







背景
文章考虑用不相邻的用户和不连续的访问理解用户行为,利用沿轨迹具有自我关注层的所有登记的相对时空信息,提出了一个时空注意力网络(STAN)做下一兴趣点推荐。
一、需要解决的问题
所有以前的方法都没有有效地考虑非相邻位置和非相邻访问之间的非平凡相关性,且这些模型在建模PIF信息时也存在问题。
二、创新点
1、提出了平衡采样器;
2、用线性插值技术代替空间离散化的分层网格方法,可同时反映连续的空间距离;
三、主要贡献
1、STAN是兴趣点推荐中的第一个模型,明确地结合了时空相关性来学习非相邻位置和非连续访问之间的规律;
2、用线性插值离散化网格空间,恢复空间距离并反映用户的空间偏好,而不仅仅是聚集邻居;
3、为PIF提出了一个双注意力架构。
四、模型
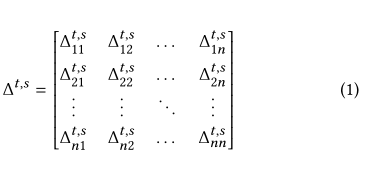
轨迹时空关系矩阵:
两点之间的时间差和地理距离作为直接时空关联信息,i,j两地的时空关系矩阵为:
候选关系矩阵:
轨迹时空关系矩阵是显示信息,考虑候选时空关系矩阵作为隐式信息。将轨迹中每个访问点与候选集中可能的下一点间的时空关联信息用于下一点预测。计算轨迹内每个访问点之间的时空关联:
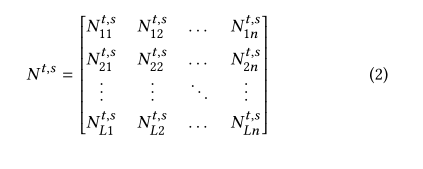
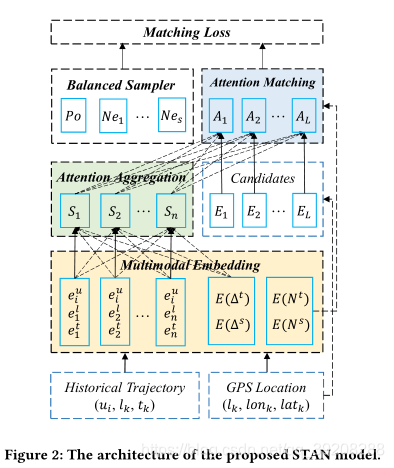
1、模型构成
多模态嵌入模块:multimodal embedding module、self-attention聚集层:self-attention aggregation layer、注意力匹配层:attention matching layer、平衡采样器:balanced sampler
2、模型细节
整个模型分为四个部分。
1)多模态嵌入模块( a multimodal embedding module),学习用户、位置、时间和时空效应的密集表示;
该块由轨迹嵌入层和时空嵌入层两部分组成。
用户轨迹嵌入层:将用户、位置和时间编码成潜在表示;将每个用户序列的embedding表示为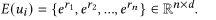
其中:
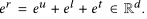
时空嵌入层:
以每小时和每一百米作为基本单位,映射到一个欧氏空间。
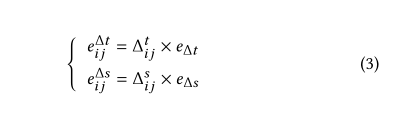
经过求和,可以得到最终的轨迹嵌入 和候选嵌入:
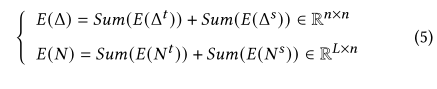
2)自我关注聚集层(a self-attention aggregation layer ),其聚集用户轨迹内的重要相关位置,以更新每次登记的表示;
该模块汇总相关的访问地点,并更新每次访问的表示。将最终轨迹E(u)和时空关系矩阵E(△)通过self-attention层,计算得到新的序列S更新表示。
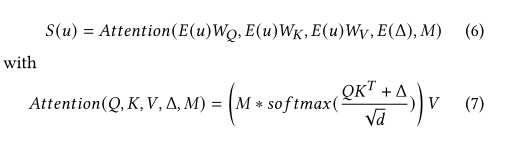
3)注意力匹配层(an attention matching layer),其根据加权登记表示计算最大概率,以计算每个候选位置对于下一个位置的概率;
给定更新的轨迹表示S(u),候选位置表示E(l),候选时空关系矩阵E(N)。计算每个候选位置成为下一位置的概率:

4)平衡采样器(a balanced sampler),使用一个正样本和几个负样本来计算交叉熵损失的平衡采样器。
当正负样本不均衡的时候,优化交叉熵损失不再有效。(这是因为损失权重对推动正确预测的动量影响很小)。本文将交叉熵损失中使用的负样本数量设置为超参数s,称为平衡采样器,用于在训练的每一步随机采样负样本。
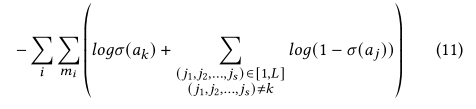
总结
本文提出了一种时空注意力网络STAN,能够有效学习不相邻非连续访问点之间的时空关联,用单位时空离散化替代空间网格,通过双层结构设计考虑用户访问频率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









