







ETCD集群运维
ETCD扩容节点
节点1:10.1.1.10
etcd --name infra0 --initial-advertise-peer-urls http://10.1.1.10:2380 \
--listen-peer-urls http://10.1.1.10:2380 \
--listen-client-urls http://10.1.1.10:2379,http://127.0.0.1:2379\
--advertise-client-urls http://10.1.1.10:2379 \
--initial-cluster-token etcd-cluster-1 \
--initial-cluster infra0=http://10.1.1.10:2380,infra1=http://10.1.1.11:2379,infra2=http://10.1.1.12:2379\
--initial-cluster-state new
节点2:10.1.1.11
etcd --name infra1 --initial-advertise-peer-urls http://10.1.1.11:2380 \
--listen-peer-urls http://10.1.1.11:2380 \
--listen-client-urls http://10.1.1.11:2379,http://127.0.0.1:2379\
--advertise-client-urls http://10.1.1.11:2379 \
--initial-cluster-token etcd-cluster-1 \
--initial-cluster infra0=http://10.1.1.10:2380,infra1=http://10.1.1.11:2379,infra2=http://10.1.1.12:2379\
--initial-cluster-state new
节点3:10.1.1.12
etcd --name infra2 --initial-advertise-peer-urls http://10.1.1.12:2380 \
--listen-peer-urls http://10.1.1.12:2380 \
--listen-client-urls http://10.1.1.12:2379,http://127.0.0.1:2379\
--advertise-client-urls http://10.1.1.12:2379 \
--initial-cluster-token etcd-cluster-1 \
--initial-cluster infra0=http://10.1.1.10:2380,infra1=http://10.1.1.11:2379,infra2=http://10.1.1.12:2379\
--initial-cluster-state new
在以上的任意一个节点
查看集群健康状态
etcdctl cluster-health
查看集群状态
etcdctl member list
运行时重配置,通知集群新的配置
etcdctl member add http://10.1.1.13:2380
启动:
区别:--initial-cluster 的值,--initial-cluster-state为existing
节点4:10.1.1.13
etcd --name infra2 --initial-advertise-peer-urls http://10.1.1.13:2380 \
--listen-peer-urls http://10.1.1.13:2380 \
--listen-client-urls http://10.1.1.13:2379,http://127.0.0.1:2379\
--advertise-client-urls http://10.1.1.13:2379 \
--initial-cluster-token etcd-cluster-1 \
--initial-cluster
infra0=http://10.1.1.10:2380,infra1=http://10.1.1.11:2379,infra2=http://10.1.1.12:2379,infra4=http://10.1.1.13:2379 \
