







一、Spring注入类型
Spring 核心功能之一依赖注入,依赖注入是使用 Spring 框架的基本手段,通过他获取各种类型的 bean,但使用不同的依赖注入类型时经常会遇到循环依赖的问题。Spring 依赖注入类型:
- 字段注入,这是最常用的方式,使用简单方便。但它确是 3 种方式中应该避免的,可能导致潜在的循环依赖。Spring 官方也不推荐使用这种方式,而是推荐构造器注入。
- 构造器注入
- Setter 方法注入,这种方式可以解决循环依赖
二、创建 Bean 过程
首先看下 Spring 创建 bean 的过程
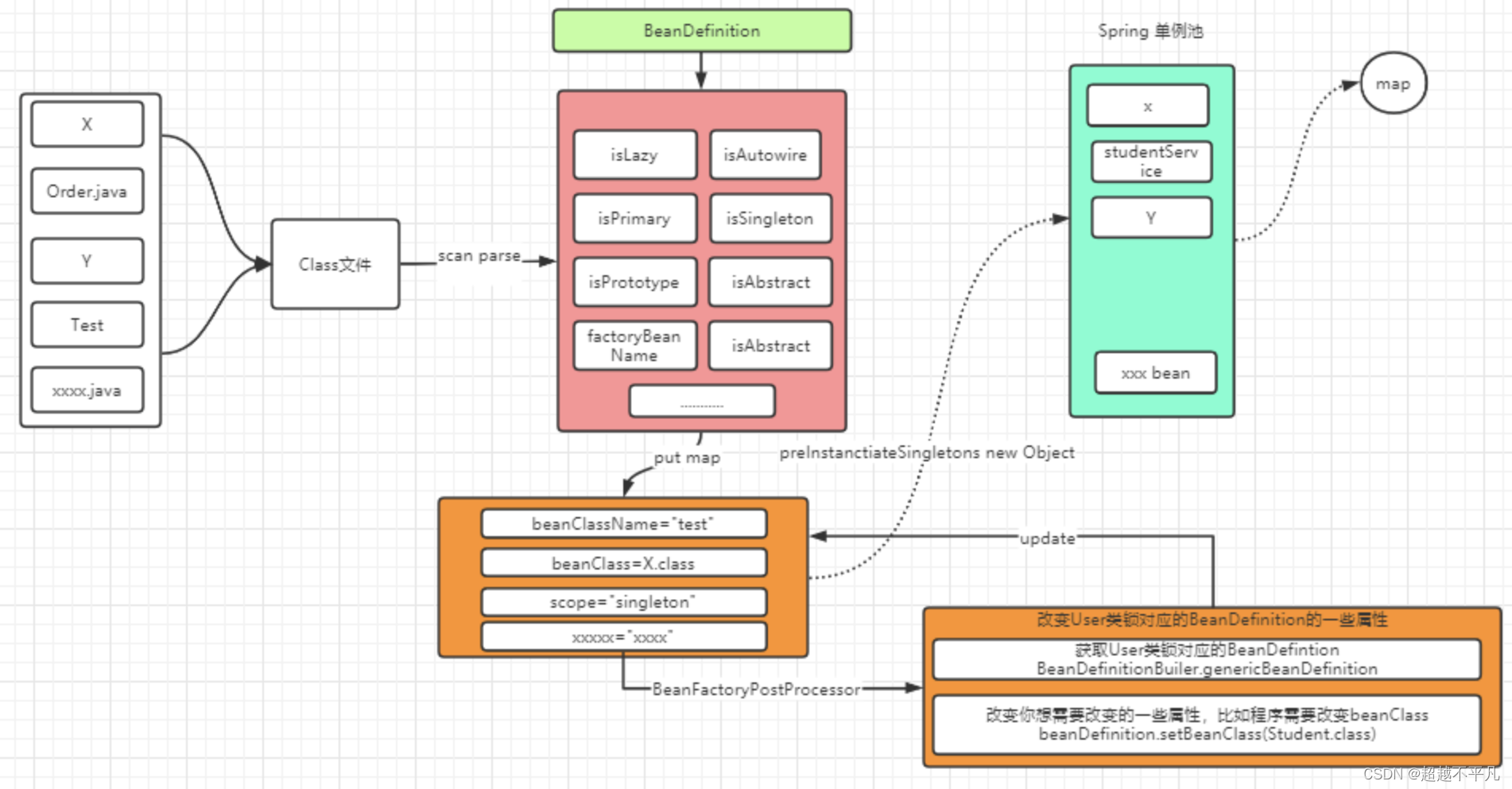
Spring 获取到 Class 文件后并没有直接创建对象,而是先获取对象的信息,将对象的信息保存到 BeanDefinition 中,BeanDefinition 中包含了诸多信息,比如是否懒加载、单例或者多例、是否抽象、是否为 Primary 等等属性,更多详细属性可参考源码。定义好后将这些信息保存到 map 中,这时还需要判断是否需要对用户的 Bean 进行扩展,有有扩展需求,需要对 map 中的对象进行 update。
对象实例后被保存到了缓存中,实际上就是被保存到了 map 里,单例模式下需要获取时直接从缓存中获取,如下图:

三、循环依赖
在 Spring 框架这样的依赖注入(Dependency Injection,DI)框架中,循环依赖指的是两个或多个对象之间相互依赖,形成一个闭环结构,即 A 对象依赖于 B 对象,B 对象又反过来依赖于A 对象,或者通过一系列间接依赖构成闭合的依赖链条。
