







目录
一、简介
Kubernetes 是一个开源的容器编排系统,用于自动化应用容器的部署、扩展和管理。它是Google基于Borg系统(Google的内部运行系统)的经验并贡献给 Cloud Native Computing Foundation(CNCF)的项目。Kubernetes 中间有8个字母,所以也被称为 K8s。
K8s 有如下的特性
- 服务发现和负载均衡:K8s 可以使用 DNS 名称或自己的 IP 地址暴露容器,如果到一个容器的流量过大,K8s 能够负载均衡并分配网络流量,以保证服务稳定。
- 自动部署和回滚:你可以描述已部署的容器应有的状态,它可以改变实际状态到期望状态。
- 自我修复:当容器失败时,K8s 会重启它;当节点失败时,K8s 会重新调度在该节点上的应用到其他节点上;当容器没有响应健康检查时,K8s 会杀掉它并且把它标记为失败的。
K8s 介于应用服务和服务器之间,能够通过策略,协调和管理多个应用服务,只需要一个 yaml 文件位置,定义应用的部署顺序等信息,就能自动部署应用到各个服务器上,还能让它们挂了自动重启,自动扩缩容。
二、Kubernetes 架构原理
K8s 会将我们的服务器划分成两部分,一部分为控制平面,另一部分为工作节点,也就是 Node。控制平面控制和管理各个 Node,而 Node 则负责实际运行各个应用服务。
2.1 控制平面
控制平面内部组件
- 以前操作服务器时需要登录每台服务器,然后手动执行各种命令,现在有了 K8s 一切都变得简单了,K8s 提供了 API 接口,然后通过 API server 接口组件就能操作这些服务资源。
- 以前部署服务时,需要查看哪台服务器的资源充足,然后才能将应用部署到相应的服务器上,现在 K8s 提供了调度器(Scheduler)来完成这些操作。在选择最合适节点时,Scheduler 会考虑多种因素,例如节点的资源剩余情况(CPU、内存等)、Pod的资源需求、数据亲和性、节点的标签等。选择完节点后,Scheduler 会将决定通知给 API server,然后 API server 会将 Pod 信息和节点信息记录下来。
- 找到服务器后,以前我们会手动创建、关闭服务,K8s 提供了 Controller Manager 控制器来负责做这些事情。
- K8s 在运行过程中会产生一些数据,这些数据需要存储起来,目前数据被存放到了 etcd 中。
下图为控制平面组件组成图

