







上一章:
JVM-简介&垃圾回收&内存泄漏分析_jmap dump会触发gc吗_做测试的喵酱的博客-CSDN博客
相关文章:
监视器锁(Monitor Lock)_做测试的喵酱的博客-CSDN博客
synchronized&锁_做测试的喵酱的博客-CSDN博客
java多线程&线程与进程区别_做测试的喵酱的博客-CSDN博客
一、哪些问题需要分析堆
场景一:跟内存相关的问题,需要分析堆。如:
-
内存泄漏(Memory Leaks):堆内存泄漏是指在程序中存在无法释放的对象,导致堆内存不断增长。通过分析堆内存可以了解到哪些对象占用较多内存、是否有持续增长的对象等,以找出内存泄漏的根本原因并进行修复。
-
内存溢出(Out of Memory):堆内存溢出是指应用程序在申请内存时,堆空间已满且没有足够的内存供分配。通过分析堆内存可以查看堆的使用情况、对象分配情况,从而定位引发内存溢出的原因。
场景二:tps/rt 随着压测时间的波峰波谷

压测时,响应时间、tps等曲线出现波峰波谷的现象,可能就是GC导致的,在GC时,进程是不能工作的,导致响应时间变长、tps变低,等GC完成后,进程又继续工作,响应时间变短,tps变大。再次gc时,tps又开始变低,响应时间变长。。。
扩展:tps与并发图

A图就是一个正常的,随着并发增加,tps增加,到一定程度后,tps趋于稳定
b图形成原因:
随着并发增加,用户线程/进程太多,每个线程拿到cpu时间片的间隔增大,响应时间增加,会导致进程/线程的被动中断,产生大量的被动中断,导致系统cpu增加,则用户态可使用cpu占比少。
二、 线程 thread
2.1 线程的基本概念
线程是操作系统提供的执行单元,它具有自己的线程标识、上下文环境、优先级等属性。线程可以独立执行,与其他线程并发运行。
扩展:
线程与进程的区别
java多线程&线程与进程区别_做测试的喵酱的博客-CSDN博客
2.2 Java线程6种状态
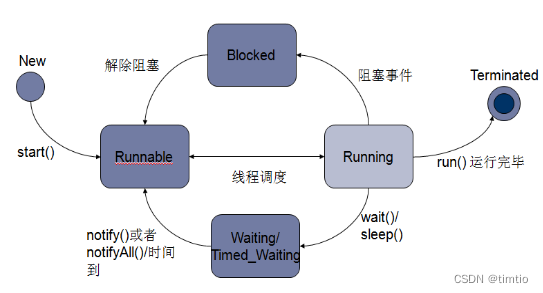
1、新建状态(New):当一个线程对象被创建但尚未调用start()方法时,线程处于新建状态。这个状态我们使用jstack进行线程栈dump的时候基本看不到,此时,线程已经分配了内存空间,但尚未启动执行。
2、就绪状态(Runnable):
新建线程对象后,调用该线程的 start()方法就可以启动线程。当线程启动时,线程进入就绪状态(runnable)。此时,线程可以被CPU调度,并开始执行其任务。
由于还没有分配CPU,线程将进入线程队列排队,等待 CPU 服务,这表明它已经具备了运行条件。
当系统挑选一个等待执行的Thread对象后,它就会从等待执行状态进入执行状态。系统挑选的动作称之为“CPU调度"。一旦获得CPU,线程就进入运行状态并自动调用自己的run方法。
从虚拟机的角度看,线程正在运行状态,状态是线程正在正常运行中, 当然可能会有某种耗时计算/IO等待的操作/CPU时间片切换等, 这个状态下发生的等待一般是其他系统资源, 而不是锁, Sleep等。
处于RUNNABLE状态的线程是不是一定会消耗cpu呢,不一定,像socket IO操作,线程正在从网络上读取数据,尽管线程状态RUNNABLE,但实际上网络io,线程绝大多数时间是被挂起的,只有当数据到达后,线程才会被唤起,挂起发生在本地代码(native)中,虚拟机根本不一致,不像显式的调用sleep和wait方法,虚拟机才能知道线程的真正状态,但在本地代码中的挂起,虚拟机无法知道真正的线程状态,因此一概显示为RUNNABLE。

