






 本文深入解析PHASEN双流网络结构,探讨其在音频信号处理中的应用。该网络通过幅值流和相位流预测音频信号的幅值和相位,采用卷积操作、频域变换模块及双向LSTM实现高精度音频重建。
本文深入解析PHASEN双流网络结构,探讨其在音频信号处理中的应用。该网络通过幅值流和相位流预测音频信号的幅值和相位,采用卷积操作、频域变换模块及双向LSTM实现高精度音频重建。
PHASEN结构
源码地址:https://github.com/huyanxin/phasen
PHASEN是一个双流网络,其中幅值流和相位流分别专门用于幅值和相位预测。幅值流主要由卷积操作,频域变换模块(FTB,后文介绍)以及双向 LSTM 组成,而相位流为纯卷积网络。强度流的预测结果为幅值掩膜 M,其取值为正的实数,相位流的预测结果是相位谱。
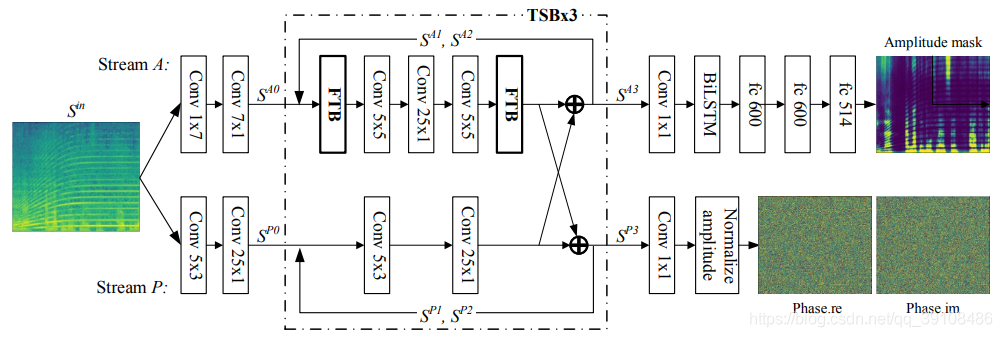
具体细节不一一介绍,直接从每个模块的代码入手。
输入Input
PHASEN的输入是cmp_spec = self.stft(inputs),即计算inputs的幅值与相位,再concat到一起,窗长=400,帧移=100,计算512点FFT。所以输入数据的维度是[batch_size, 257*2, duration],经过unsqueeze之后最终对于幅值A和相位P其维度为[batch_size, 257, duration]。
#init_kernels,返回数据FFT的实部&虚部
def __init__(self, win_len, win_inc, fft_len=None, win_type='hamming', feature_type='real', fix=True):
super(ConvSTFT, self).__init__()
if fft_len == None:
self.fft_len = np.int(2**np.ceil(np.log2(win_len)))
else:
self.fft_len = fft_len
kernel, _ = init_kernels(win_len, win_inc, self.fft_len, win_type)
self.weight = nn.Parameter(kernel, requires_grad=(not fix))
self.feature_type = feature_type
self.stride = win_inc
self.win_len = win_len
self.dim = self.fft_len
def forward(self, inputs):
if inputs.dim() == 2:
inputs = torch.unsqueeze(inputs, 1)
outputs = F.conv1d(inputs, self.weight, stride=self.stride)
if self.feature_type == 'complex':
return outputs
else:
dim = self.dim//2+1
real = outputs[:, :dim, :]
imag = outputs[:, dim:, :]
mags = torch.sqrt(real**2+imag**2)
phase = torch.atan2(imag, real)
return mags, phase*疑问:self.weight = nn.Parameter(kernel, requires_grad=(not fix)) 的作用是什么?