那Spring是如何解决循环依赖的呢?下面我们分析一下。
首先需要确认一个问题,Spring是允许循环依赖,在在源码中也有所体现。
/** Whether to automatically try to resolve circular references between beans. */
private boolean allowCircularReferences = true;在源码中有这样一个属性,allowCircularReferences 的默认值为 true,也就是说,Spring自身的设计上是允许循环依赖的。
为了解决循环依赖,Spring 引入了三级缓存,第一级缓存用来持有完整的 Bean 实例,也就是上文提到的单例模式下的缓存;第二级缓存中存放的是提前暴露的对象,已经创建还未完成属性注入;第三级缓存用来存放工厂对象。

@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// singletonObjects 为一级缓存
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// earlySingletonObjects 为二级缓存
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// singletonFactories 为三级缓存
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}获取对象的流程,首先是从一级缓存中获取对象,如果获取不到再从二级缓存中获取,如果还是获取不到,则从三级缓存中获取对象工厂,然后通过工厂获取,获取成功后就把对象从三级缓存移动到二级缓存,从而为下一次对象获取做准备。
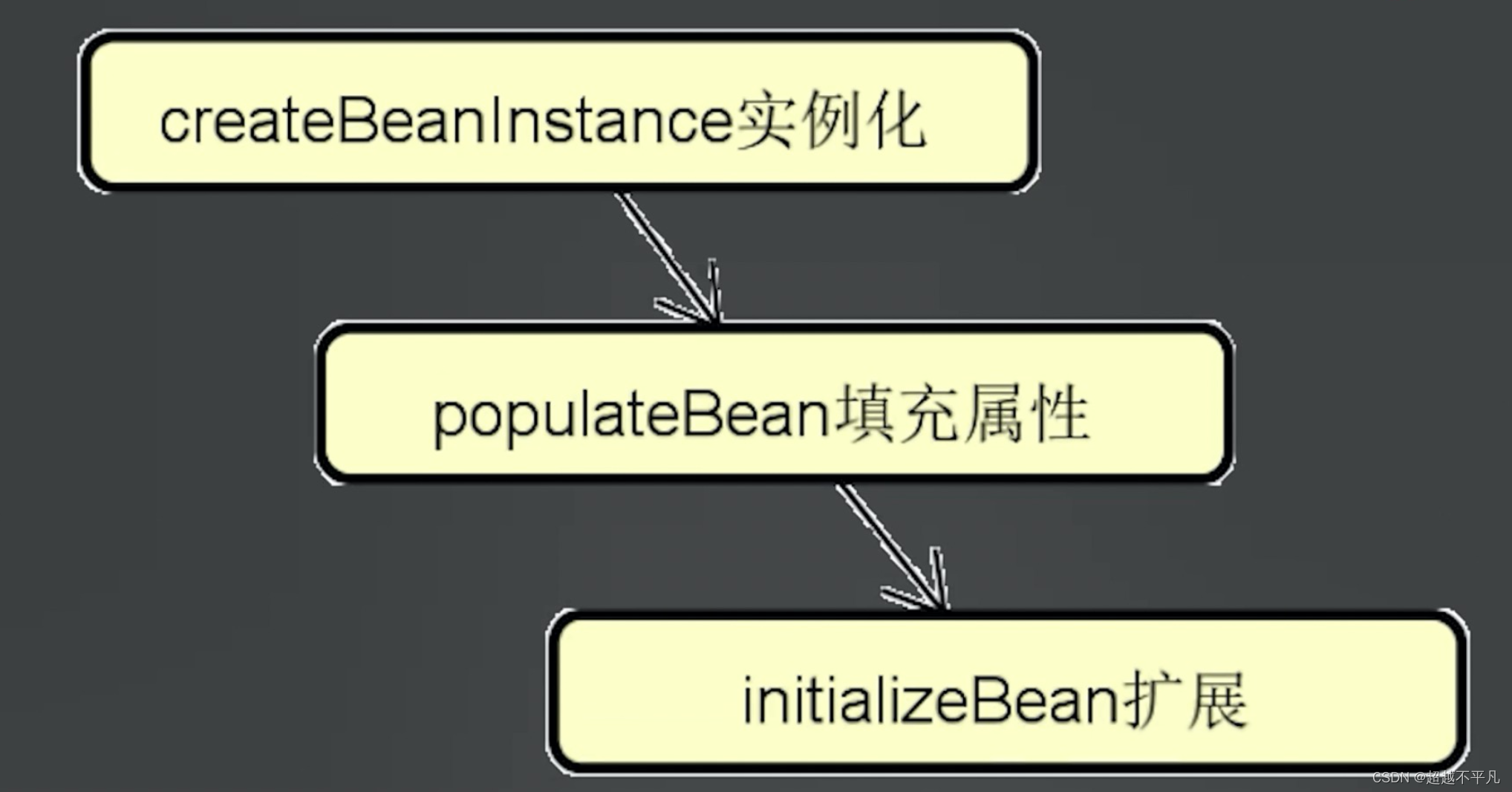
解决循环依赖的关键是点还是在 Bean 的生命周期上,通过 @Autowire 注入 Bean 时是在doCreateBean() 方法中完成创建的,这个方法包括三个核心步骤,首先通过 createBeanInstance 实例化 bean,然后通过 populateBean() 方法实现属性注入,最后通过initializeBean() 对 bean 进行扩展。第一步完成了 bean 的初始化,第二步完成了 bean 的完成实例化。
3.1 循环依赖解决分析 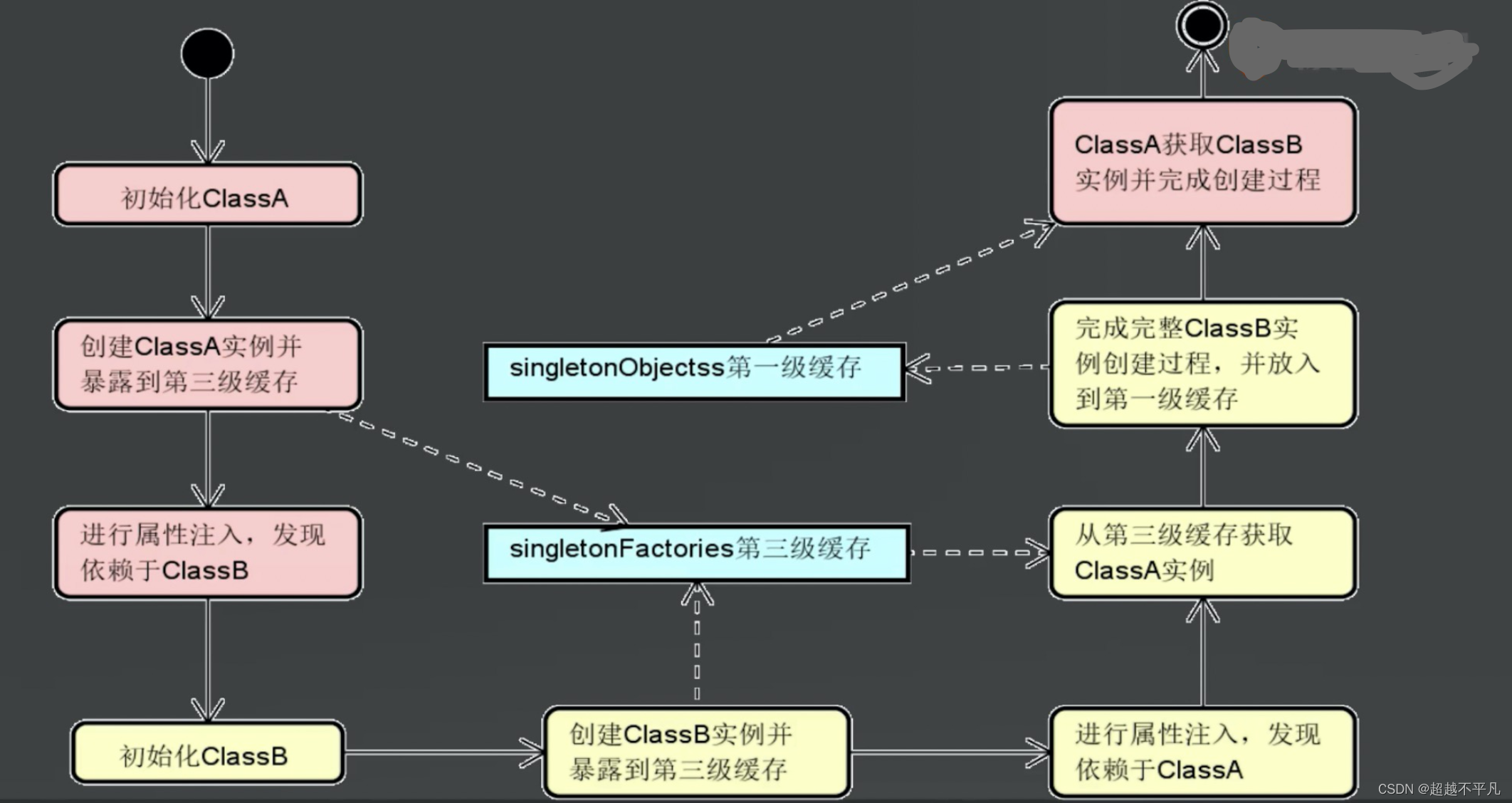
假设先初始化 ClassA,在通过 createBeanInstance 方法创建了实例,并将这个实例提前暴露到三级缓存中,然后 ClassA 通过 populateBean 方法进行属性注入,发现自己依赖 ClassB,就会尝试获取 ClassB 实例,显然 ClassB 还没有被创建,所以走创建流程,ClassB 在初始化的第一个流程发现自己依赖 