







论文地址:https://arxiv.org/abs/1803.09722
出自港中文,CUHK-SenseTime Joint Lab
一、总体框架描述
1.本篇论文主体思路是提出了一个对抗性的学习框架,如下图1所示:
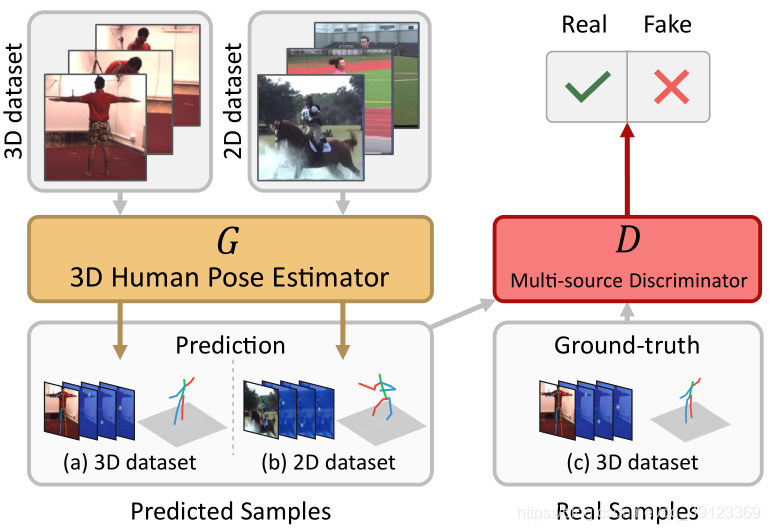
图1主体框架
2.生成器(G)网络由Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach[1] 论文中框架,如图2所示:
The first stage is the 2D pose estimation module, which is the stacked hourglass network [29]. Each stack is in an encoder-decoder structure. It allows for repeated top-down, bottom-up inference across scales with intermediate super-vision attached to each stack. We follow the previous practice to use 256×256 as input resolution. The outputs are P heatmaps for the 2D body joint locations, where P denotes the number of body joints. Each heatmap has size 64 × 64.
The second stage is a depth regression module, which consists of several residual modules taking the 2D body joint heatmaps and intermediate image features generated from the first stage as input. The output is a P × 1 vector denoting the estimated depth for each body joint. A geometric loss is proposed in [1] to allow weakly supervised learning of the depth regression module on images in the wild. We discard the geometric loss for a more concise analysis of the proposed adversarial learning, although our method is complementary to theirs.
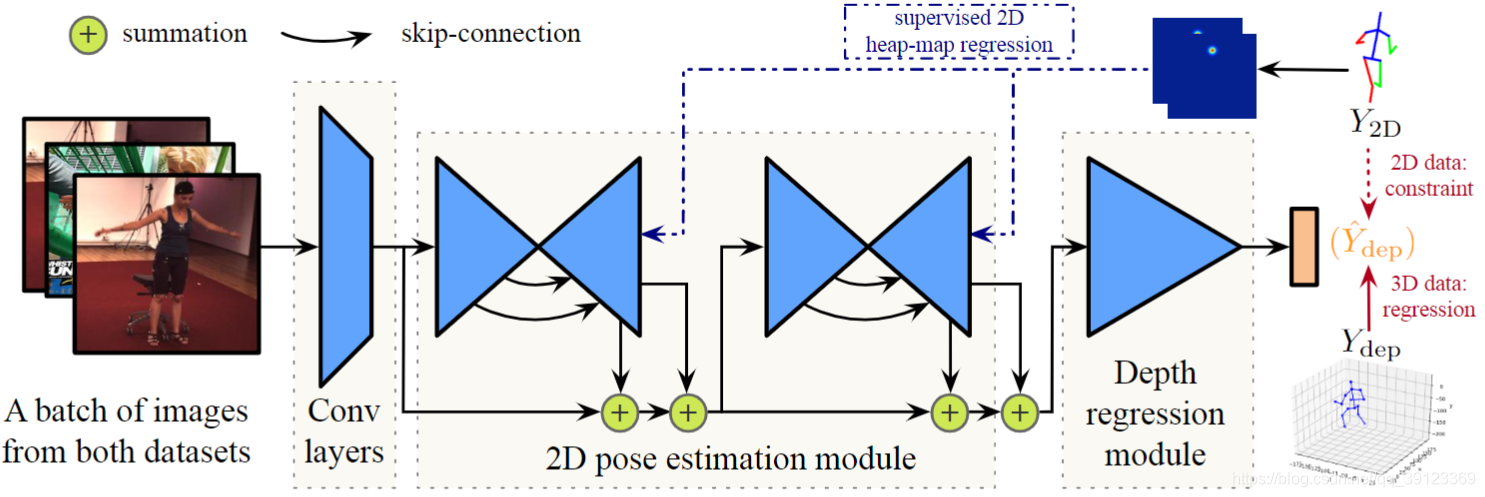
图1 生成器(G)主体框架
3.判别器(G)框架如图3所示,有三个输入源,分别是原始RGB图像、几何描述子(用来约束人体关节的连接、对称性等)、2DHeatmap+Depthmaps。
In the discriminator, there are three information sources: 1)theoriginalimage, 2)thepairwiserelativelocationsanddis-tances, and 3) the heatmaps of 2D locations and the depthsofbodyjoints. Theinformationsourcestaketwokeyfactorsinto consideration: 1) the description on image-pose correspondence; and 2) the human body articulation constraints. To model image-pose correspondence, we treat the original image as the first information source, which provides rich visual and contextual information to reduce ambiguities, as shown in Figure 2(a).