--initial-cluster-state existing
ETCD参数调优
etcd默认配置在本地网络下通常能够运行的很好,因为延时很低。然而在跨数据中心部署etcd或网络延时很高时,etcd的心跳间隔和选举超时时间等参数需要根据实际情况进行调整。
网络并不是导致延时的唯一来源,不论Follower还是Leader,请求和响应都受磁盘I/O延时影响。
时间参数
心跳间隔:主节点通知从节点它还是Leader的频率,该参数应该设置成节点之间RTT的时间,默认是100ms。
选举超时时间:从节点等待多久没收到主节点的心跳就尝试去竞选Leader,默认是1000ms
心跳间隔建议设置为临近节点间RTT的最大值,通常0.5~1.5倍的RTT,如果心跳间隔设置太短,etcd就会发送没有必要的心跳,增加CPU和网络资源消耗;如果设置太大,导致选举等待时间的超时。
选举等待时间设置的过长,会导致节点异常检查时间过长。
(评估RTT的最简单方法是使用ping操作)
选举超时时间应该基于心跳间隔和节点之间的平均RTT值,必须至少是RTT的10倍时间以应对网络波动。
选举超时时间的上限是50000ms,这个时间只能适用于全球范围内分布式部署的etcd集群。
心跳间隔和选举超时时间的值对同一个etcd集群的所有节点都生效,如果各个节点不同的话,就会导致集群发生不可预知的不稳定性,可以通过启动参数或者环境变量覆盖默认值,
etcd --heartbeat-interval=100 --election-timeout=500
快照
etcd总是向日志文件中追加key的改动,这样会导致key的的改动日志文件会线性增长。
快照提供一种通过保护系统的当前状态并移除旧日志文件的方式来压缩日志文件。
默认修改数量达到10000时才会建立快照,如果etcd的内存使用和磁盘使用过高,应该尝试调低快照触发的阈值
etcd --snapshot-count=5000
磁盘
etcd集群对于磁盘I/O的延时非常敏感,因为etcd必须持久化它的日志,当其他IO密集型的进行也在占用磁盘IO的带宽时,会导致fsync延时非常高。这将导致etcd丢失心跳包,请求超时或暂时性的Leader丢失。
etcd服务器赋予更高的磁盘IO,可以使用SSD高性能盘
网络
如果etcd的主节点要处理大规模并发的客户端请求,有可能因为网络拥塞的原因延迟对从节点的响应。
监控
etcd服务端会在客户端端口的metrics路径上暴露metrics数据,可以时间监控。
curl -L http://localhost:2379/metrics
维护
如下的所有运维管理都是在操作etcd的存储空间,存储空间的配额用于控制etcd数据空间的大小,如果etcd的节点磁盘空间不足了,配额会触发告警,然后etcd系统将进入操作受限的维护模式。为了避免存储空间消耗完导致写不进去,应该定期清理key的历史版本。在清理etcd节点存储碎片后,存储空间会重新调整。定期对etcd节点状态做快照备份,以便在错误的运维操作引起数据丢失或数据不一致时进行数据恢复。
压缩历史版本
启动参数,设置自动压缩key的历史版本,以小时以为单位,如下表示保留1小时的历史版本
etcd -auto-compaction-retention=1
使用压缩命令,压缩至版本号3
etcdctl compact 3
在压缩之后,版本号3之前的key版本都变得不可用,可以如下命令查看
etcdctl get --rev=2 somekey
消除碎片化
压缩历史版本后,后台数据库将存在内部的碎片,这些碎片无法被后台存储使用,却占用节点存储空间,
因此需要消除碎片化,释放这些存储空间。
[root@VM-12-8-opencloudos ~]# etcdctl defrag
Finished defragmenting etcd member[127.0.0.1:2379]
存储配额
如果设置了存储配额,当一个节点的存储空间超过配额,etcd就会触发集群范围的告警,并将集群置于只读key和删除key的维护模式,
设置16M的存储配额
etcd --quota-backend-bytes=$((16*1024*1024))
默认值为
2 * 1024 * 1024 * 1024
查看告警是否出发
etcdctl alarm list
快照备份
定期为etcd节点做快照,以便容灾恢复
etcdctl snapshot save backup.db
灾难恢复