ClassA,就会尝试从第一级缓存获取 ClassA 实例,因为 ClassA 还没有完全创建完毕,所以一级缓存不存在,同样二级缓存中也不存在,当尝试访问第三级缓存时,ClassA 已经提前暴露出去了,所以 ClassB 能从三级缓存中获取到 ClassA 对象并顺利完成所有初始化流程,ClassB 创建完成后,会把自己放到一级缓存中,这时 ClassA 就能从一级缓存中获取到 ClassB,进而完成 ClassA 的初始化。
到这里应该能理解构造器无法解决循环依赖了吧。因为构造器注入发生在创建bean的第一个步骤,而这个步骤还没有完成三级缓存的构建,自然无法获取到目标对象。
总结来说,循环依赖是一种不利于软件设计和维护的关系,因为它可能导致初始化顺序混乱、资源占用过多等问题,因此在设计和编码时应尽量避免。在 Spring 框架中,虽然对 setter 注入的循环依赖进行了某种程度的支持,但仍建议遵循良好的设计原则,例如依赖倒置原则和单一职责原则,以减少循环依赖的可能性。
往期经典推荐
SpringBoot项目并发处理大揭秘,你知道它到底能应对多少请求洪峰?_springboot并发处理-CSDN博客
一文看懂Nacos如何实现高效、动态的配置中心管理-CSDN博客
跨越微服务边界:Spring Cloud Sleuth 如何助力实现无缝分布式追踪-CSDN博客
















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