To learn the body articulation constraints, we design a geometric descriptor as the second information source(Figure 2(b)), which is motivated by traditional approachesbased on pictorial structures. It explicitly encodes the pairwise relative locations and distances between body parts, and reduces the complexity to learn domain prior knowledge, e.g., relative limbs length, limits of joint angles, and symmetry of body parts. Details are given in Section 3.2.2 .
Additionally, we also investigate using heatmaps as another information source, which is effective for 2D adversarial pose estimation [7]. It can be considered as a representation of raw body joint locations, from which the network could extract rich and complex geometric relationships within the human body structure. Originally, heatmaps are generated by a 2D Gaussian centered on the body part locations. In order to incorporate the depth information into this representation, we created P depth maps, which have the same resolution as the 2D heatmaps for body joints. Each map is a matrix denoting the depth of a body joint at the corresponding location. The heatmaps and depth maps are further concatenated as the third information source, as shown in Figure 2 (c).
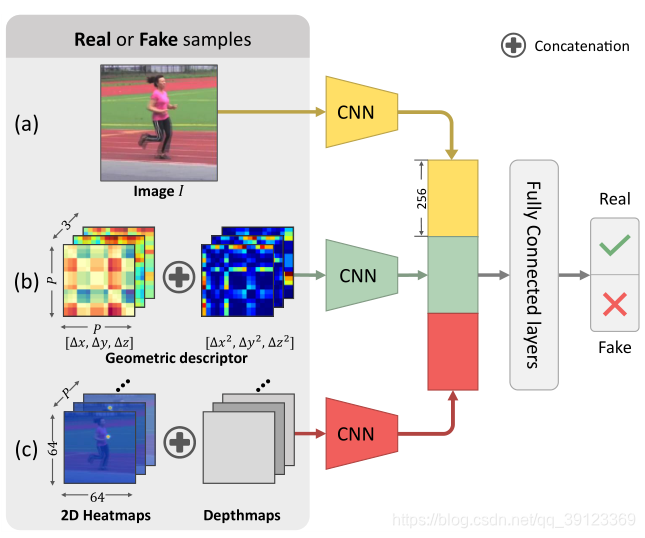
图3 判别器(G)框架
二、训练
生成器训练(G):We first pretrain the 3D pose estimator (i.e. the generator), which consists of the 2D pose estimation moduleand the depth regression module. We follow the standard pipeline [41, 49, 3, 29] and formulate the 2D pose estimation as the heatmap regression problem. The ground-truth heatmap S j for body joint j is generated from a Gaussian centeredat(x j ,y) with varianceΣ, which is set as an identity matrix empirically. Denote the predicted 2D heatmaps and depth as S j and z j respectively. The overall loss for training pose estimator is defined as the squared error.