*cmp_spec = torch.unsqueeze(cmp_spec, 1) 是对数据维度进行扩充,给指定位置加上维数为一的维度。
双流结构(TSB)
上图表述的较为明确,整个双流网络重复3次TSB,每个TSB当中的核心是幅值流的频率变换以及幅值、相位的信息交换。
直接贴代码
class TSB(nn.Module):
def __init__(self, input_dim=257, channel_amp=9, channel_phase=8):
super(TSB, self).__init__()
self.ftb1 = FTB(input_dim=input_dim,
in_channel=channel_amp,
)
self.amp_conv1 = nn.Sequential(
nn.Conv2d(channel_amp, channel_amp, kernel_size=(5,5), padding=(2,2)),
nn.BatchNorm2d(channel_amp),
nn.ReLU()
)
self.amp_conv2 = nn.Sequential(
nn.Conv2d(channel_amp, channel_amp, kernel_size=(1,25), padding=(0,12)),
nn.BatchNorm2d(channel_amp),
nn.ReLU()
)
self.amp_conv3 = nn.Sequential(
nn.Conv2d(channel_amp, channel_amp, kernel_size=(5,5), padding=(2,2)),
nn.BatchNorm2d(channel_amp),
nn.ReLU()
)
self.ftb2 = FTB(input_dim=input_dim,
in_channel=channel_amp,
)
self.phase_conv1 = nn.Sequential(
nn.Conv2d(channel_phase, channel_phase, kernel_size=(5,5), padding=(2,2)),
GLayerNorm2d(channel_phase),
)
self.phase_conv2 = nn.Sequential(
nn.Conv2d(channel_phase, channel_phase, kernel_size=(1,25), padding=(0,12)),
GLayerNorm2d(channel_phase),
)
self.p2a_comu = InforComu(channel_phase, channel_amp)
self.a2p_comu = InforComu(channel_amp, channel_phase)频率变换块(FTBs)
沿频率轴的T-F频谱中存在非局部相关性,一个典型的例子就是谐波。然而,简单地堆叠几个卷积核较小的二维卷积层并不能捕捉到这样的全局相关性。FTB就是来解决这个问题的,把它放置在TSB的前端和后端,使TSB输出可以拥有完整的感知域。FTB的核心是变换矩阵的学习,应用于频率轴。如下图所示:
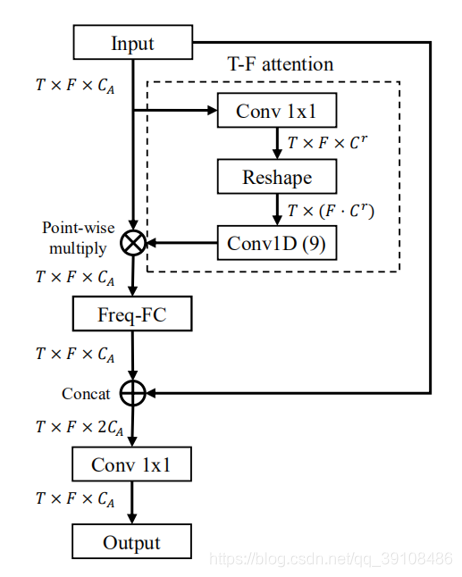
FTB总共包含三个步骤,总结为:
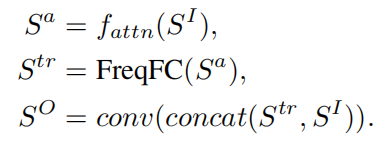
第一个公式描述的是虚线框内的注意力机制模块,对输入进行1维卷积(把通道数变为5)和2维卷积(kernel size = 9)获取一个attention map,然后用户这个map与输入SI进行点乘,得到Sa。
第二个公式描述的是Freq-FC模块,这是FTB中的关键组成部分。它包含一个可训练的频率转换矩阵(FTM),应用于每个时间点特征映射切片。用Xtr表示FTM,Sa(t0)表示每个时间步上的特征切片(F×C),则这个变换可以表示为:
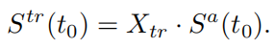
沿时间轴对它们进行叠加,我们可以得到变换的特征图。在Freq-FC之后,Str中的每个T-Fbin将包含来自SA的所有频带的信息。
第三个公式将输入和频率变换后的特征图连接在一起,再经过一个1维卷积,输出通道CA的feature map。
def forward(self, inputs):
'''
inputs should be [Batch, Ca, Dim, Time]
'''
# T-F attention
conv1_out = self.conv1(inputs)
B, C, D, T= conv1_out.size()
reshape1_out = torch.reshape(conv1_out,[B, C*D, T])
conv1d_out = self.conv1d(reshape1_out)
conv1d_out = torch.reshape(conv1d_out, [B, self.in_channel,1,T])
# now is also [B,C,D,T]
att_out = conv1d_out*inputs
# tranpose to [B,C,T,D]
att_out = torch.transpose(att_out, 2, 3)
freqfc_out = self.freq_fc(att_out)
att_out = torch.transpose(freqfc_out, 2, 3)
cat_out = torch.cat([att_out, inputs], 1)
outputs = self.conv2(cat_out)
return outputs代码一目了然,其中,对于freq_fc这里,直接利用一个线性层来模拟,权重就是FTM。
