






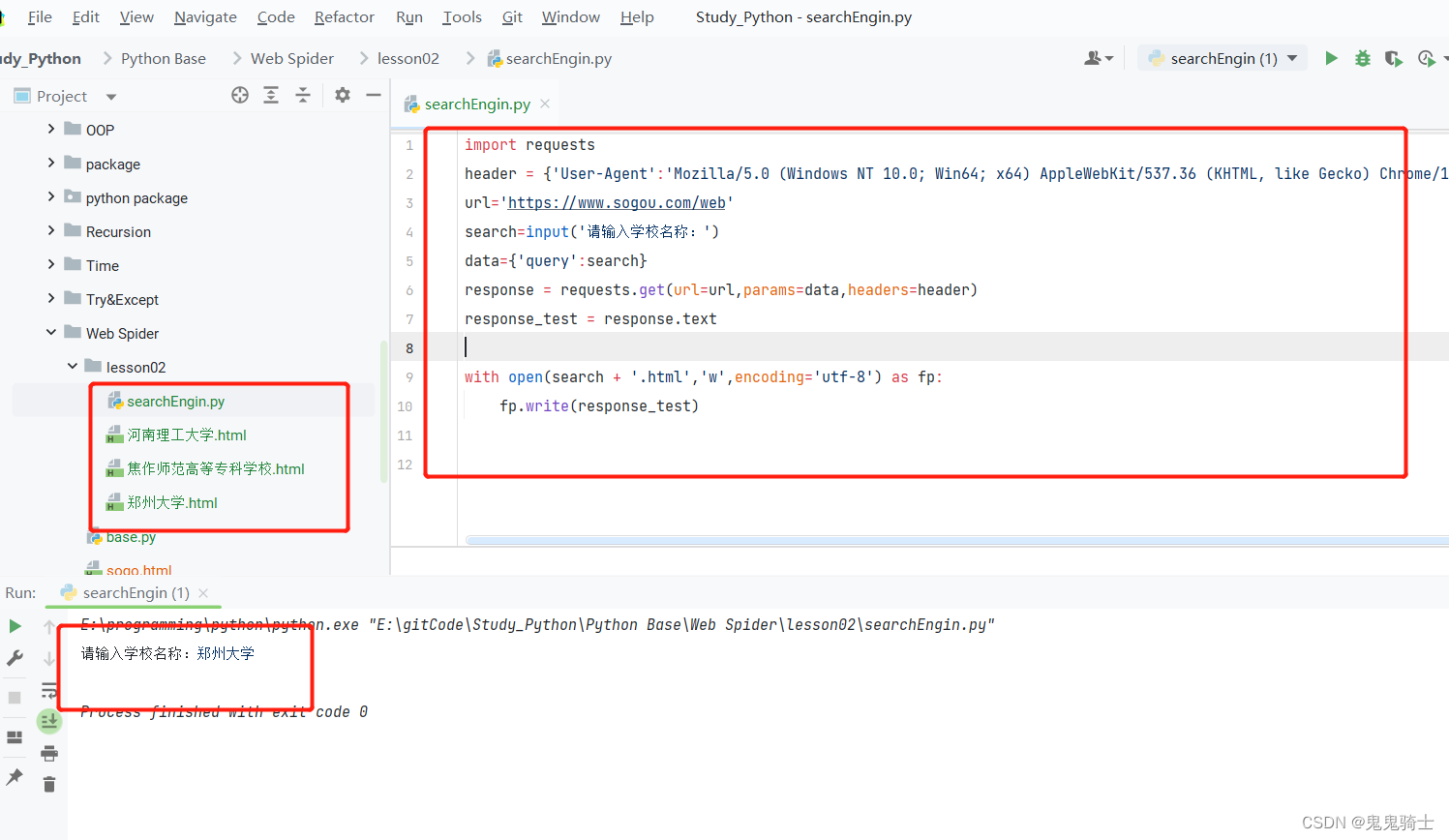
import requests
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50'}
url='https://www.sogou.com/web'
search=input('请输入学校名称')
data={'query':search}
response = requests.get(url=url,params=data,headers=header)
