






MapReduce 1.x 架构
MapReduce 1.x 采用 Master/Slave 架构,由全局唯一的 Jobtracker 和多个 TaskTacker 组成,并且在Client中提供一系列的api供编程和管理使用。其中各个组件的作用是:
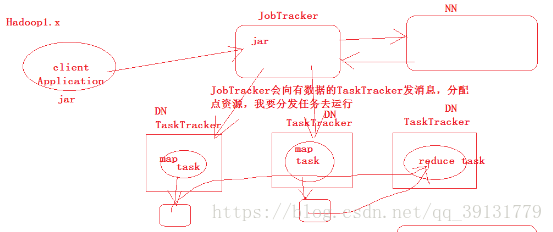
- JobTracker
全局唯一,主要负责集群资源监控和作业调度。但是JobTracker存在单点故障的问题,一旦JobTracker所在的机器宕机,那么集群就无法正常工作。这也是 MapReduce 2.x 所要解决的主要问题之一。 - TaskTracker
TaskTracker负责具体的作业执行工作。TaskTracker需要周期性向JobTracker汇报本节点的心跳信息,包括自身运行情况、作业执行情况等。 - Client
提供api供用户编程调用,将用户编写的MapReduce程序提交到JobTracker中。 - Task
分为两种:Map Task 和 Reduce Task,分别执行Map任务和 Task 任务。MapReduce的输入数据会被切分成多个 split ,一个split会交给一个Map Task去执行。
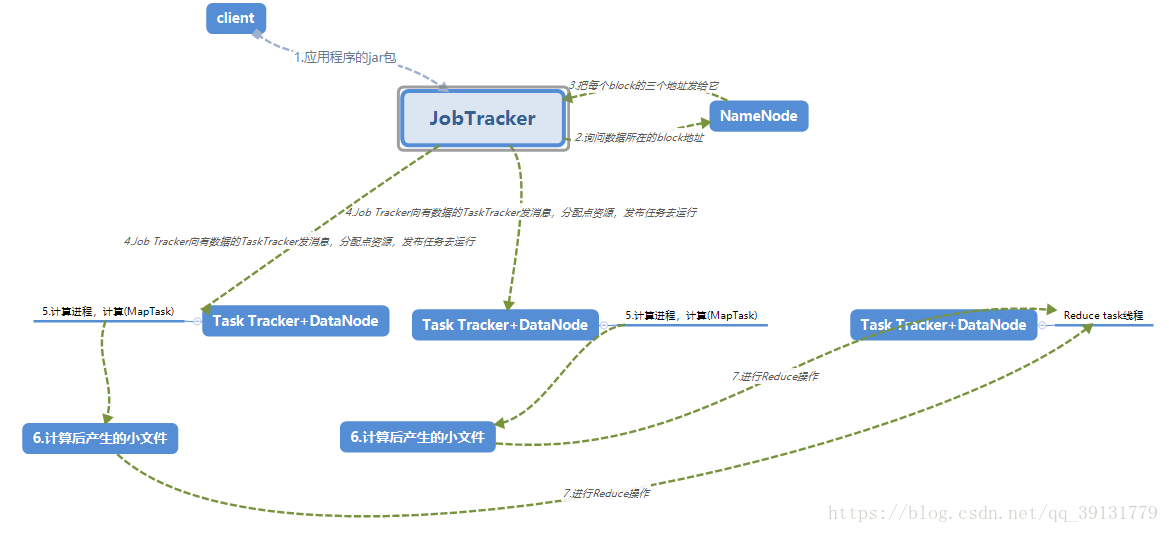
流程:
1.client发送应用程序的jar包给JobTasker
2.询问NameNode数据所在的block地址
3.NameNode把每个block的三个地址发给它
4.Job Tracker向有数据的TaskTracker发消息,分配点资源,发布任务去运行
5.计算进程,计算(MapTask)
6.计算后产生的小文件合并为有分区的内部有序的大文件
7.将所有Map Task产生的相应分区的数据拉入专门处理该分区的Reduce来处理
Redce Task在哪运行比较好?
在某个已经计算好的Map Task上运行好,因为Reduce Task要从Map Task上拉取磁盘文件,会产生网络IO,这样会减少些许网络IO。
但是它存在着资源隔离和抢夺问题:
例如:spark写的应用程序不能运行在此JobTracker,但是它可以自己写一套JobTracker,但是他和Hadoop的JobTracker都是对全部资源进行管理,他们之间是隔离的,当某一方进行计算大量计算时,另一方不知道,也发布计算,这就会出现问题。
即与MapReduce的耦合度太高,如果Spark也要运行到这套框架上,需要自己去实现JobTracker,这个集群上就存在两套资源调度器,资源隔离问题以及资源抢夺问题
总结来讲,它的弊端有
1.JobTracker既是资源调度主节点又是任务调度主节点,负载过重,易发生单点故障。
2.资源管理与计算调度强耦合,其他框架需要重复实现资源管理
3.不同框架对资源不能全局管理,会发生资源抢夺
…
.
