







除了运行 Appium 的基本条件外,还要一个日志输出库
安装: pip install loguru
思路分析
首先我们观察一下整个 app5 的交互流程,其首页分条显示了电影数据, 每个电影条目都包括封面,标题, 类别和评分 4 个内容, 点击一个电影条目, 就可以看到这个电影的详细介绍,包括标题,类别,上映时间,评分,时长,电影简介等内容

可见详情页远比首页内容丰富, 我们需要依次点击每个电影条目,抓取看到的所有内容,把所有电影条目的信息都抓取下来后回退到首页
另外,首页一开始只显示 10 个电影条目,需要上拉才能显示更多数据,一共 100 条数据,所以为了爬取所有数据,我们需要在适当的时候模拟手机上拉的操作,已加载更多的数据
综上,这里总结出基本爬取流程
遍历现有的电影条目,依次模拟点击每个电影条目,进入详情页
爬取详情页的数据,爬取完毕后模拟点击回退按钮的操作,返回首页
当首页的所有电影条目即将爬取完毕时,模拟上拉操作,加载更多数据
在爬取过程中,将已经爬取的数据记录下来,以免重复爬取
100 条数据爬取完毕后,终止爬取
基本实现
在编写代码的过程中,我们用 Appium 观察现有的 App 的源代码,以便编写节点的提取规则。 首先启动 Appium 服务,然后启动 Session , 打开电脑端的调试窗口
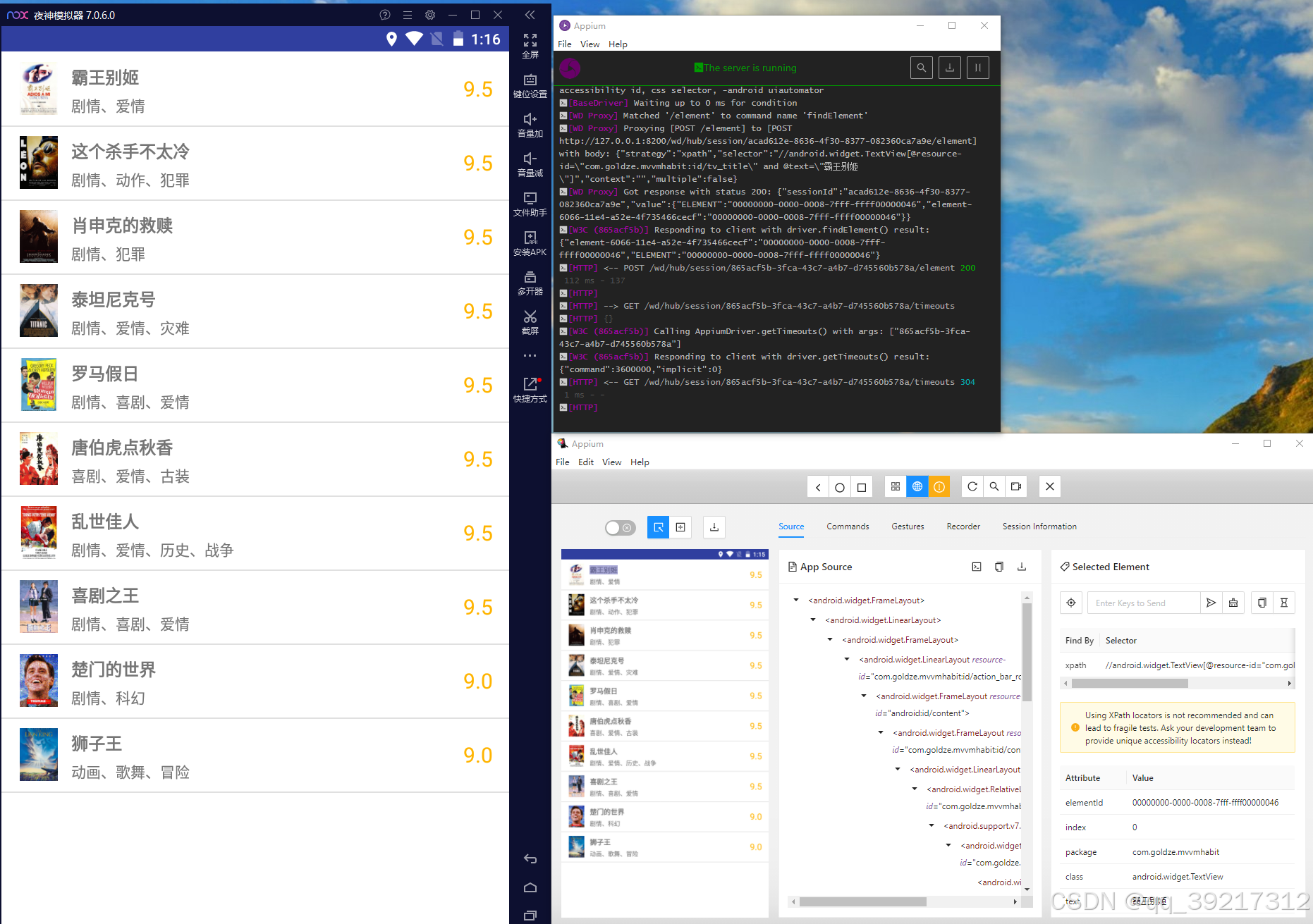
首先观察一些首页各个电影条目对应的 UI 树是怎样的。 通过观察可以发现,每个电影条目都是一个 android.widget.LinearLayout 节点, 该节点带有一个属性 resoutce-id 为 com.goldze.mvvmhabit:id/item , 条目内部的标题是一个 android.widget.TextView 节点,该节点带有一个属性 resource-id , 属性值是 com.goldze.mvvmhabit:id/tv_title, 我们可以选中所有的电影条目节点,同时记录电影标题去重
去重的目的: 因为对已经被渲染出来但是没有呈现在屏幕上的节点,我们是无法获取其信息的。在不断上拉爬取的过程中,我们同一时刻只能获取屏幕中能看到的所有电影条目的节点,被滑动出屏幕外的节点已经获取不到了。所有需要记录一下已经爬取的电影条目节点,以便下次滑动完毕后可以接着上一次爬取。由于此案例中的电影标题不存在重复,因此我们就用它来实现记录和去重
接下来做一些初始化声明
from appium import webdriver
from appium.options.android import UiAutomator2Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import NoSuchElementException
SERVER = 'http://localhost:4723/wd/hub'
DESIRED_CAPABILITIES = {
'platformName': 'Android',
'deviceName': 'LIO_AN00',
'appPackage': 'com.goldze.mvvmhabit',
'appActivity': '.ui.MainActivity',
'noReset': True
}
PACKAGE_NAME = DESIRED_CAPABILITIES['appPackage']
TOTAL_NUMBER = 100
这里我们首先声明了 SERVER 变量, 即 Appium 在本地启动的服务地址。 接着声明了 DESITED_CAPABILITIES , 这就是 Appium 启动示例 App 的配置参数,其中 deviceName 需要更改成自己手机的 model 名称, 可以使用 adb devices –l 通过 cmd 获取。另外,这里额外声明了一个变量 PACKAGE_NAME 即包名, 这是为后续编写获取节点的逻辑准备的。 最后声明 TOTAL_NUMBER 为 100 , 代表电影条目的总数为 100 , 之后以此为判断终止爬取
接下来我么声明 driver 对象, 并初始化一些必要的对象和变量
driver = webdriver.Remote(SERVER, options=UiAutomator2Options().load_capabilities(DESIRED_CAPA
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3672
3672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