信息交换(Information Communicaiton)
信息交换是双流结构当能够成功的关键思想,没有信息交换就无法有效地对相位进行预测。相反,成功预测相位也可以帮助幅值流更好地预测幅值。实验表明,双向的信息交互对相位预测至关重要。这种设计对于相位估计是至关重要的,因为相位本身没有结构,而且很难估计。然而,利用来自振幅流的信息,相位估计的特征有了明显的改善。信息交换发生在TSB生成输出特征之前。
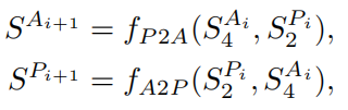
其中f为
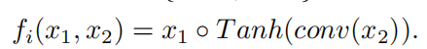
即通过一个卷积操作使相位流和幅值流的维度相等,再点乘得到结果。
输出
幅值流的输出还要经过1维卷积、BiLSTM和三个Dense层,最后估计得到的是幅值的mask!相位流只有一层1维卷积,然后对其实部虚部进行归一化。
整体forward流程代码如下:
spec = self.amp_conv1(cmp_spec)
phase = self.phase_conv1(cmp_spec)
s_spec = spec
s_phase = phase
for idx, layer in enumerate(self.tsbs):
if idx != 0:
spec += s_spec
phase += s_phase
spec, phase = layer(spec, phase)
spec = self.amp_conv2(spec)
spec= torch.transpose(spec, 1,3)
B, T, D, C = spec.size()
spec = torch.reshape(spec, [B, T, D*C])
spec = self.rnn(spec)[0]
spec = self.fcs(spec)
spec = torch.reshape(spec, [B,T,D,1])
spec = torch.transpose(spec, 1,3)
phase = self.phase_conv2(phase)
# norm to 1
phase = phase/(torch.sqrt(
torch.abs(phase[:,0])**2+
torch.abs(phase[:,1])**2)
+1e-8).unsqueeze(1)
est_spec = amp_spec * spec * phase
est_spec = torch.cat([est_spec[:,0], est_spec[:,1]], 1)
est_wav = self.istft(est_spec)
est_wav = torch.squeeze(est_wav, 1)比较关注的是最后几行,首先是对相位的归一化,注意这里相位是双通道的,分别包含实部与虚部,所以后面还有一步是concat,如Convistft当中注释的:
“”"
inputs : [B, N+2, T] (complex spec) or [B, N//2+1, T] (mags)
phase: [B, N//2+1, T] (if not none)
“”"
这里+2就是相位的实部和虚部。
最后再看一下loss的部分。
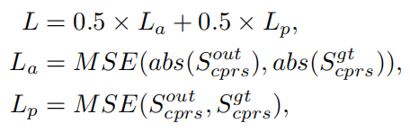
文章中提到,损失分为幅值损失和相位损失,权重均为0.5,在计算损失的时候需要先对能量进行压缩,压缩系数为0.3。可以发现,在计算相位损失的时候,不是单纯使用相位输出信息。而是结合了整个频谱。这样可以帮助网络关注大多数语音信号所在的幅值较高的T-F bin。
b, d, t = est.size()
gth_cspec = self.stft(labels)
est_cspec = est
gth_mag_spec = torch.sqrt(
gth_cspec[:, :self.feat_dim, :]**2
+gth_cspec[:, self.feat_dim:, :]**2
)
est_mag_spec = torch.sqrt(
est_cspec[:, :self.feat_dim, :]**2
+est_cspec[:, self.feat_dim:, :]**2
)
# power compress
gth_cprs_mag_spec = gth_mag_spec**0.3
est_cprs_mag_spec = est_mag_spec**0.3
amp_loss = F.mse_loss(
gth_cprs_mag_spec, est_cprs_mag_spec
)*d
compress_coff = (gth_cprs_mag_spec/(1e-8+gth_mag_spec)).repeat(1,2,1)
phase_loss = F.mse_loss(
gth_cspec*compress_coff,
est_cspec*compress_coff
)*d
all_loss = amp_loss*0.5 + phase_loss*0.5*repeat()相当于一个broadcasting机制,
import torchimport torch.nn.functional as Fimport numpy as np
a = torch.Tensor(128,1,512)
B = a.repeat(1,5,1)
print(B.shape)则torch.Size([128, 5, 512])

















 3871
3871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