注意:
Runnable 状态,包含running状态(当就绪状态的线程被调用并获得处理器资源时,线程就进入了运行状态。此时,自动调用该线程对象的 run()方法。)
我们通过RUNNABLE状态,是不能区分出当前的线程正在执行或者等待cpu的调度。就绪状态与运行中状态,统称为RUNNABLE状态/就绪状态。
3、阻塞状态(Blocked):
线程处于阻塞状态,正在等待一个monitor lock(监视器锁)。通常情况下,是因为本线程与其他线程公用了一个锁。其他在线程正在使用这个锁进入某个synchronized同步方法块或者方法,而本线程进入这个同步代码块也需要这个锁,最终导致本线程处于阻塞状态。
扩展:
a、监视器锁的解释
监视器锁(Monitor Lock)_做测试的喵酱的博客-CSDN博客
生活中的小例子:
去银行窗口办理业务,(多个人代表多个线程)一个窗口只能同时处理一个人的业务(线程拿到锁),其他的人(线程)就只能等待锁的释放,处于Blocked状态。

4、等待状态(Waiting):
当线程等待某个特定条件的发生时,它可以进入等待状态。在等待状态下,线程会暂时停止执行,直到接收到其他线程的通知。
这个状态下是指线程拥有了某个锁之后, 调用了他的wait方法, 等待其他线程/锁拥有者调用 notify / notifyAll一遍该线程可以继续下一步操作。
这里要区分 BLOCKED 和 WATING 的区别, 一个是在临界点外面等待进入, 一个是在临界点里面wait等待别人notify, 线程调用了join方法 join了另外的线程的时候, 也会进入WAITING状态, 等待被他join的线程执行结束,处于waiting状态的线程基本不消耗CPU。

举个例子:
银行窗口排队,你拿到了锁,正在办理你的业务。这时突然来了一个V V IP客户,插队了,打断了你的业务办理,先办理他的业务。你进入了WAITING状态。等VIP走后,才继续办理你的业务。
5、计时等待状态(Timed Waiting):
与等待状态类似,但是可以通过设置等待的时间来限制等待的时间段。线程会在指定的时间段内等待,如果超时仍未收到通知,线程将重新进入运行状态。
举个例子:
你是线程T1,你朋友是线程T2,你朋友跟你说11:00的时候,过来跟你借车(锁资源)。
结果你在10:50的时候,把车停下来(释放锁)等待你朋友过来找你。结果到了11:00 你朋友爽约了,他没来。 然后你就继续把车(锁)开走了。
调用了以下方法的线程会进入TIMED_WAITING:
- 1、Thread#sleep()
- 2、Object#wait() 并加了超时参数
- 3、Thread#join() 并加了超时参数
- 3、LockSupport#parkNanos()
- 4、LockSupport#parkUntil()
TIMED_WAITING (parking)实例如下:

从图中可以看出
- “TIMED_WAITING (parking)”中的 timed_waiting 指等待状态,但这里指定了时间,到达指定的时间后自动退出等待状态;parking指线程处于挂起中。
- “waiting on condition”需要与堆栈中的“parking to wait for <0x00000000acd84de8> (a java.util.concurrent.SynchronousQueue$TransferStack)”结合来看。
- 首先,本线程肯定是在等待某个条件的发生,来把自己唤醒。
- 其次,SynchronousQueue 并不是一个队列,只是线程之间移交信息的机制,当我们把一个元素放入到 SynchronousQueue 中时必须有另一个线程正在等待接受移交的任务,因此这就是本线程在等待的条件。
6、终止状态(Terminated):
当线程的任务执行完毕或者发生了意外终止时,线程进入终止状态。一旦线程进入终止状态,它将不会再转换到其他状态。
三、线程栈thread stack
3.1 线程栈(Thread Stack)概念
Thread Stack :线程栈
Stack: 堆栈
线程栈(Thread Stack)简称为堆栈(Stack)
线程与线程栈:
线程栈是线程的一部分,用于存储线程执行过程中的方法调用和局部变量等信息。
线程是操作系统提供的执行单元,它具有自己的线程标识、上下文环境、优先级等属性。线程可以独立执行,与其他线程并发运行。
而线程栈是线程在内存中的一块区域,用于保存线程方法的调用信息。每个线程都有自己的线程栈,用来管理方法的调用顺序和局部变量等数据。
线程栈是线程的私有空间,在多线程程序中保证了线程之间的隔离和独立性。
在 Java 中一个线程就会相应有一个线程栈与之对应,这点很容易理解,因为不同的线程执行逻辑有 所不同,因此需要一个独立的线程栈。
每个线程栈,包含多个栈帧,每个栈帧都有局部变量、动态连接、操作栈、方法返回地址。
线程栈:

每个线程栈,包含多个栈帧,每个栈帧都有局部变量、动态连接、操作栈、方法返回地址。
线程栈(Thread Stack)是每个线程专有的内存区域,用于存储方法调用、局部变量和方法执行期间的状态信息。每当一个新线程被创建时,Java虚拟机(JVM)会为该线程分配一块独立的内存空间,即线程栈。
线程栈以栈(Stack)的数据结构组织数据,采用后进先出(LIFO)的方式。每个栈帧(Stack Frame)代表了一个方法的调用,包含了该方法的参数、局部变量以及方法的返回地址等信息。当方法被调用时,JVM会在线程栈上创建一个新的栈帧,并将其推入栈顶;而方法执行完毕后,栈帧会从栈顶弹出。
线程栈对于线程的执行非常重要。它保存了每个方法的执行上下文,包括方法参数、局部变量和返回值等。线程栈还记录了方法的调用关系,使得程序能够正确地返回到调用点。
线程栈,是虚拟机中线程(包括锁)状态的一个瞬间状态的快照,包括线程的调用堆栈,锁的持有情况。
打印线程栈的信息,一般包含:
1、线程名字,id,线程的数量等。
2、线程的运行状态,锁的状态(锁被哪个线程持有,哪个线程在等待锁等)
3、调用堆栈(即函数的调用层次关系)调用堆栈包含完整的类名,所执行的方法,源代码的行数。
3.2 哪些问题需要分析线程栈:
因为线程栈是瞬时快照包含线程状态以及调用关系,所以借助堆栈信息可以帮助分析很多问题,比如线程死锁,锁争用,死循环,识别耗时操作等等。线程栈是瞬时记录,所以没有历史消息的回溯,一般我们都需要结合程序的日志进行跟踪
1、系统无缘无故的cpu过高
2、系统挂起,无响应
3、系统运行越来越慢
4、性能瓶颈(如无法充分利用cpu等)
5、线程死锁,死循环等
6、由于线程数量太多导致的内存溢出(如无法创建线程等)
四、jstack命令
java是多线程,一个进程下,包含多个线程。
Java虚拟机提供了线程转储(thread dump)的后门,通过这个后门可以把线程堆栈打印出来。通常我们将堆栈信息重定向到一个文件中,便于我们分析,由于信息量太大,很可能超出控制台缓冲区的最大行数限制造成信息丢失。
jstack是jdk自带的打印线程栈的工具,jstack用于打印出给定的Java进程ID或core file或远程调试服务的Java堆栈信息。
jstack命令用于查看Java进程中的线程信息和堆栈跟踪。实际上,jstack主要是用来查看Java进程中各个线程的状态、堆栈信息、锁信息等。
使用jstack命令时,它会连接到指定的Java进程,并收集每个线程的信息。这些信息包括每个线程的ID、名称、优先级、状态以及线程调用栈的信息。通过分析线程的堆栈信息,您可以了解到线程在执行过程中经过的方法调用路径,以及当前线程被阻塞的原因。
因此,尽管jstack命令是在查看Java进程中线程的信息,但实际上它是通过操作系统提供的接口获取线程信息,并将其与Java进程进行关联。通过这种方式,您可以查看到Java进程中各个线程的详细信息。
jstack 打印线程栈,线程栈是一个瞬间状态的快照,程序一直在运行,所以每个时刻的瞬间状态的快照是变化的。我们使用jstack查看的信息,也是线程栈那一瞬间的数据。
所以分析的时候,我们需要多次使用jsatck命令,这样才能看到一个大概的连续过程。
4.1 jstack 打印线程栈
[root@ecs-39233 ~]# jstack
Usage:
jstack [-l][-e] <pid>
(to connect to running process)
Options:
-l long listing. Prints additional information about locks
-e extended listing. Prints additional information about threads
-? -h --help -help to print this help message
You have new mail in /var/spool/mail/root常用命令:
#后面直接跟pid,查看正在运行的进程,基本上用的这个命令
jstack pid >文件pid为进程号
举例:
查找java/tomcat进程的pid
ps -ef|grep tomcat收集栈数据,
jstack 8766一般数据会比较多,我们可以把这个数据收集到一个文件里。
jstack 8766 >stack.logstack.log里面就是线程栈。实际运行中,往往一次dump的信息,还不足以确认问题,建议产生三次dump信息,如果每次dump都指向同一个问题,我们才确定问题的典型性。