As in previous works [25, 57], we adopt a pretrained stacked hourglass networks [29] as the 2D pose estimation module. Then the 2D pose module and the depth regression module are jointly fine-tuned with the loss in Eq.(2).
判别器(G)训练


三、结果对比评价
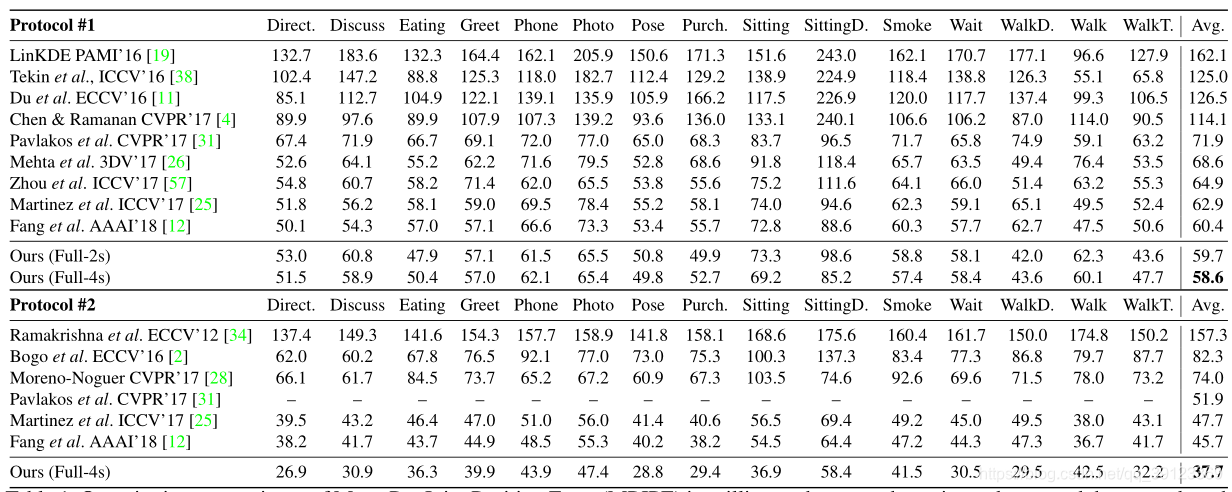
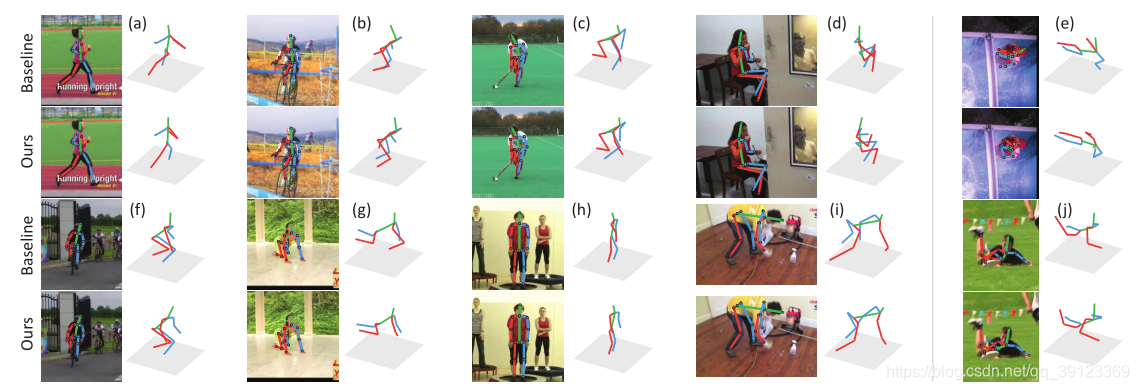
四、框架讨论
本文讨论了框架的设计缘由,并实验验证。想要更加深入的了解框架细节,请阅读原文,原文很有必要精度,写得还是挺清楚的。
该篇文章的源码暂时没有找到,可能是没有公布,如果你找到了麻烦通知一声,谢谢。














 3426
3426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