response_test = response.text
with open(search + '.html','w',encoding='utf-8') as fp:
fp.write(response_test)
效果预览
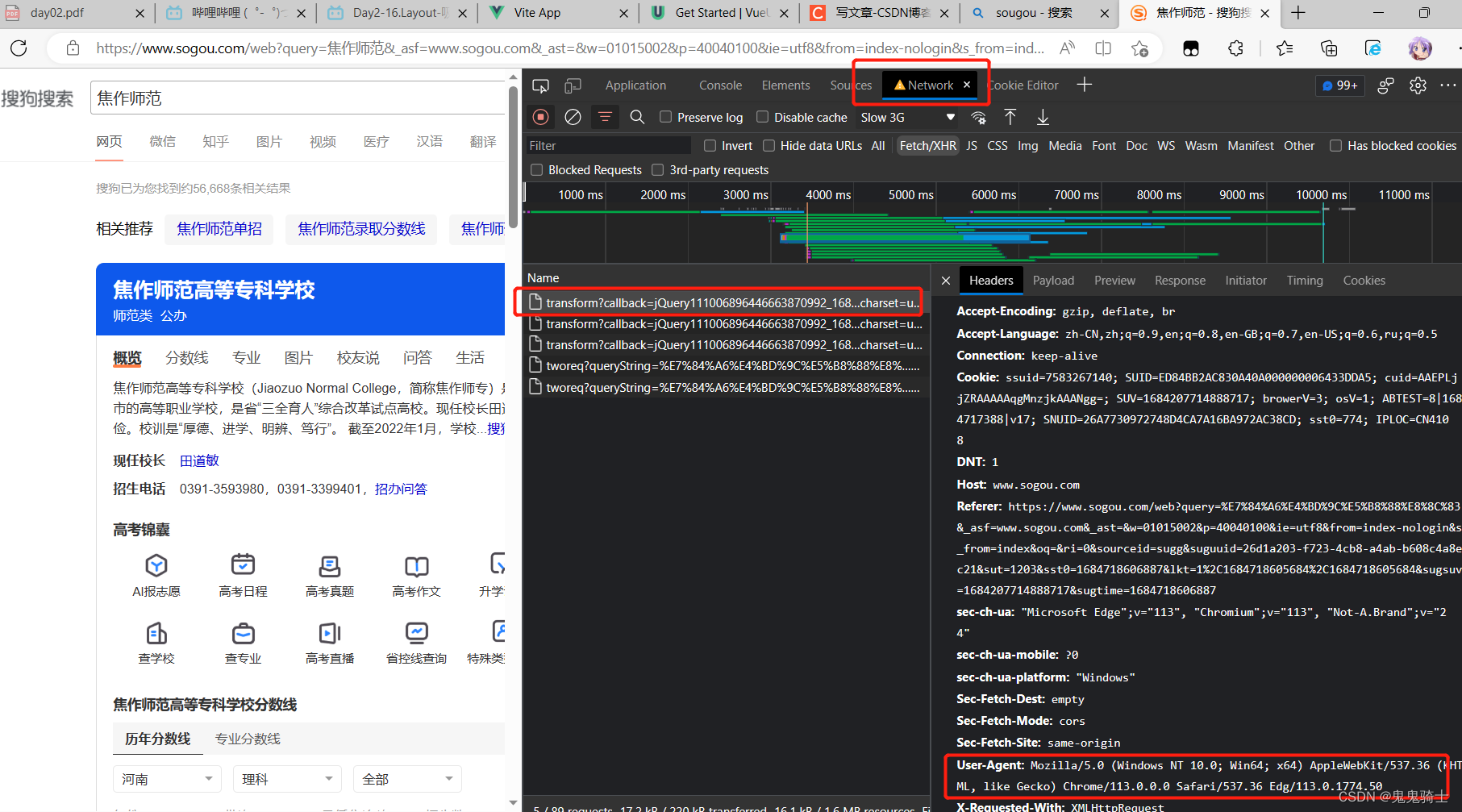
关于user-Agent
获取方法
爬取后如何运行页面
打开文件后在浏览器中运行
















 2801
2801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