4.2 分析线程栈数据
4.2.1 举例
java程序
public class Main {
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
while (true) {
System.out.println("Thread 1 is running");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread1.start();
Thread thread2 = new Thread(() -> {
while (true) {
System.out.println("Thread 2 is running");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread2.start();
Thread.sleep(5000);
thread2.join();
}
}
该程序创建了两个线程,分别打印 "Thread 1 is running" 和 "Thread 2 is running" 的消息。主线程等待 5 秒后,会等待 thread2 的执行完毕。
现在,我们可以使用 jstack 命令来获取线程栈信息。首先,我们运行程序并记下主线程的 ID(PID)。
然后,在终端中执行以下命令(假设 PID 为 12345):
jstack 12345 > stack.txt
这将把线程栈信息保存到名为 stack.txt 的文件中。
接下来,我们打开 stack.txt 文件,可以看到类似以下的线程栈信息:
"Thread-1" #12 prio=5 os_prio=0 tid=0x000000001bba2800 nid=0x344 waiting on condition [0x000000001c35f000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at Main.lambda$main$0(Main.java:8)
...(省略部分信息)...
"Thread-2" #13 prio=5 os_prio=0 tid=0x000000001bba3800 nid=0x302 waiting on condition [0x000000001c45f000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at Main.lambda$main$1(Main.java:19)
...(省略部分信息)...
"main" #1 prio=5 os_prio=0 tid=0x000000000241b800 nid=0x3bb0 waiting on condition [0x000000000249e000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at Main.main(Main.java:29)
...(省略部分信息)...
解析线程栈信息时,我们关注以下几点:
- 线程名称:在引号内的字符串,例如 "Thread-1"、"Thread-2" 和 "main"。
- 线程状态:位于 java.lang.Thread.State 行后面的状态信息,如 "TIMED_WAITING (sleeping)"。
- 方法调用路径:从 "at" 开始,指示方法调用路径。例如,"at Main.lambda$main$0(Main.java:8)" 表示在 Main 类的第8行的 lambda 表达式中调用。
通过分析线程栈信息,我们可以了解各个线程的状态和当前所处的方法调用路径。这对于定位死锁、长时间阻塞、性能问题等非常有帮助,并可以指导后续的问题排查与优化工作。
4.2.2 编写示例程序
java脚本模拟服务器内存溢出&服务器部署java项目_java模拟内存溢出_做测试的喵酱的博客-CSDN博客
1、方案
1、打包成war包,可以直接将war包部署在tomcat容器里
2、spring boot,打包成jar包。打的jar包,内置了tomcat,所以在服务器上,直接启jar包就行,没有必要放在tomcat容器里部署,在启动jar包时,可以配置线程池等。
这里用 spring boot,打包成jar。
2、新建 项目
java 选择8

