






数据预处理
本文的实验采用的是Voice Bank的数据集,其中训练集大约包含11000条语音。上一篇文章中提到模型的输入是语音数据的短时傅里叶变换(幅值、相位),包含四个维度,分别是[batch, channel, fft_dim, time],其中channel=2,即幅值和相位。需要注意的是,time这个维度也是固定的,可以设置,实验当中设置为4s。
def make_loader(scp_file_name, batch_size, num_workers=12, processer=Processer()):
dataset = TimeDataset(scp_file_name, processer=processer)
loader = tud.DataLoader(dataset,
batch_size=batch_size,
num_workers=num_workers,
collate_fn=collate_fn,
shuffle=False,
drop_last=False
)
return loader, dataset上述代码是对输入数据集的预处理过程,TimeDataset()这一方法根据预设的time step将所有语音数据划分成等长的数据,采用多进程处理。具体处理过程在worker函数当中:
def worker(target_list, result_list, start, end, segement_length, sample_rate):
for item in target_list[start:end]:
duration = item['duration']
length = int(duration*sample_rate)
if length < segement_length:
sample_index = -1
if length * 2 < segement_length:
continue
result_list.append([item, -1])
else:
sample_index = 0
while sample_index + segement_length < length:
#当长度大于segment_length的时候,将其按照4s的间隔分段,但item名还是一致的
result_list.append(
[item, sample_index])
sample_index += segement_length
if sample_index <= length:
result_list.append([
item,
int(length - segement_length),
])这里学习一下python当中的multiprocessing。multiprocessing包是Python中的多进程管理包,多进程相比于多线程,其拥有独立的堆栈空间和数据段,而线程的数据段是共享的。
创建一个进程采用Process()类
multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
#target为函数名,args是传入的参数,以tuple的形式。进程间不共享数据,所以进程无法直接引用其他进程的数据,代码中采用的是Manger模块来实现进程间的数据共享。
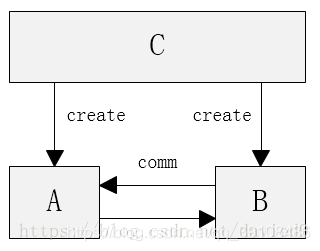
(图转自网络)Manger共享数据的形式。利用顶层C创建一个 Manager,由 Manager 提供数据池接受、分发数据,从而完成两个进程之间的通信。代码中采用self.index = mgr.list(),顶层数据池C为一个list,代码中即result_list,多个进程可以并行地将noisy-clean对append到这个list当中,从而提高预处理的速度。
else: #此处省略条件
for idx in range(num_threads):
if idx == num_threads-1:
end = len(wav_list)
else:
end = (idx+1)*stride
p = mp.Process(
target=worker,
args=(
wav_list,
index,
idx*stride,
end,
segement_length,
sample_rate
)
)
p.start()
pc_list.append(p)
for p in pc_list:
p.join()然而比较尴尬的是,我测试了一下创建多个进程(4)与单个进程的运行时间(I7-8700)分别为8.7s和3.1s。一个比较可能的原因是并行处理不足以弥补创建销毁进程的开销所消耗的时间。
接下来是通过pytorch的DataLoader将数据加载到模型当中,之前的TimeDataset类是继承pytorch的Dataset类实现的,Dataset里包含一个接口方法__getitem__必须重写,__getitem__可以让方法接受一个list参数列表,迭代执行。__len__方法提供dataset的大小。
通过DataLoader实例化的对象,可以使用len()、enumerate()等方法,获取inputs和labels,输入至模型即可。model(inputs)的输出即为phasen forward当中return的结果。

















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