2.2 Node 组件
Node 是实际的工作节点,他可以是一台物理机,也可以是虚拟机。Node 会实际去运行应用服务,多个应用服务可以共享一台 Node 上的 CPU、内存等资源。如果是非核心业务,部署到一起是没问题的,如果是核心服务最后进行隔离,分开部署。每个应用服务都会占用一定的 CPU 、内存、存储和网络资源,如果部署在一起会发生资源争抢,核心服务应该进行隔离步数。
另一方面也会影响可用性,如果一个 Node 上部署很多重用的应用服务,那么这个节点如果出现故障,可能会影响很多服务。而且这种方式不利于管理,增加了复杂性。
2.3 Container Image
以前我们部署服务时,需要上传代码到服务器上,而用了 K8s 之后,只需要将服务代码打包成容器镜像(Container Image),就能将它部署。
容器镜像是由文件系统和参数组成的轻量级、独立的、可执行的软件包,包含了运行某个软件所需的所有内容,包括代码、运行时环境、库、环境变量和配置文件等。容器镜像可以再不同的环境中重复的创建相同的容器,这使得打包、分发、部署和运行变得异常简单和快速。
每个应用服务都可以被看做是一个容器,并且大多情况下,还会为应用服务添加一个日志收集器,多个容器组成一个个的 Pod,它们运行在 Node 上。
K8s 可以将 pod 从某个 Node 调度到另外一个 Node,还能以 Pod 为单位去做重启和动态扩缩容操作,所以 Pod 是 k8s 中最小的调度单位。
2.4 kubelet
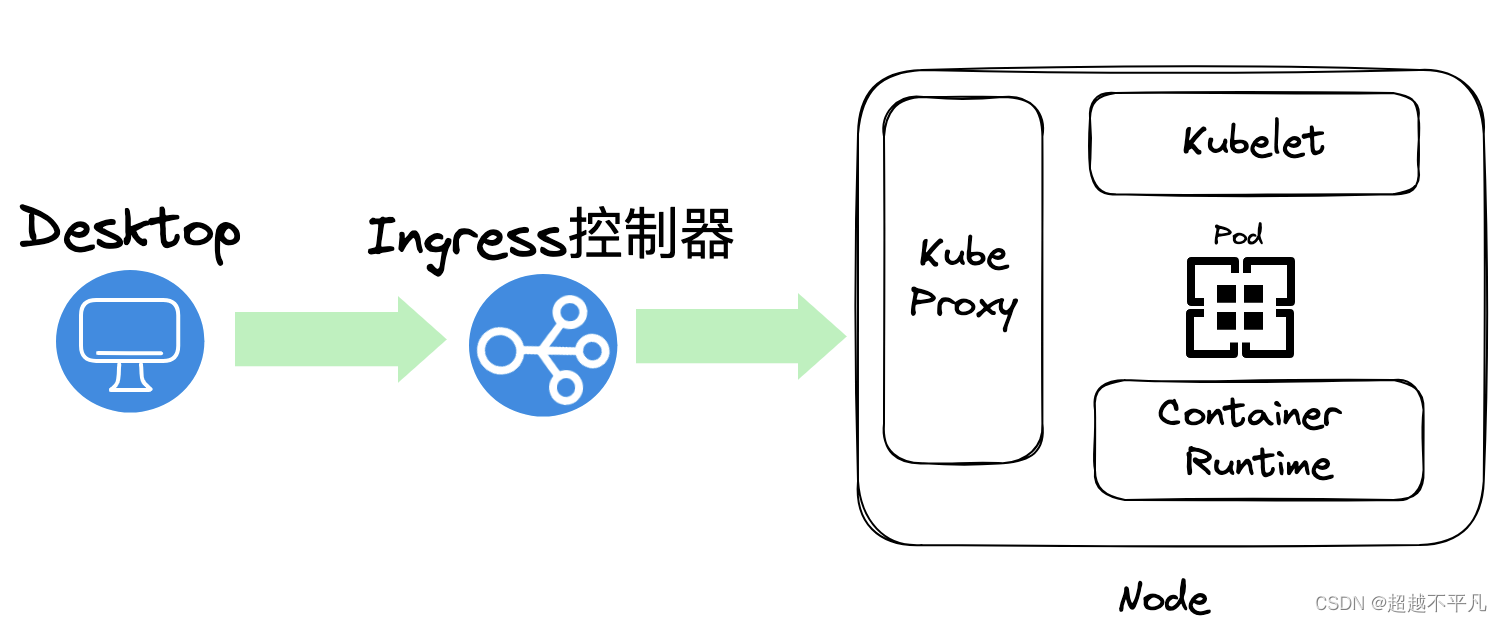
另外,前面提到控制平面会用 Controller Manager (通过 API Server)控制 Node 创建和关闭服务,那 Node 也得有个组件能接收到这个命令才能去做这些动作,这个组件叫 kubelet,它主要负责管理和监控 Pod。 最后,Node 中还有个 Kube Proxy ,它负责 Node 的网络通信功能,有了它,外部请求就能被转发到 Pod 内。 
2.5 Cluster
控制平面和 Node 共同组成一个 Cluster,也就是集群。同时,为了将集群内部的服务暴露给外部用户使用,我们一般还会部署一个入口控制器,比如 Ingress 控制器(比如 Nginx) ,它可以提供一个入口让外部用户访问集群内部服务。
三、服务调用
外部请求会先进入 K8s 集群的 Ingress 控制器,然后请求会被转发到 K8s 内部的某个 Node 的 Kube Proxy 上,再找到对应的 Pod,然后才是转发到内部容器服务中,处理结果原路返回。
四、总结
这篇文章只是简单的减少了 K8s 的工作原理,作为业务程序员,公司内部有封装好的服务管理平台,平时可能也没接触过这些东西,但是还是需要了解一下,这有助于大家了解整个服务的运作。
由于是初学者,欢迎指教更正。
往期经典推荐
Kafka VS RabbitMQ,架构师教你如何选择_消息中间件选型分析-CSDN博客















 1651
1651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











