






一、源代码
1.话不多说,直接先上源代码
这个代码也是比较齐全的了,由各种各样的函数来实现各种功能,但是,这里并没有使用头节点,也导致需要一个单独的函数InsertHead来弥补这一缺陷。
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
using namespace std;
typedef int DataType;
typedef struct NODE Node;
typedef struct NODE
{
DataType data;
Node* next;
}Node;
typedef Node* Head;
int GetLinkListLength(Head head);
void DestroyLinkList(Head head);
int GetElement(Head head, int n, DataType* data);
int FindElement(Head head, DataType data);
int GetPriorElement(Head head, int n, DataType* data);
int GetNextElement(Head head, int n, DataType* data);
int DeleteFromList(Head* head, int pos);
int InsertToList(Head* head, int pos, DataType data);
int InsertRear(Head* head, DataType data);
int InsertHead(Head* head, DataType data);
void PrintList(Head head);
int GetLinkListLength(Head head)
{
if (head == NULL)
return 0;
int i = 1;
Node* pNode = head;
while (pNode->next)
{
i++;
pNode = pNode->next;
}
return i;
}
void DestroyLinkList(Head head)
{
Node* pnode;
while (head)
{
pnode = head;
head = head->next;
free(pnode);
}
}
int GetElement(Head head, int n, DataType* data)
{
if (n<0 || n>GetLinkListLength(head) - 1)
return 0;
for (int i = 0; i < n; i++)
head = head->next;
*data = head->data;
return 1;
}
int FindElement(Head head, DataType data)
{
int i = 0;
while (head)
{
if (head->data == data)
return i;
head = head->next;
i++;
}
return -1;
}
int GetPriorElement(Head head, int n, DataType* data)
{
if (n<1 || n>GetLinkListLength(head) - 1)
return -1;
for (int i = 0; i < n - 1; i++)
head = head->next;
*data = head->data;
return n - 1;
}
int GetNextElement(Head head, int n, DataType* data)
{
if (n<0 || n>GetLinkListLength(head) - 2)
return -1;
for (int i = 0; i < n+1; i++)
head = head->next;
*data = head->data;
return n + 1;
}
int DeleteFromList(Head* head, int pos)
{
Node* pNode = *head;
int length = GetLinkListLength(*head);
if (pos<0 || pos>length - 1)
return -1;
Node* pDeleteNode=NULL;
if (pos > 0)
{
for (int i = 0; i < pos - 1; i++)
pNode = pNode->next;
pDeleteNode = pNode->next;
pNode->next = pNode->next->next;
}
if (pos == 0)
{
pDeleteNode = *head;
*head = (*head)->next;
}
free(pDeleteNode);
return --length;
}
int InsertToList(Head* head, int pos, DataType data)
{
Node* pnode = *head;
int length = GetLinkListLength(*head);
if (pos<0 || pos>length)
return -1;
if (pos == 0)
return InsertHead(head, data);
if (pos == length - 1)
return InsertRear(head, data);
for (int i = 0; i < pos-1; i++)
pnode = pnode->next;
Node* pNewNode = (Node*)malloc(sizeof(Node));
if (pNewNode == NULL)
return -1;
pNewNode->data = data;
pNewNode->next = pnode->next;
pnode->next = pNewNode;
return ++length;
}
int InsertHead(Head* head, DataType data)
{
Node* pNewNode = (Node*)malloc(sizeof(Node));
if (pNewNode == NULL)
return -1;
pNewNode->data = data;
pNewNode->next = (*head);
*head = pNewNode;
return GetLinkListLength(*head);
}
int InsertRear(Head* head, DataType data)
{
Node* pNewNode = (Node*)malloc(sizeof(Node));
if (pNewNode == NULL)
return -1;
pNewNode->data = data;
if (*head == NULL)
{
*head = pNewNode;
pNewNode->next = NULL;
return 1;
}
Node* pNode = *head;
while (pNode->next)
{
pNode = pNode->next;
}
pNode->next = pNewNode;
pNewNode->next = NULL;
return GetLinkListLength(*head);
}
void PrintList(Head head)
{
int n = 0;
while (head)
{
cout << "第" << n << "项元素为" << head->data << '\n';
head = head->next;
n++;
}
}
int main()
{
Head head = NULL;
for (int i = 0; i < 5; i++)
{
InsertToList(&head, i, i + 1);
}
PrintList(head);
cout << "插入99后的表长:" << InsertToList(&head, 2, 99)<<'\n';
PrintList(head);
cout << "删除第四项:" <<DeleteFromList(&head,4)<< '\n';
PrintList(head);
DataType data;
if (GetPriorElement(head, 3, &data) != -1)
cout << "前驱" << data<<'\n'<<'\n';
DataType data1;
GetElement(head, 4, &data1);
cout << data1<<endl;
PrintList(head);
cout<<FindElement(head, 99)<<endl;
PrintList(head);
DestroyLinkList(head);
}二、我在学习过程中的疑惑与解答
1.为什么有的函数输入用Head head,而有的用Head* head.
首先,细心的小伙伴会发现有需要改变原有链表的值的时候,用的都是Head* head,(比如:DeleteFromList,InsertToList两个函数,一个是要删除原有链表的一个元素,一个是要插入一个元素),而不需要改变原有链表,而只需要获取该链表的某个信息(如长度,前驱)时,只用Head head,就OK了,这是为什么呢?