勾选spring web

修改pom.xml文件,把Spring boot 版本,改成2.4.4
(啊,为啥用2.4.4 呢,因为我用习惯了) 
3 编写项目

package com.example.analyzestack.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class MyTest {
Object obj1 = new Object();
Object obj2 = new Object();
public void fun1() {
synchronized (obj1) {
fun2();
}
}
public void fun2() {
synchronized (obj2) {
while (true) { //为了打印堆栈,该函数堆栈分析不退出
System.out.print(">>>>>>>>>>>");
}
}
}
@RequestMapping("/OOM")
public String ping(){
MyTest aa = new MyTest();
aa.fun1();
return "stack分析";
}
}配置端口号,8084

4 打jar包

(如果之前,大过,要先cleam清理一下)
jar包在target目录下

5 部署服务在服务器启动该jar包
1、先将jar包上传到服务器。
rz2、启动jar包
nohup java -jar service.jar > server.log 2>&1 &
格式:
nohup java -jar -Dspring.profiles.active=prod 包名.jar --server.port=80 &如:
nohup java -jar -Dspring.profiles.active=prod testOOM-0.0.1-SNAPSHOT.jar &我们这里指定这个jvm的堆内存,最大最小内存都是5m,这样容易压到内存溢出。
nohup java -jar -Dspring.profiles.active=prod -Xms256m -Xmx256m testOOM-0.0.1-SNAPSHOT.jar &使用浏览器访问:
部署项目:
nohup java -jar -Dspring.profiles.active=prod -Xms256m -Xmx256m AnalyzeStack-0.0.1-SNAPSHOT.jar &
14044 就是进程号
使用top命令,查看服务器状态

cpu us 被打满了。14044 是我们刚刚启动的java进程,消耗了少量cpu
kswapd0 消耗了大量的cpu
kswapd0 是一个Linux操作系统中的内核线程。它是负责虚拟内存交换(swap)子系统的一部分。当系统的内存不足以容纳所有正在执行的进程时,kswapd0 将被激活来管理交换空间。
kswapd0 的主要任务是将不再活跃或很少使用的内存页面移出物理内存,并将其写入交换空间(通常是硬盘上的交换文件)。这样可以释放物理内存以供其他活跃的进程使用。
kswapd0 在后台运行,并且具有自动管理交换空间的功能。它监视系统的内存使用情况,并在需要时调整交换内存的使用,以确保系统的正常运行。通过这种方式,kswapd0 帮助操作系统维持合理的内存使用和系统性能。
请注意,kswapd0 是一个内核线程,它在内核级别运行,并不直接对用户可见。在一般情况下,您不需要主动干预或操作 kswapd0 程序。
4.2.2 分析线程栈
使用jmeter压测接口
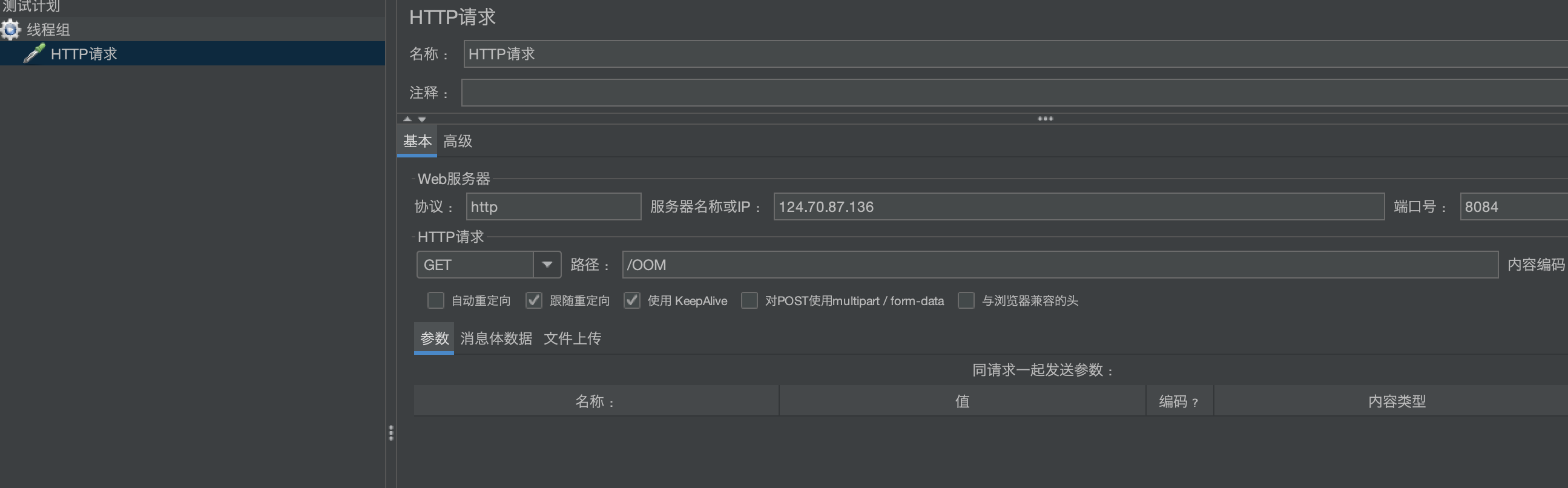
jstack 14044 >stack.log上一章节:















 1352
1352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