MapReduce 2.x 架构(YARN 架构)
在MapReduce 1.x中,全局唯一的JobTracker存在单点故障的问题,并且JobTracker同时负责资源管理和作业调度,节点的工作压力巨大。因此在Hadoop 2.x 中,对原本MapReduce的架构进行了优化改造,使其成为在YARN上面运行的一个计算框架,因此其架构才用YARN的架构。
注意点
ResourceManager仍会出现单点故障,所以我们还会启动一个ResourceManager;ApplicationMaster一旦挂掉,ResourceManager会重新启动ApplicatonMaster,实现高可用;ResourceManager自身的高可用记住zooKeeper实现。
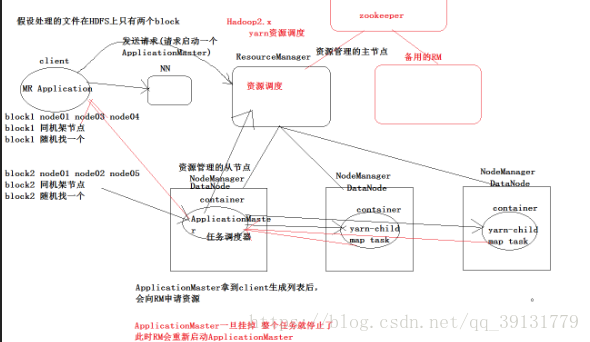
YARN将MapReduce 1.x 中的JobTracker拆分成了两个独立的组件:
- ResourceManager
全局资源管理器,全局唯一。负责整个集群的资源管理和分配,主要由负责资源调度分配的调度器和负责应用程序提交协商的应用程序管理器组成。 - ApplicationMaster
用户提交的每个应用程序 / 作业都会带有一个ApplicationMaster,随便选择一台有数据的节点打开此进程,负责与ResourceManager中的调度器通信获得资源,将得到的任务进行分配,监控作业的执行情况。
除了将JobTracker切分成两个组件之外,YARN中还有两个重要的组件:
-
NodeManager
集群中的每个节点都运行一个NodeManag进程,NodeManager向ResourceManager汇报本节点的各种信息,并且接受来自ApplicationMaster的作业分配信息。 -
Container
是一个容器,专门为进程yarn-child圈出来一部分资源用来执行Map Task线程。
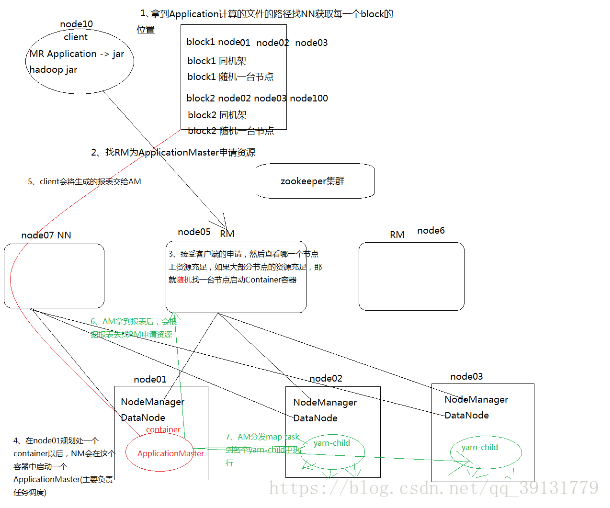
流程
1.client拿到Application计算的文件的路径,去找NN获取每一次block块的位置。会产生一个列表。
2.client向ResourceManager申请资源
请求一个ApplicationMaster(任务调度)
3.ResourceManager接受客户端的申请,然后查看哪一个节点上的资源充足,如果大部分节点的资源充足,那就随便找一台节点启动Container资源。
4.在NodeManager规划处一个container后,NodeManager在这个容器中启动一个ApplicationMaster(任务调度)
5.client将上述列表发送给ApplicationMaster
6.ApplicationMaster拿到报表之后,根据报表找到RM申请资源
7.AM分发map task到各个yarn-child中执行
当ApplicationMaster一旦挂掉,整个任务就停止了,此时ResourceManager会重新启动ApplicationMaster
client端生成的报表例如:
| 块 | 所在位置 | 如果所有位置都没有资源来计算解决方法(本地化的降级) |
|---|---|---|
| block1 | node01、node02、node03 | 1.在他们的同机架上找一台 2.随便一台节点 |
| block2 | node02、node03、node04 | 1.在他们的同机架上找一台 2.随便一台节点 |
上面的解决办法是数据先移动到节点上,在计算














 698
698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