对此,我们要明白,函数输入参数的赋值机制,在C语言中,指针是用于存储内存地址的变量。当一个指针给另一个指针赋值时,实际上是复制了内存地址的值,而不是复制了指针本身。因此,赋值后的指针指向与原指针指向同一块内存区域。这意味着,改变被赋值指针的值,会同时影响到赋值指针和原指针,因为它们都指向同一块内存区域。
这两个函数中,一个接受 Head head 作为参数,另一个接受 Head* head 作为参数。这种区别主要源于 C/C++ 中的指针和值传递机制。
- 值传递(Pass by Value): 当函数参数是按值传递的(例如
Head head),函数接收的是参数值的副本。对参数的任何修改都不会影响原始值。这意味着如果你传递一个结构体或对象给这样的函数,函数内部对该结构体或对象的修改不会影响到函数外部的结构体或对象。 - 指针传递(Pass by Reference): 当函数参数是按指针传递的(例如
Head* head),函数接收的是参数的地址。这意味着函数可以通过指针直接修改原始数据。如果你传递一个结构体或对象的指针给这样的函数,函数内部对该结构体或对象的修改会直接影响到函数外部的结构体或对象。
接下来,我们以int DeleteFromList(Head* head, int pos);这一函数为例,来具体说明:
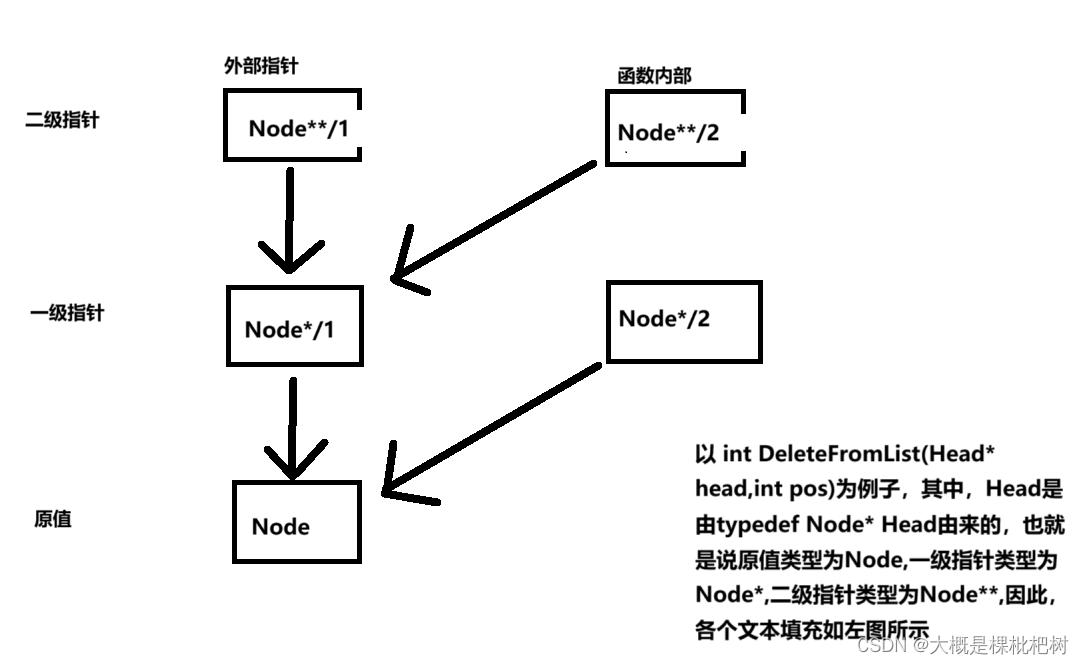
p1
原值对应typedef struct NODE
{
DataType data;
Node* next;
}Node;
里面的data与next,可以用来改变下一个元素。
int DeleteFromList(Head* head, int pos)
{
Node* pNode = *head;
int length = GetLinkListLength(*head);
if (pos<0 || pos>length - 1)
return -1;
Node* pDeleteNode=NULL;
if (pos > 0)
{
for (int i = 0; i < pos - 1; i++)
pNode = pNode->next;
pDeleteNode = pNode->next;
pNode->next = pNode->next->next;
}
if (pos == 0)
{
pDeleteNode = *head;
*head = (*head)->next;
}
free(pDeleteNode);
return --length;
}在这里,根据上图,可以得出一个直观的结论,原指针的指针可以使原指针贯通函数内外(通俗意义上来讲,是在函数内可以改变原指针,而不受局部变量的限制)
在上述代码中,我们首先定义了一个pNode=*head,这是为了方便在找要删除的元素的时候进行迭代,而不改变原来链表的头指针。在找到要删除的位置时候,我们使用了这两行代码:
pDeleteNode = pNode->next;
pNode->next = pNode->next->next;
现在就又有小伙伴疑惑了,不是说这个赋值是复制的值吗,为什么这里又能够改变原来的链表了?我们发现,这里pNode是属于上图中的Node*/2的,尽管位置和Node*/1不一样,但是指针指向是和它一样的啊,所以pNode就可以控制原值,从而达到删去元素的目的。
再看下面pos==0的情况,即删去链表的头指针,这里的head是属于Node**/2,所以*head就是属于Node*/1,所以也可以控制原值,从而达到删去元素的目的。
总的来说,如果这个int DeleteFromList(Head* head, int pos);函数,输入的是Head head,那么就无法控制Node*/1这个外部指针,也就没法达到删除元素的目的!
祝大家期末考的全会,蒙的都对!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