etcd自己被设计有一定的容灾能力,对于一个N节点的集群,允许最多出现(N-1)/2个节点发生永久性故障之后还能正常对外服务,当超过(N-1)/2时,就会陷入不可逆地失去仲裁的境地。一旦仲裁丢失,集群机会无法保证一致性,因此无法再接收到更新请求了。
为了从灾难性故障中恢复,提供了快照和恢复机制来重建一个新的etcd集群。
快照
etcdctl --endpoints=$ENDPOINT snapshot save snapshot.db
恢复
恢复到新集群,例如恢复到新集群(m1,m2,m3),以m1为例:
为m1节点创建新的etcd数据目录
etcdctl snapshot restore snapshot.db \
--name m1 \
--initial-cluster m1=http://m1:2380,m2=http://m2:2380,m3=http://m3:2380 \
--initial-cluster-token etcd-cluster-test \
--initial-advertise-peer-urls http://m1:2380
启动etcd进程
etcd \
--name m1 \
--listen-client-urls http://m1:2379 \
--advertise-client-urls http://m1:2379 \
--initial-advertise-peer-urls http://m1:2380
etcd gateway
etcd网关是一个简单的TCP代理,可用于向etcd集群转发网络数据,etcd网关对用户透明且无状态的,不会修改客户端请求和响应
作用
访问etcd的每个应用需要获取到etcd集群的客户端短点地址,但是如果集群重配置发生变化,应用程序需要同步更新,否则会影响应用程序的可用性。
etcd网关监听一个固定的本地地址,每个应用程序都与它的本地etcd网关相连,这样只有etcd网关需要更新其后端服务器列表,对应用来说,后端服务器端的更新是透明的。
什么时候不应该使用网关
- 性能:etcd网关并不是为提升etcd性能而设计的,不提供缓存,watch合并,批处理等提升性能的特性,高性能场景下并不推荐使用etcd网关
- 已有服务发现机制:集群管理系统本身支持服务发现,通过DNS域名或集群的LB的IP
启动方式
etcd gateway start --endpoints=http://10.1.1.1:2379,http://10.1.1.2:2379,http://10.1.1.3:2379
gRPC代理
gRPC代理是一个运行在gRPC层(L7),无状态的etcd反向代理,它被设计成一个降低核心etcd集群的请求负载,对于横向扩展,gRPC代理会合并watch以及为API请求绑定一个过期租约。还可以保护集群免受大流量的冲击,缓存range request的结果。
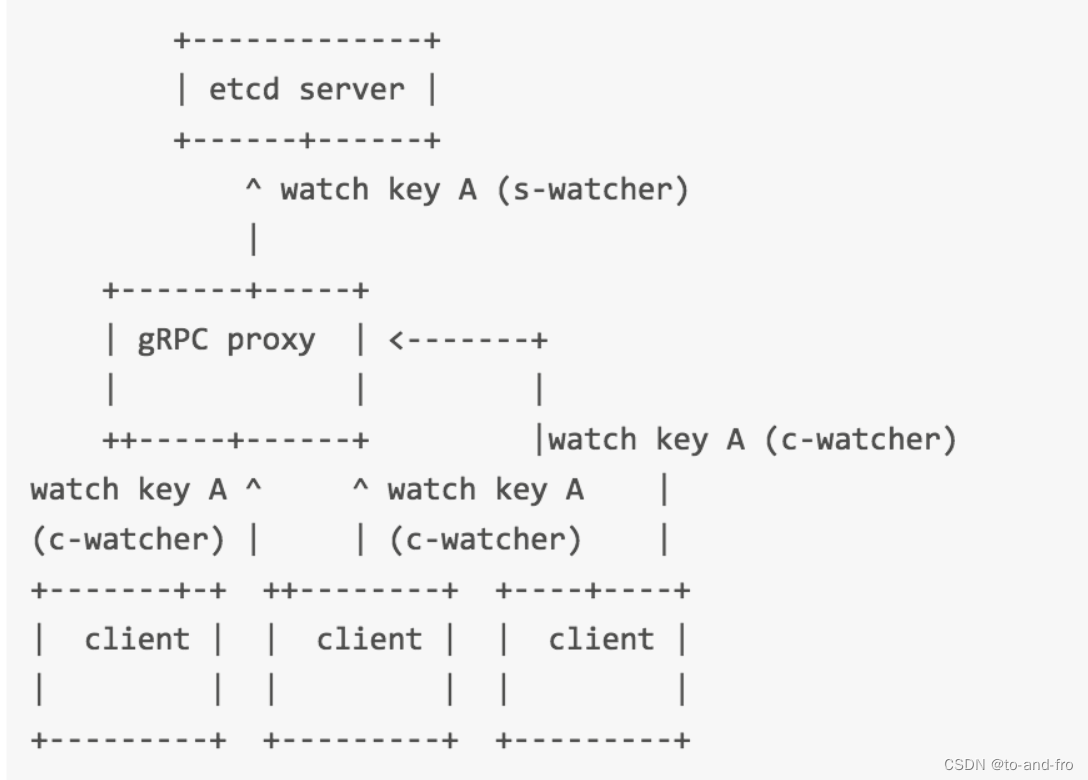
可扩展的watch API
它可以将多个客户端(c-watchers)对同一个key的监控合并到一个链接(s-watcher)到 etcd server的请求。同时它会广播从s-watcher收到的时间到所有的c-watchers。
租约
lease API支持续约机制,客户端通过定时刷新(heartbean)来实现续约(v2和v3的实现机制也不一样)。用于集群监控以及服务注册发现。
跟上图类似,为了减少etcd server的交互次数,gRPC proxy同样提供了合并功能

3个client注册到gRPC proxy中(c-stream),通过心跳(heartbeat)来定时续约,gRPC proxy会合并生成一个s-stream 注册到etcd server
请求缓存
gRPC proxy会缓存来自客户端的请求,保证etcd server 频繁的被客户端请求滥用
启动gRPC代理
etcdctl grpc-proxy start --endpoints=http://10.1.1.1:2379,http://10.1.1.2:2379,http://10.1.1.3:2379 --listen-addr=1.1.1.1:2379















 2964
2964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









