
//temp指向被修改结点
while(temp->next) {
temp = temp->next;
//返回元素所在节点的指针
if(temp->elem == elem)
return temp;
}
//查找失败返回null
return null;
}
二、链表的应用
1、c++库list的应用
初学者更多的是要理解数据结构,了解底层实现是为了更好地学习,这一点是很关键的。而在日常工作应用中并不会每次都去手动实现一个链表的结构,更多的是直接使用封装好的库函数和类。这一点其实就像是调用了一个api一样,你使用它的特性而不用关注它的实现,能够提高日常工作的效率。
list是一种序列式容器。list容器完成的功能实际上和数据结构中的双向链表是极其相似的,list中的数据元素是通过链表指针串连成逻辑意义上的线性表,也就是list也具有链表的主要优点,即:在链表的任一位置进行元素的插入、删除操作都是快速的。
一个list使用的小例子:
#include <iostream>
#include <list>
using namespace std;
int main()
{
//list的构造
list<int> l1;
list<int> l2(2, 0);
l1.push_back(1);
l1.push_back(2);
l2.push_back(3);
//list的合并输出
l1.merge(l2);
for (auto iter = l1.begin(); iter != l1.end(); iter++)
{
cout << *iter << " ";
}
cout << endl ;
//判空
if (l2.empty())
{
cout << "l2 变为空 !!";
}
cout << endl ;
system("pause");
return 0;
}
-----------------------------------------------------------------------------------------------------------------------------------------------------
❤️❤️❤️ 如果本文对你有所帮助,请不要忘了点赞、关注、收藏一键三连哦!!! ❤️❤️❤️
-----------------------------------------------------------------------------------------------------------------------------------------------------















 4792
4792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









