







写在前面
-
官网经典图的简单介绍
下面是我在jdk8官网上截的一张图,这张图充分的说明了JDK、JRE、JVM三者之间的关系,可以到JDK所在的位置是超级包含了JRE,而JRE又包含了JVM,同时能看出来JDK为开发者提供了很多的工具供开发者使用,JRE为我们提供了很多的类库提供了运行的支撑,JVM是我们的代码能运行在各操作系统上的支撑。

-
要怎么学习?
现在我所停留的阶段是在JDK层面,即使用层面,那如何走进JVM呢?,我想我还是应该再我最熟悉的领域开始,然后一步一步走到最深处。
1 java文件到class文件
- 我们先准备一个java文件
public class Test {
private String name;
private static int a=0;
public void test(){
Test test=new Test();
test.setName("明心");
System.out.println(test);
}
public static void main(String[] args) {
new Test().test();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Test{" +
"name='" + name + '\'' +
'}';
}
}
- 执行命令javac Test.java,会得到Test.class文件
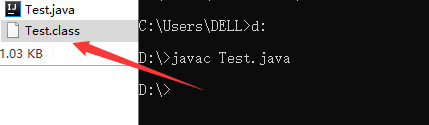
用sublime编辑器打开后,对比官网网上的解释,我们其实也能看的懂这个class文件了

由此我们可以大胆推测,假如我用别的语言来写一个文件,然后编译器编译出来后的开头是cafe babe那其实也是可以运行在jvm上的。
2 class文件到虚拟机(类加载机制)
类加载机制是面试中经常遇到的一道面试题,在我之前的印象中只知道四个字,那便是:双亲委派,那么到底什么是双亲委派呢,其中又包含了什么呢?
2.1类加载过程
- 装载(Load)
其实这一步还是很容易理解的,无非就是将class文件在磁盘中找到,然后拷贝到JVM中,在此过程中,经历了大概下面三个步骤
(1)通过一个类的全名获取定义此类的二进制字节流
(2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
(3)在Java堆中生成一个代表这个类的对象,作为对方法区中这些数据的访问入口 - 链接(Link)
(1)验证:确保类加载的正确性(对文件的格式、数据、符号引用等进行验证)
(2)准备:为静态变量分配内存,并初始化默认值(也就是说,如果有一个变量为:static int a=10,那么此刻会开辟内存空间并复值为a=0)
(3)解析:把符号引用转为直接引用(即现在我要把引用地址指向真正开辟出来的内存地址) - 初始化(Initialize)
类中的静态变量,静态代码块执行初始化操作(也就是在第2步中的a=0,现在要真正的赋值为a=10了)
2.2 类装载器ClassLoader
在装载阶段需要借助类装载器来完成:
- 首先我们看源码的实现

- 简单图解

这就是经典的那道双亲委派机制的答案了,通俗理解就是:类加载的顺序是从Custon ClassLoader —>Application ClassLoader—>Exension ClassLoader—>Bootstrap ClassLoader从下往上加载,如果Bootstrap ClassLoade中存在这个类那就会使用Bootstrap ClassLoade中的类而不会使用Custon ClassLoader中的,依次递归直至完成,那么此刻就自然可以想到如果我要破坏双亲委派那么只需要重写loadClass方法即可。
03 运行时数据区(Run-Time Data Areas)
class文件通过类加载器进入到JVM中,那么就需要了解一下JVM的大致构成是如何的。

- 方法区(Method Area)
方法区是各个线程共享的内存区域,在虚拟机启动时创建。
用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却又一个别名叫做Non-Heap(非堆),目的是与Java堆区分开来。
当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。
特别说明:
Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池,用于存放编译时期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。 - 堆(heap)
Java堆是Java虚拟机所管理内存中最大的一块,在虚拟机启动时创建,被所有线程共享。Java对象实例以及数组都在堆上分配。
到此刻,类加载器的所有操作(装在、连接、初始化)都已经完成,那么我要执行一个方法那这个方法又会如何运行呢?所以虚拟机栈应运而生。 - 虚拟机栈(java virtual Machine Stacks)
虚拟机栈是一个线程执行的区域,保存着一个线程中方法的调用状态。换句话说,一个Java线程的运行状态,由一个虚拟机栈来保存,所以虚拟机栈肯定是线程私有的,独有的,随着线程的创建而创建。
每一个被线程执行的方法,为该栈中的栈帧,即每个方法对应一个栈帧。
调用一个方法,就会向栈中压入一个栈帧;一个方法调用完成,就会把该栈帧从栈中弹出。
那么此刻又会出现一个问题:线程中的内容是否能够拥有执行权,是根据CPU调度来的。
假如线程A正在执行到某个地方,突然失去了CPU的执行权,切换到线程B了,然后当线程A再获得CPU执行权的时候,怎么能继续执行呢?这就是需要在线程中维护一个变量,记录线程执行到的位置(即:程序计数器)。 - 程序计数器(The pc Register)
程序计数器占用的内存空间很小,由于Java虚拟机的多线程是通过线程轮流切换,并分配处理器执行时间的方式来实现的,在任意时刻,一个处理器只会执行一条线程中的指令。因此,为了线程切换后能够恢复到正确的执行位置,每条线程需要有一个独立的程序计数器(线程私有)。
如果线程正在执行Java方法,则计数器记录的是正在执行的虚拟机字节码指令的地址;
如果正在执行的是Native方法,则这个计数器为空。 - 本地方法栈(Native Method Stacks)
如果当前线程执行的方法是Native类型的,这些方法就会在本地方法栈中执行。















 659
659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









